卷积神经网络结构优化综述
参考文献格式
[1]林景栋,吴欣怡,柴毅,尹宏鹏.卷积神经网络结构优化综述[J/OL].自动化学报:1-14[2019-08-21].https://doi.org/10.16383/j.aas.c180275.
专业关键词
- 结构优化(structure optimization)
- 网络剪枝(network pruning)
- 张量分解(tensor factorization)
- 知识迁移(knowledge transferring)
1. 网路剪枝与稀疏化
参考文献: Network trimming: a data-driven neuron pruning approach towards efficient deep architectures 卷积神经网络从卷积层到全连接层存在大量的冗余参数,当参数趋近于0的时候可以进行参数裁剪,剔除掉不重 要的连接、节点甚至卷积核,以达到精简网络结构的目的.好处如下:
- 有效缓解了过拟合现象的发生
- 稀疏网络在以 CSR (Compressed sparse row format, CSR) 和 CSC (Compressed sparse column format)等稀疏矩阵存储格式存储于计算机中可大幅降低内存开销。
- 训练参数的减少使得网络训练阶段和预测阶段花费时间更少。
主要方法:
- 训练中稀疏约束
- Collins等在参数空间中通过贪婪搜索决定需要稀疏化的隐含层(Memory bounded deep convolutional networks)
- 迭代硬阈值 (Iter-ative hard thresholding, IHT)(Training skinny deep
neural networks with iterative hard thresholding methods):
- 第一步中剔除隐含节点间权值较小的连接 , 然后微调 (Fine-tune) 其他重要的卷积核.
- 第二步中激活断掉的连接,重新训练整个网络以获取更有用的特征
- 前向–后向切分法(Forward-backward splitting method)([19]):
- 结构化稀疏学习(Structured sparsity learning, SSL)([20]):接学习到的硬件友好型稀疏网络不仅具有更加紧凑的结构 , 而且运行速度可提升 3 倍至 5 倍.
- 以分组形式剪枝卷积核输入,以数据驱动的方式获取最优感受野 (Receptive field)([21])
- 利用一系列优化措施将不可微分的 l 0 范数正则项加入到目标函数 ,学习到的稀疏网络不仅具有良好的泛化性能 , 而且极大加速了模型训练和推导过程。([22])
- Dropout 作为一种强有力的网络优化方法 , 可被视为特殊的正则化方法 , 被广泛用于防止网络训练过拟合[23-24]
- 自适应 Dropout:根据特征和神经元的分布使用不同的多项式采样方式 , 其收敛速度相对于标准Dropout 提高 50 %.[25]
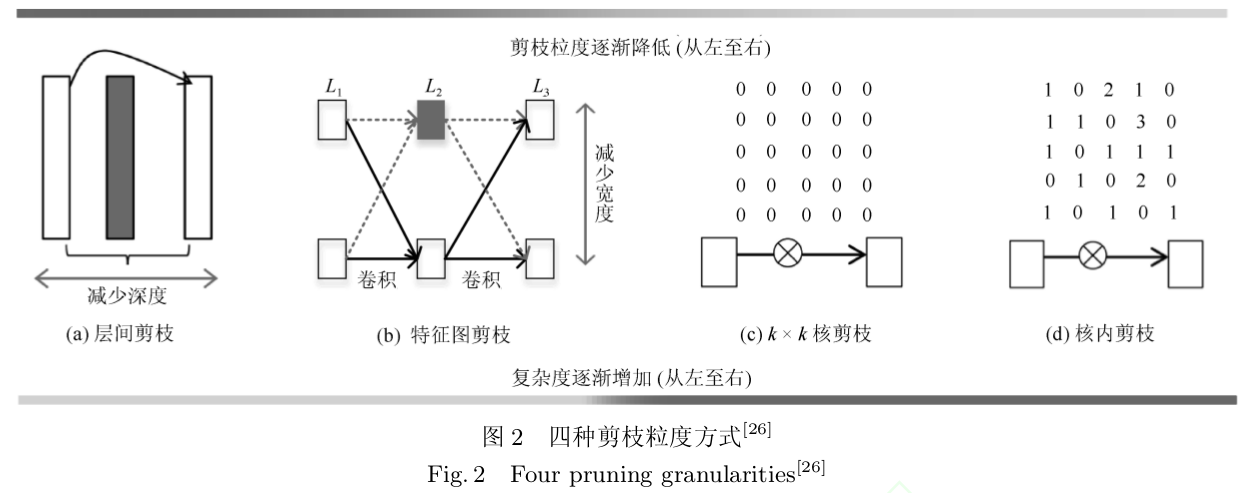
- 训练后剪枝:从已有模型入手,消除网络中的冗余信息。由剪枝粒度不同划分如下[26]:
- 层间剪枝:减少网络深度
- 特征图剪枝:减少网络宽度
- kxk核剪枝:减少网络参数,提升网络性能;
-
核内剪枝:提升模型性能
- 最优脑损伤(Optimal brain damage, OBD)[8]:通过移除网络中不重要的连接 ,在网络复杂度和训练误差之间达到一种最优平衡状态 , 极大加快了网络的训练过程.
