2019-08-25 08:44:23
TensorRT学习笔记
参考链接:
- 官网指导手册;
- github 开源代码地址
- API
-
官方文章翻译
1 tenosrRT的安装
- 官方指导
这里主要是使用Tar 安装,前提是已经安装好cudnn和cuda;
下载文件后指直接解压
1.1 动态链接库安装
在~/.bashrc中添加lib目录
#settensorrt
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/wangpengcheng/TensorRT-5.1.5.0/lib
1.2 python环境安装
cd TensorRT-5.1.x.x/python
#python2.7
sudo pip2 install tensorrt-5.1.x.x-cp27-none-linux_x86_64.whl
#python3.x
sudo pip3 install tensorrt-5.1.x.x-cp3x-none-linux_x86_64.whl
1.3 安装Python UFF(tenosrflow)
cd TensorRT-5.1.x.x/uff
#python2.7
sudo pip2 install uff-0.6.3-py2.py3-none-any.whl
#python3.x
sudo pip3 install uff-0.6.3-py2.py3-none-any.whl
1.4 安装Python graphsurgeon
cd TensorRT-5.1.x.x/graphsurgeon
#Python2.7
sudo pip2 install graphsurgeon-0.4.1-py2.py3-none-any.whl
#python3.x
sudo pip3 install graphsurgeon-0.4.1-py2.py3-none-any.whl
1.5 测试
cd <TensorRT root directory>/samples/sampleMNIST
make
cd TensorRT-5.1.5.0/bin
./sample_mnist
输出:
[I] Building and running a GPU inference engine for MNIST
[I] Input:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@%=#@@@@@%=%@@@@@@@@@@
@@@@@@@ %@@@@@@@@@
@@@@@@@ %@@@@@@@@@
@@@@@@@#:-#-. %@@@@@@@@@
@@@@@@@@@@@@# #@@@@@@@@@@
@@@@@@@@@@@@@ #@@@@@@@@@@
@@@@@@@@@@@@@: :@@@@@@@@@@@
@@@@@@@@@%+== *%%%%%%%%%@@
@@@@@@@@% -@
@@@@@@@@@#+. .:-%@@
@@@@@@@@@@@* :-###@@@@@@
@@@@@@@@@@@* -%@@@@@@@@@@@
@@@@@@@@@@@* *@@@@@@@@@@@@
@@@@@@@@@@@* @@@@@@@@@@@@@
@@@@@@@@@@@* #@@@@@@@@@@@@
@@@@@@@@@@@* *@@@@@@@@@@@@
@@@@@@@@@@@* *@@@@@@@@@@@@
@@@@@@@@@@@* @@@@@@@@@@@@@
@@@@@@@@@@@* @@@@@@@@@@@@@
@@@@@@@@@@@@+=#@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[I] Output:
0:
1:
2:
3:
4:
5:
6:
7: **********
8:
9:
&&&& PASSED TensorRT.sample_mnist # ./sample_mnist
2. tensorRT简介
TensorRT是高性能c++推理库。
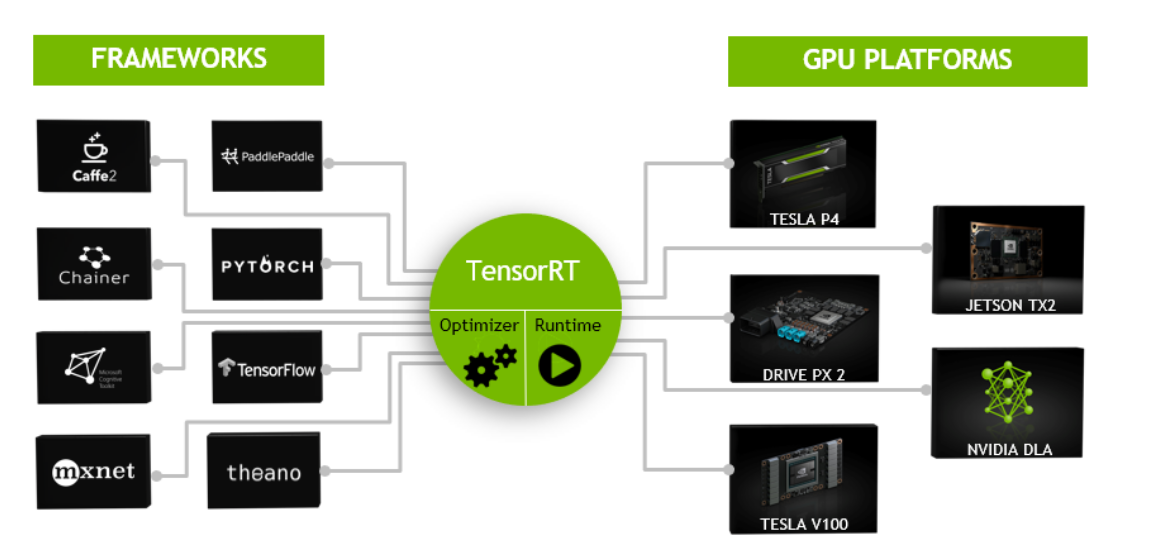 ;
;
其实类似TensorRT具体工作的有很多,例如TVM、TC(Tensor Comprehensions),都做了一些类似于TensorRT的工作,将训练好的模型转化为运行在特定端(例如GPU)的进行模型优化等一系列操作后的代码,从而达到快速预测的效果。
推理项目的一般实现过程:
- 模型的训练:主要是数据的预处理,网络的设计,模型的训练,
- 解决方案的设计:算法平台的确定,编程语言,硬件确定;网络的输入和输出等
- 解决方案的实施:使用tensorRT推理框架进行部署。
2.1 tensorRT的工作原理
- 网络定义(Network Definition):
- 建立(Builder):建立相关的网络。
- 推理引擎(Engine):