- 最优脑手术 (Optimal brain sur-geon, OBS)[9]:损失函数中的 Hessian 矩阵没有约束,这使得 OBS 在其他网络中具有比 OBD 更普遍的泛化能力。上述两种方法都面临者严重的网络精度损失。
- 深度压缩 (Deep compression)[28]:综合应用了剪枝、量化、编码等方法 , 在不影响精度的前提下可压缩网络 35 ∼ 49 倍 , 使得深度卷积网络移植到移动设备上成为可能。
- 针对全连接层进行剪枝操作,摆脱了对于训练数据的依赖[29]。
- 动态网络手术 (Dynamic network surgery)[30]:在剪枝过程中添加了修复操作,可以重新激活重要的操作。交替进行,极大的改变了网络学习效率
- ReLU 激活函数移至 Winograd域 , 然后对 Winograd 变换之后的权重进行剪枝[31]。
- LASSO 正则化剔除冗余卷积核与其对应的特征图 , 然后重构剩余网络 , 对于多分支网络也有很好的效果。[32]
- 去除对于输出精度影响较小的卷积核以及对应的特征图[33]:
- 一次性 (One-shot) 优化方法:可获得60%∼70%的稀疏度[26]:
- ThiNet[34]:在训练和预测阶段同时压缩并加速卷积神经网络,从下一卷积层而非当前卷积层的概率信息获取卷积核的重要程度 , 并决定是否剪枝当前卷积核 , 对于紧凑型网络也有不错的压缩效果。
2. 张量分解
神经网络的主要计算量,来自于卷积层。网络仅仅需要很少一部分参数就可以进行准确的预测[35];卷积核是四维张量。将原始张量分解为若干低秩张量,减少卷积操作数目。
常见的张量分解方法有:
- CP分解:
- Tucker分解:将卷积分解为一个核张量与若干因子矩阵。是一种高阶的主成分分析方法。
- 矩阵奇异值分解 (Singular value decomposition, SVD)常用于全连接层分解:
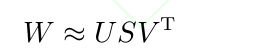
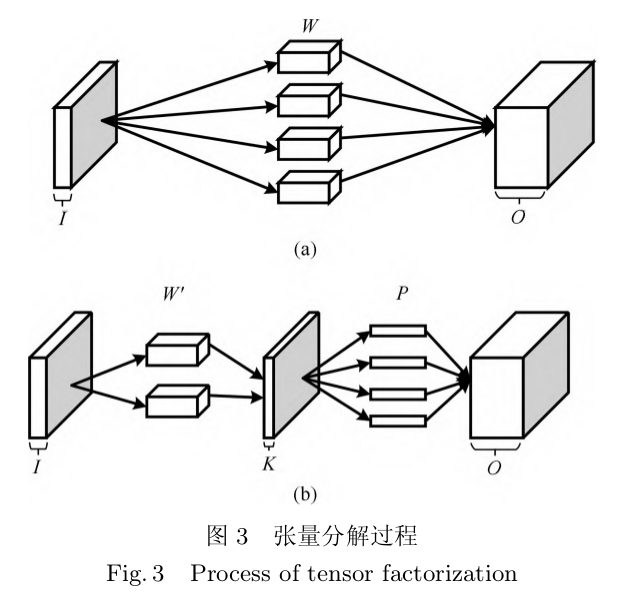
图 3 (a)中W为原始张量数据维度为:(d,d,i,o);复杂度为O(d^2io);进行b中的张量分解后复杂度为O(ok)+O(d^2k*i);大大降低了复杂度,复杂度降低为原来的(o/k),k越小压缩效果越明显。
张量的典型引用是将高维离散余弦变换(Discrete cosine transform, DCT)分解为一系列一维DCT变换。
卷积的张量分解方法:
- 分离卷积核学习方法 (Learning separable filters)[36]:能够将原始卷积核用低秩卷积核表示,减少所需卷积核数量以降低计算负担。
- 逐层分解方法[37]:每当一个卷积核被分解为若干一阶张量则固定此卷积核并基于一种重构误差标准以微调其余卷积核。在场景文本识别中可加速网络4.5倍
- 全连接层奇异值分解[38]:全连接层进行展开奇异值分解,可以大大减少网可以参数,并提升网络速度。
- 基于cp分解的卷积核张量分解方法[39]:用最小二乘法,将卷积核进行分解为四个一阶卷积核张量。并且表明张量分解具有正则化效果。
- 约束的张量分解新算法[40]:将非凸优化的张量分解转,化为凸优化问题 , 与同类方法相比提速明显。
- 非对称张量分解方法[41]:加速整体网络运行。
网络整体压缩
- 基于PCA累积能量的低秩选择方法和具有非先行的重构误差优化方法[41]:
- 基于变分贝叶斯的低秩选择方法和基于 Tucker 张量分解的整体压缩方法[42]:尺寸和运行时间都大大降低。
- 利用循环矩阵剔除特征图中的冗余信息,获取特征图中最本质的特征[43],减少参数但是性能不减少
- 等提出了一种基于优化CP分解全部卷积层的网络压缩方法[44]:克服了由于PC分解带来的网络精度下降问题。
张量分解过后都需要重新训练网络至收敛,进一步加剧了网络训练的复杂度。
3. 知识迁移
知识迁移是属于迁移学习的一种网络结构优化方法 , 即将教师网络 (Teacher networks) 的相关领域知识迁移到学生网络 (Student networks)以指导学生网络的训练。
教师网络拥有良好的性能和泛化能力,学生网络拥有更好的针对性和性能
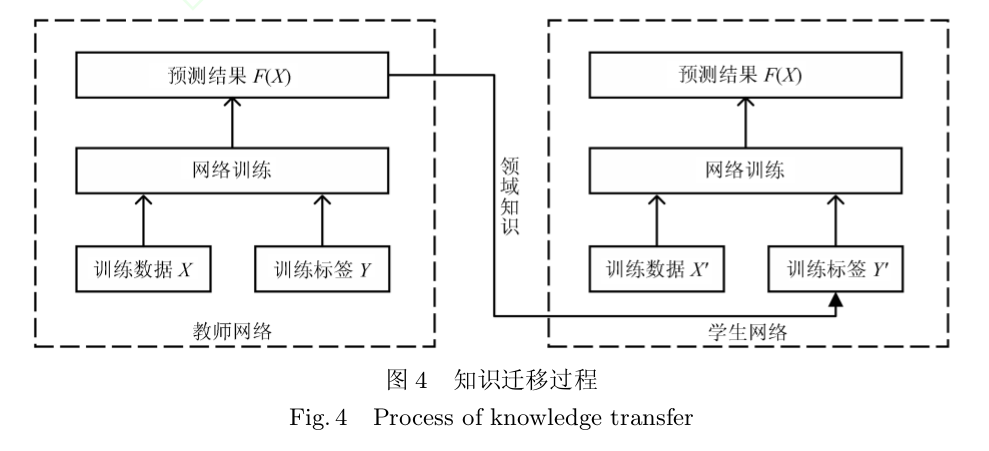
注释迁移主要由教师网络获取和学生网络训练两部分构成。
- 教师网络:主要要求准确率
-
学生网络:少数数据的快速训练
- 基于知识迁移的模型压缩方法[45]:
- 利用 logits ( 通过 softmax 函数前的输入值 , 均值为 0) 来表示学习到的知识[46]:
- 知识精馏(Knowledge distilling, KD)[47]:采用合适的 T 值 , 可以产生一个类别概率分布较缓和的输出(称为软概率标签(Soft probability labels)).
- FitNet[48]:
- Net2Net[50]:基于函数保留变换 (Function-preserving transfor-mation)可以快速地将教师网络的有用信息迁移到更深 ( 或更宽 ) 的学生网络