tenosrRT提供其他的工具可以将,其它的网络模型转换到当前的网络模型中。
- Caffe Parser:
- UFF Parse:
- ONNX Parser:
3. TensorRT的一般使用
3.1 程序设计的一般流程:
- 创建网络
IBuilder* builder = createInferBuilder(gLogger); INetworkDefinition* network = builder->createNetwork(); - 添加输入数据
auto data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{1, INPUT_H, INPUT_W}); - 添加卷积层:传递给tensorRT的权重存在在host主机中
auto conv1 = network->addConvolution(*data->getOutput(0), 20, DimsHW{5, 5}, weightMap["conv1filter"], weightMap["conv1bias"]); conv1->setStride(DimsHW{1, 1}); - 添加池化层:
auto pool1 = network->addPooling(*conv1->getOutput(0), PoolingType::kMAX, DimsHW{2, 2}); pool1->setStride(DimsHW{2, 2}); - 添加全连接层
auto ip1 = network->addFullyConnected(*pool1->getOutput(0), 500, weightMap["ip1filter"], weightMap["ip1bias"]); auto relu1 = network->addActivation(*ip1->getOutput(0), ActivationType::kRELU); - 添加SotfMax层
auto prob = network->addSoftMax(*relu1->getOutput(0)); prob->getOutput(0)->setName(OUTPUT_BLOB_NAME); - 获取输出层
network->markOutput(*prob->getOutput(0));
3.2 导入外部模型
- 创建builder和网络
IBuilder* builder = createInferBuilder(gLogger); nvinfer1::INetworkDefinition* network = builder->createNetwork(); - 从其他特殊格式文件中创建 ```c++ //获取相关网络参数
//ONNX
auto parser = nvonnxparser::createParser(*network, gLogger); //UFF
auto parser = nvuffparser::createUffParser(); //Caffe
auto parser = nvcaffeparser1::createCaffeParser();
3. 获取参数
```c++
parser->parse(args);
3.3 导入一个caffe模型
//创建builder
IBuilder* builder=createInferBuilder(gLogger);
//创建一个推理网络
INetworkDefinition* network=builder->createNetwork();
//创建caffe参数
ICaffeParser* parser=createCaffeParser();
//从参数中导入模型
const IBlobNameToTensor=parser->parse("deploy_file" , "modelFile", *network, DataType::kFLOAT);
//设置输出参数
for(auto& s:outputs)
{
network->markOutput(*blobNameToTensor->find(s.c,str()));
}
3.4 创建一个Engine
3.4.1 使用builder建立一个引擎
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(1<<20);
ICudaEngine* engine=builder->buildCudaEngine(*network);
3.4.2 相关变量的销毁
parser->destroy();
network->destroy();
builder->destroy();
3.5 在c++中序列化模型
//按照上文进行离线的builder建立--存储模型
IHostMemory *serializedModel = engine->serialize();
//将模型存储到磁盘上
...