- 于注意力的知识迁移方法[51]:从低、中、高三个层次进行注意力迁移;极大改善了残差网络等深度卷积神经网络的性能
- 结合 Fisher 剪枝与知识迁移的优化方法[52]: 利用显著性图训练网络并利用 Fisher 剪枝方法剔除冗余的特征图 , 在图像显著度预测中可加速网络运行多达 10 倍。
- 知识迁移的端到端的多目标检测框架[54]:解决了目标检测任务中存在的欠拟合问题 , 在精度与速度方面都有较大改善。
知识迁移方法能够直接加速网络运行而不需要较高硬件要求,大幅降低了学生网络学习到不重要信息的比例 , 是一种有效的网络结构优化方法 . 然而知识迁移需要研究者确定学生网络的具体结构,对研究者的水平提出了较高的要求。此外,目前的知识迁移方法仅仅将网络输出概率值作为一种领域知识进行迁移,没有考虑到教师网络结构对学生网络结构的影响。提取教师网络的内部结构知识 ( 如神经元 ) 并指导学生网络的训练,有可能使学生网络获得更高的性能。
4. 精细模块设计
通过对高效精细化模块的构造,可以实现优化网络结构的目的,采用模块化的网络结构优化方法,网络的设计与构造流程大幅缩短。目前就有代表性的精细模块有:Inception模块、网中网、残差模块
4.1 Inception模块
4.1.1 Inception-v1
Szegedy [4. 等从网中网 (Net-work in network, NiN) [55. 中得到启发,提出了如图所示的 Inception-v1 网络结构:
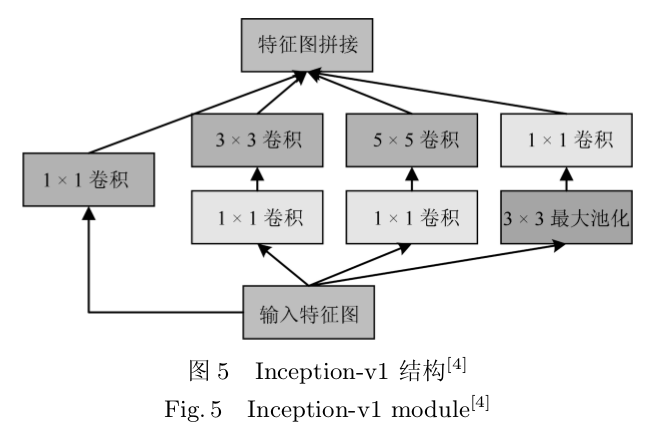
将不同尺寸的卷积核并行连接能够增加特征提取的多样性;而引入的 1 × 1 卷积核则加速了网络运行过程。
4.1.2 Inception-v2
因为卷积神经网络在训练时,每层网络的输入分布都会发生改变,会导致模型训练速度降低。因此使用批标准化(Batch normalization BN)。主要用于解决激活函数之前,作用是解决梯度问题[56]。
4.1.3 Inception-v3[57]
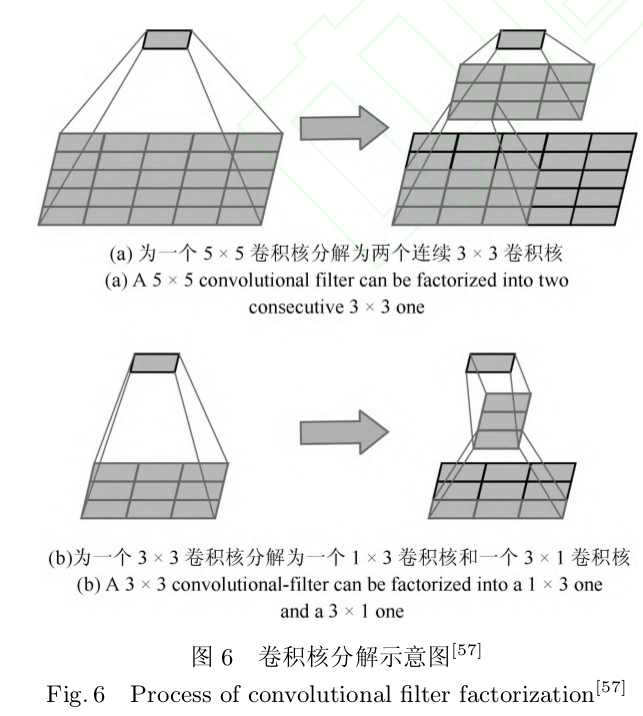
除了将 7 × 7 、 5 × 5 等较大的卷积核分解为若干连续的 3 × 3 卷积核 , 还将 n × n 卷积核非对称分解为 1 × n 和 n × 1 两个连续卷积核 ( 当 n = 7 时效果最好 ).
nception 结构与残差结构相结合 , 发现了残差结构可以极大地加快网络的训练速度[58]:
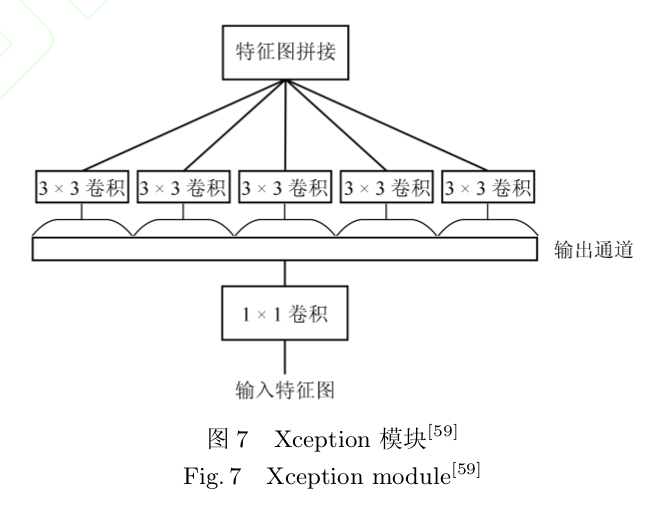
Xception[59]:用卷积核对输入特征图进行卷积操作.
4.2 网中网(Network in network)
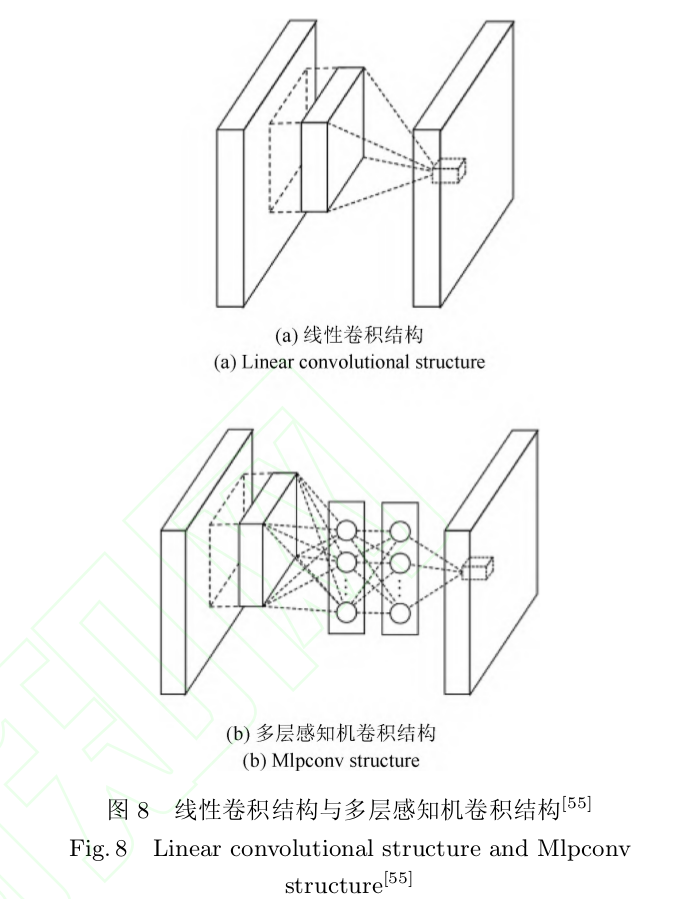
Mlpcover[55]:即在卷积核后面添加一个多层感知机,(Multilayer perceptron, MLP)由于多层感知机能够拟合任何函数 , 因此 Mlpconv 结构增强了网络对局部感知野的特征辨识能力和非线性表达能力。
Maxout network in network(MIN)[56]:用Maxout替代ReLU解决梯度消失问题。之后[57]使用稀疏连MLP并使用分离卷积(Unshared convolution)空间维度上使用共享卷积。即卷积中的卷积 (Convolution in convolution, CiC)。
MPNIN(Mlpconv-wise supervised pretraining network in network)[62]:通过监督式预处理方法初始化网络模型的各层训练参数 , 并结合批标准化与网中网结构能够训练更深层次的卷积神经网络。
Mlpconv 结构引入了额外的多层感知机,有可能会导致网络运行速度降低,对此进行改善将会是未来研究的一个方向.
4.3 残差模块
随着卷积神经网络逐渐向更深层次发展 , 网络将面临退化问题而不是过拟合问题 , 具体表现在网络性能不再随着深度的增加而提升 , 甚至在网络深度进一步增加的情况下性能反而快速下降。
- LSTM(Long short-term memory)[64]:用来解决这个问题,旁路连接的引入,突破了深度在达到 40 层时网络将面临退化问题的限制,进一步促进了网络深度的增加[65]。
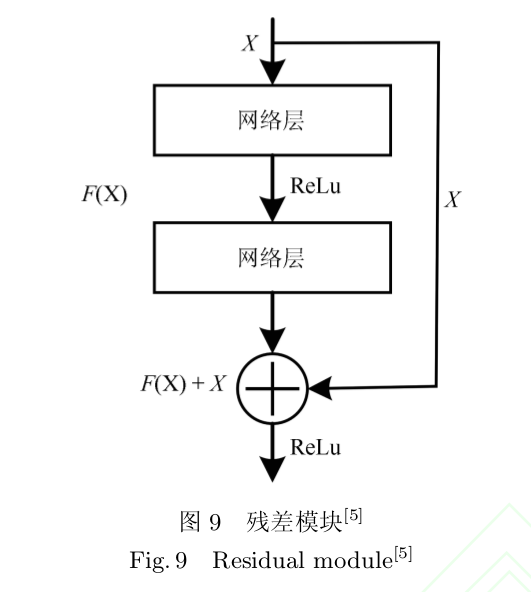
- 残差网络(Residual network,ResNet):残差网络的门限机制不再是可学习的 , 也即始终保持信息畅通状态 , 这极大地降低了网络复杂度 , 加速了网络训练过程 , 同时突破了由网络退化引起的深度限制。
 。
。
之后残差模块使得网络深度进一步加深,但是后面发现,深度并不能很好的进行参数和特征的学习,有人认为练超过50层的网络是毫无必要的[69].因此接下来的网络逐渐向宽度进行靠拢。通过增加宽度对其进行更改。
4.4 其它精细模块
- 全均值池化(Global average pooling, GAP)[55]:代替全连接层,相当于在整个网络结构上做正则化防止过拟合。
- 密集模块 (Dense block):在任何两层网络之间都有直接连接[74]:改善了网络中信息与梯度的流动,对于网络具有正则化的作用。
- 跨连卷积神经网络[75]:允许第二个池化层跨过两层直接与全连接层相连接。
- MobileNet 将传统卷积过程分解为深度可分离卷积 (Depthwise convolution)和逐点卷积 (Pointwise convolution) 两步[77]
- 反向残差模块 (Inverted residual with linear bottleneck)[78]:等将残差模块与深度可分离卷积相结合。
- ShuffleNet[79]:等在MobileNet 的基础上进一步提出了基于逐点群卷积(Pointwise group convolution) 和通道混洗 (Channel shuffle).