//销毁建立的模型
serializedModel->destroy();
//创建要反序列化的运行时对象--加载模型
IRuntime* runtime=createInferRuntime(gLogger);
ICudaEngine* engine=runtime->deserializeCudaEngine(modelData, modelSize, nullptr);
3.6 高性能的推理
//创建一个推理上下文
IExecutionContext *context = engine->createExecutionContext();
//根据输入和输出的名称确定输入输出blob的索引
int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
//创建指针,指向输入输出buffer
void* buffer[2];
buffer[inputIndex]=inputbuffer;
buffer[outputIndex]=outputBuffer
//因为tensorrt是异步的,因此将kerneks添加到cuda流当中
context->enqueue(batchSize,buffers,stream,nullptr);
3.7 内存管理和引擎更改
默认的内存管理是创建一个上下文:IExecutionContext
//建立一个可修改的推理引擎
builder->setRefittable(true);
//创建network推理引擎
builder->buildCudaEngine(network);
//创建一个可更改的对象
ICudaEngine* engine=...;
IRefitter* refitter=createInferRefitter(*engine,gLogger);
//更新权重,注意新权重应该在尺寸上和旧权重相同,避免内存错误
Weights newWeights=...;
refitter->setWeights("MyLayer",WeightsRole::KKERNEL,newWeights);
//找到其它必须被支持的网络参数
const int n=refitter->getMissing(0,nullptr,nullptr);
std::vector<const char*> layerName(n);
std::vector<WeightsRole> WeightsRoles(n);
refitter->getMissing(n,layerNames.data(),weightsRoles.data());
//支持丢失的权重
for(int i=0;i<n;++i){
refitter->setWeights(layerNames[i],weightsRoles[i],Weights{...});
}
//更新整个推理引擎的权重
bool success=refitter->refitCudaEngine();
assert(success);
//销毁 refitter
refitter->destroy();
4. 传统layers的tensorRT拓展
tenosrRT中可以使用IPluginV2Ext和IPluginCreator来对已有的网络进行拓展。
-
IPluginV2Ext
- 这个类是插件扩展的基础类,支持使用传统的版本
-
IPluginCreator
- IPluginCreator是自定义图层的创建者类,用户可以使用它来获取插件名称,版本和插件字段参数。 它还提供了在网络构建阶段创建插件对象的方法,并在推理期间对其进行反序列化。
TensorRT还提供了通过调用REGISTER_TENSORRT_PLUGIN(pluginCreator)来注册插件的功能,该插件将插件创建者静态注册到插件注册表。在运行时,可以使用extern函数getPluginRegistry()查询插件注册表。插件注册表存储指向所有已注册的插件创建器的指针,可用于根据插件名称和版本查找特定的插件创建器。TensorRT库包含可以加载到应用程序中的插件。所有这些插件的版本都设置为1.这些插件的名称是:
- RPROI_TRT
- Normalize_TRT
- PriorBox_TRT
- GridAnchor_TRT
- NMS_TRT
- LReLU_TRT
- Reorg_TRT
- Region_TRT
- Clip_TRT
注意为了能够使用这些插件,libnvinfer_plugin.so链接库,必须被包括在项目中。可以使用initLibNvInferPlugins(void* logger, const char* libNamespace)函数来进行初始化。
一个简单的添加扩展layer的代码如下所示;
//使用extern函数getPluginRegistry访问全局TensorRT插件注册表
auto creator = getPluginRegistry()->getPluginCreator(pluginName, pluginVersion);
const PluginFieldCollection* pluginFC = creator->getFieldNames();
//填充插件层的字段参数(比如layerFields)
PluginFieldCollection *pluginData = parseAndFillFields(pluginFC, layerFields);
//使用layerName和插件元数据创建插件对象
IPluginV2 *pluginObj = creator->createPlugin(layerName, pluginData);
//使用网络API将插件添加到TensorRT网络
auto layer = network.addPluginV2(&inputs[0], int(inputs.size()), pluginObj);