5 总结
主要研究方向:
- 网络剪枝与稀疏化():
稳定地优化并调整网络结构,目前大多数的方法是剔除网络中冗余的连接或神经元 , 这种低层级的剪枝具有非结构化 (Non-structural) 风险 ,在计算机运行过程中的非正则化 (Irregular) 内存存取方式反而会阻碍网络进一步加速.一些特殊的软硬件措施能够缓解这一问题,然而会给模型的部署另一方面,尽管一些针对卷积核和卷积图的结构化剪枝方法能够获得硬件友好型网络,在 CPU和GPU上速度提升明显,但由于剪枝卷积核和卷积通道会严重影响下一隐含层的输入,有可 能存在网络精度损失严重的问题.
- 张量分解():
- 知识迁移
- 精细模块设计
主要评价指标:
- 准确率
- 运行时间
- 模型大小
- 有待加入的指标:
- 乘加 (Multiply-and-accumulate )操作量
- 推导时间
- 数据吞吐量
- 硬件能耗
设计硬件友好型深度模型将有助于加速推进深度学习的工程化实现,也是网络结构优化的重点研究方向。
参考文献列表
- Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of Neural Information Processing Systems. Lake Tahoe,Nevada, USA: Curran Associates Inc, 2012. 1097−1105
- Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014.818−833
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition.arXiv: 1409.1556,2014.
- Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D. Going deeper with convolutions. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Boston, USA: 2015. 1−9
- He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. IEEE: LasVegas, USA: 2016. 770−778
- LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278−2324
- He K M, Sun J. Convolutional neural networks at constrained time cost. In: Proceedings of Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 5353−5360
- LeCun Y, Denker J S, Solla S A. Optimal brain damage.In: Proceedings of Neural Information Processing Systems.MIT Press: Denver, Colorado, USA: 1990. 598−605
- Hassibi B, Stork D G, Wolff G. Optimal brain surgeon: extensions and performance comparisons. In: Proceedings of Neural Information Processing Systems. MIT Press: Denver, Colorado, USA: 1994. 263−270
- Cheng Y, Wang D, Zhou P, Zhang T. A survey of model compression and acceleration for deep neural networks.arXiv: 1710.09282, 2017.
- Cheng J, Wang P, Li G, Hu Q H, Lu H Q. Recent advances in efficient computation of deep convolutional neural networks.Frontiers of Information Technology & Electronic Engineering, 2018, 19(1): 64−77
- Lei Jie, Gao Xin, Song Jie, Wang Xing-Lu, Song Ming-Li.Compression of deep networks model: a review. Journal of Software, 2018, 29(02): 251−266( 雷杰 , 高鑫 , 宋杰 , 王兴路 , 宋明黎 . 深度网络模型压缩综述 . 软件学报 , 2018, 29(02):251-266.)
- Hu H, Peng R, Tai Y W, Tang C K. Network trimming: a data-driven neuron pruning approach towards efficient deep architectures. arXiv: 1607.03250, 2016.
- Cheng Y, Wang D, Zhou P. Model Compression and Acceleration for Deep Neural Networks: The Principles, Progress,and Challenges. IEEE Signal Processing Magazine, 2018,35(1): 126−136
- Gong Y, Liu L, Yang M, Bourdev L. Compressing deep convolutional networks using vector quantization. arXiv:1412.6115, 2014.
- Reed R. Pruning algorithms-a survey. IEEE Transactions on Neural Networks, 1993, 4(5): 740−747
- Collins M D, Kohli P. Memory bounded deep convolutional networks. arXiv: 1412.1442, 2014.
- Jin X J, Yuan X T, Feng J S, Yan S C. Training skinny deep neural networks with iterative hard thresholding methods. arXiv: 1607.05423, 2016.
- Zeiler M D, Fergus R. Less is more: towards compact CNNs. In: Proceedings of European Conference on Computer Vision. Amsterdam,The Netherlands: Springer, 2016.662−677
- Wen W, Wu C P, Wang Y D, Chen Y R, Li H. Learning structured sparsity in deep neural networks. In: Proceedings of Neural Information Processing Systems. Spain: 2016.2074−2082
- Lebedev V, Lempitsky V. Fast convnets using group-wise brain damage. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA:IEEE, 2016. 2554−2564
- Louizos C, Welling M, Kingma D P. Learning sparse neural networks through L 0 regularization. arXiv: 1712.01312,2017.
- Hinton G E, Srivastava N, Krizhevsky A, Sutskever I,Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors.arXiv: 1207.0580,2012.](https://arxiv.org/abs/1207.0580)
- Srivastava N, Hinton G, Krizhevsky A, Sutskever I,Salakhutdinov R.Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 2014, 15(1): 1929−1958
- Li Z, Gong B, Yang T. Improved dropout for shallow and deep learning. In: Proceedings of Neural Information Processing Systems. Spain: 2016.2523−2531
- Anwar S, Sung W. Coarse pruning of convolutional neural networks with random masks. In: International Conference on Learning Representation. France: 2017.134−145
- Hanson S J, Pratt L Y. Comparing biases for minimal network construction with back-propagation. In: Proceedings of Neural Information Processing Systems. Denver, Colorado, USA: 1989. 177−185
- Han S, Mao H, Dally W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv: 1510.00149,2015.
- Srinivas S, Babu R V. Data-free parameter pruning for deep neural networks. arXiv: 1507.06149, 2015.
- Guo Y, Yao A, Chen Y. Dynamic network surgery for efficient DNNs. In: Proceedings of Neural Information Processing Systems. Denver, Colorado, USA: 2016. 1379−1387
- Liu X Y, Jeff Pool, Han S, William J.Dally. Efficient sparse-winograd convolutional neural networks. In: International Conference on Learning Representation. Canada: 2018.
- He Y, Zhang X, Sun J. Channel pruning for accelerating very deep neural networks. In: Proceedings of International Conference on Computer Vision. Venice, Italy: 2017. 6
- Li H, Kadav A, Durdanovic I, Samet H, Graf H P. Pruning filters for efficient convNets. arXiv: 1608.08710, 2016.
- Denil M, Shakibi B, Dinh L, De F N. Predicting parameters in deep learning. In: Proceedings of Neural Information Processing Systems. Lake Tahoe, Nevada, United States: 2013. 2148−2156
- Denil M, Shakibi B, Dinh L, De F N. Predicting parameters in deep learning. In: Proceedings of Neural Information Processing Systems. Lake Tahoe, Nevada, United States: 2013.2148−2156
- Rigamonti R, Sironi A, Lepetit V, Fua P. Learning separable filters. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Portland, OR, USA: IEEE,2013. 2754−2761
- Jaderberg M, Vedaldi A, Zisserman A. Speeding up convolutional neural networks with low rank expansions. arXiv:1405.3866, 2014.
- Denton E, Zaremba W, Bruna J, LeCun Y, Fergus R. Exploiting linear structure within convolutional networks for efficient evaluation. In: Proceedings of Neural Information Processing Systems. Montreal, Quebec, Canada: 2014.1269−1277
- Lebedev V, Ganin Y, Rakhuba M, Oseledets I, Lempitsky V.Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv: 1412.6553, 2014.
- Tai C, Xiao T, Zhang Y, Wang X G. Convolutional neural networks with low-rank regularization. arXiv: 1511.06067, 2015.
- Zhang X, Zou J, Ming X, He K M, Sun J. Efficient and accurate approximations of nonlinear convolutional networkss.In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1984−1992
- Kim Y D, Park E, Yoo S, Choi T, Yang L, Shin D. Compression of deep convolutional neural networks for fast and low power mobile applications. arXiv: 1511.06530, 2015.
- Wang Y, Xu C, Xu C, Tao D. Beyond filters: Compact feature map for portable deep model. In: Proceedings of International Conference on Machine Learning. Sydney, Australia: 2017. 3703−3711
- Astrid M, Lee S I. CP-decomposition with tensor power method for convolutional neural networks compression. In:Proceedings of IEEE Conference on Big Data and Smart Computing. Korea: IEEE, 2017. 115−118
- Bucila C, Caruana R, Niculescu-Mizil A. Model compression. In: Proceedings of The 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Philadelphia, USA: 2006. 535−541
- Ba L J, Caruana R. Do deep nets really need to be deep?In: Proceedings of Neural Information Processing Systems.Montreal, Quebec, Canada: 2014. 2654−2662
- Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv: 1503.02531, 2015.