… (build rest of the network and serialize engine)
//销毁插件对象
pluginObj->destroy();
… (destroy network, engine, builder)
… (free allocated pluginData)
注意:
- pluginData应该在传递给createPlugin之前在堆上分配PluginField条目。
- 上面的createPlugin方法将在堆上创建一个新的插件对象并返回指向它的指针。确保销毁pluginObj,如上所示,以避免内存泄漏。
在序列化期间,TensorRT引擎将在内部存储所有IPluginV2类型插件的插件类型,插件版本和命名空间(如果存在)。在反序列化期间,TensorRT引擎会查找此信息,以便从插件注册表中找到插件创建器。这使TensorRT引擎能够在内部调用IPluginCreator::deserializePlugin()方法。 反序列化期间创建的插件对象将由TensorRT引擎通过调用IPluginV2::destroy()方法在内部销毁。
在以前的TensorRT版本中,您必须实现nvinfer1::IPluginFactory类以在反序列化期间调用createPlugin方法。对于使用TensorRT注册并使用addPluginV2添加的插件,不再需要这样做。
创建一个传统的caffe layer
//创建一个新的FooPlugin
class FooPlugin:public IPluginExt
{
...implement all class methods for your plugin
};
class MyPluginFactory : public nvinfer1::IPluginFactory, public nvcaffeparser1::IPluginFactoryExt
{
...implement all factory methods for your plugin
};
//使用IPluginV2的插件注册器,可以不用导入nvinfer1::IPluginFactory,但是需要使用nvcaffeparser1::IPluginFactoryV2和IPluginCreator来代替注册导入
class FooPlugin:public IPluginV2
{
...implement all class methods for your plugin
};
class FooPluginFactory:public nvcaffeparser1::IPluginFactoryV2
{
virtual nvinfer1::IPluginV2* createPlugin(...)
{
...create and return plugin object of type FooPlugin
}
bool isPlugin(const char* name)
{
...check if layer name corresponds to plugin
}
}
class FooPluginCreator:public IPluginCreator
{
...implement all creator methods here
};
REGISTER_TENSORRT_PLUGIN(FooPluginCreator);
5. 使用混合精度
TensorRT支持32-bit、16-bit和8-bit的混合精度的运算。使用如下API开启混合精度
if (builder->platformHasFastFp16()) { … };
if (builder->platformHasFastInt8()) { … };
设置layer的精度
//设置允许的精度
layer->setPrecision(nvinfer1::DataType::kINT8);
//设置输出类型和精度
layer->setOutputType(out_tensor_index, nvinfer1::DataType::kFLOAT)
//使用严格模式,使得上述操作强制执行
builder->setStrictTypeConstraints(true);
//允许Fp16Mode推理
builder->setFp16Mode(true);
//此标志允许(但不保证)在构建引擎时将使用16位内核。您可以通过设置以下构建器标志来选择强制16位精度:
builder->setStrictTypeConstraints(true);
5.8 使用INT8量化
参考链接:
使用INT8量化之前需要首先设置推理允许使用INT8模式
builder->setInt8Mode(true);
注意使用INT8量化之前,需要对32位的数据进行量化裁剪。TensorRT希望你使用动态范围技术来进行每个的推理。可以设置范围如下:
//设置量化范围
ITensor* tensor = network->getLayer(layer_index)->getOutput(output_index);
tensor->setDynamicRange(min_float, max_float);
//设置输入
ITensor* input_tensor = network->getInput(input_index);
input_tensor->setDynamicRange(min_float, max_float);
5.8.1 使用C++进行INT8校准
INT8校准提供了生成每个激活张量动态范围的替代方案。可以将该方法归类为后训练技术以生成适当的量化比例。确定这些比例因子的过程称为校准,并要求应用程序传递批量的网络代表性输入(通常来自训练集的批次)。实验表明,大约500个图像足以校准ImageNet分类网络。
构建INT8引擎时,构建器执行以下步骤:
- 构建一个32位引擎,在校准集上运行它,并记录激活值分布的每个张量的直方图。
- 根据直方图构建校准表。
- 从校准表和网络定义构建INT8引擎。