- (Romero A, Ballas N, Kahou S E, Chassang A, Gatta C, Bengio Y. Fitnets: hints for thin deep nets. arXiv: 1412.6550,2014)
- Luo P, Zhu Z, Liu Z, Wang X G, Tang X O. Face model compression by distilling knowledge from neurons. In: Proceedings of AAAI Conference on Artificial Intelligence. Phoenix,Arizona, USA: 2016. 3560−3566
- Chen T, Goodfellow I, Shlens J. Net2net: accelerating learning via knowledge transfer. arXiv: 1511.05641, 2015.
- Zagoruyko S, Komodakis N. Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. In: International Conference on Learning Representation. France: 2017.
- Lucas T, Iryna K, Alykhan T, Ferenc H. Faster gaze prediction with dense networks and Fisher pruning. arXiv:1801.05787, 2018.
- Yim J, Joo D, Bae J, Kim J. A gift from knowledge distillation: fast optimization, network minimization and transfer learning. In: Proceedings of Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017.
- Chen G, Choi W, Yu X, Han T, Chandraker M. Learning efficient object detection models with knowledge distillation.In: Proceedings of Neural Information Processing Systems.US: 2017. 742−751
- Lin M, Chen Q, Yan S. Network in network. arXiv:1312.4400, 2013.
- Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv:1502.03167, 2015.
- Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In:Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016.2818−2826
- Szegedy C, Ioffe S, Vanhoucke V, Alemi A A. Inception-v4,inception-resnet and the impact of residual connections on learning. In: Proceedings of AAAI Conference on Artificial Intelligence. San Francisco, California USA: 2017. 12
- Chollet F. Xception: Deep learning with depthwise separable convolutions. arXiv: 1800-1807, 2016.
- Chang J R, Chen Y S. Batch-normalized maxout network in network. arXiv: 1511.02583, 2015.
- Han X, Dai Q. Batch-normalized mlpconv-wise supervised pre-training network in network. Applied Intelligence, 2018,48(1): 142−155
- Srivastava R K, Greff K, Schmidhuber J. Highway networks.arXiv: 1505.00387, 2015.
- Hochreiter S, Schmidhuber J. Long short-term memory.Neural Computation, 1997, 9(8): 1735−1780
- Larsson G, Maire M, Shakhnarovich G. Fractalnet: ultra-deep neural networks without residuals. arXiv:1605.07648,2016.
- Huang G, Sun Y, Liu Z, Sedra D, Weinberger K Q. Deep networks with stochastic depth. In: Proceedings of European Conference on Computer Vision. Amsterdam, The Nether-lands: Springer, 2016. 646−661
- He K M, Zhang X, Ren S, Sun J. Identity mappings in deep residual networks. In: Proceedings of European Conference on Computer Vision. Amsterdam, The Nether-lands:Springer, 2016. 630−645
- Xie S, Girshick R, Dollar P, Tu Z W, He K M. Aggregated residual transformations for deep neural networks. In: Proceedings of Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 5987−5995
- LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015,521(7553): 436
- Zagoruyko S, Komodakis N. Wide residual networks. arXiv:1605.07146, 2016.
- Targ S, Almeida D, Lyman K. Resnet in resnet: generalizing residual architectures. arXiv: 1603.08029, 2016.
- Zhang K, Sun M, Han X, Yuan X F, Guo L R, Liu T. Residual networks of residual networks: multilevel residual networks. IEEE Transactions on Circuits and Systems for Video Technology, 2017: 1−1
- Abdi M, Nahavandi S. Multi-residual networks. arXiv:1609.05672, 2016.
- Huang G, Liu Z, Weinberger K Q. Densely connected convolutional networks. In: Proceedings of Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017.
- Zhang Ting, Li Yu-Jian, Hu Hai-He, Zhang Ya-Hong. A gender classification model based on cross-connected convolutional neural networks. Acta Automatica Sinica, 2016,42(6): 858-865( 张婷 , 李玉鉴 , 胡海鹤 , 张亚红 . 基于跨连卷积神经网络的性别分类模型 . 自动化学报 , 2016, 42(6): 858-865)
- Li Yong, Lin Xiao-Zhu, Jiang Meng-Ying. Facial expression recognition with cross-connect LeNet-5 network. Acta Automatica Sinica, 2018, 44(1): 176-182( 李勇 , 林小竹 , 蒋梦莹 . 基于跨连接 LeNet-5 网络的面部表情识别 .自动化学报 , 2018, 44(1): 176-182)
- Howard A G, Zhu M, Chen B, Kalenichenko D. Mobilenets:efficient convolutional neural networks for mobile vision applications. arXiv: 1704.04861, 2017.
- Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L C.MobileNetV2: inverted residuals and linear bottlenecks. In:Proceedings of Computer Vision and Pattern Recognition.USA: IEEE, 2018. 4510−4520
- Zhang X, Zhou X, Lin M, Sun J. ShuffleNet: an extremely efficient convolutional neural network for mobile devices. In:Proceedings of Computer Vision and Pattern Recognition.USA: IEEE, 2018.