论文名称(Tile)
- 作者(authors):方 程
-
文献引用(Published in):[1] 方程,邢座程,陈顼颢,张洋.一种基于GPU的高性能稀疏卷积神经网络优化[J].计算机工程与科学,2018,40(12):2103-2111.
- 文章链接:知网
- 期刊:计算机工程与科学
写作目的(解决了什么问题)(What is the motivation for this work (both people problem and technical problem)?)
CNN压缩之后的稀疏性导致的GPU性能的下降,提出了新的GPU卷积算法来解决这个问题。 caffe中的im2col算法造成了大量的内存复制开销。
本文通过在CPU上实现直接稀疏卷积算法,打破了GPU架构下传统稠密算法对于稀疏结构处理的局限性,有效解决了权重删减后SCNN在 GPU上运行出现性能损失的问题。对于高稀疏度,甚至是GPU所不擅长处理的不规则数据,本文的设计仍然有着极大的优势。
提出/建议的解决方案(假设、想法、设计)? (What is the proposed solution (hypothesis, idea, design)?)
采用直接稀疏卷积算法,来加速GPU处理稀疏数据:将卷积运算转换为稀疏向量与稠密向量的内积运算,具体流程如下:
对Wm中block的设置和线程的具体分配和计算流程;注意这里的一行卷积file的集合

优化后计算映射
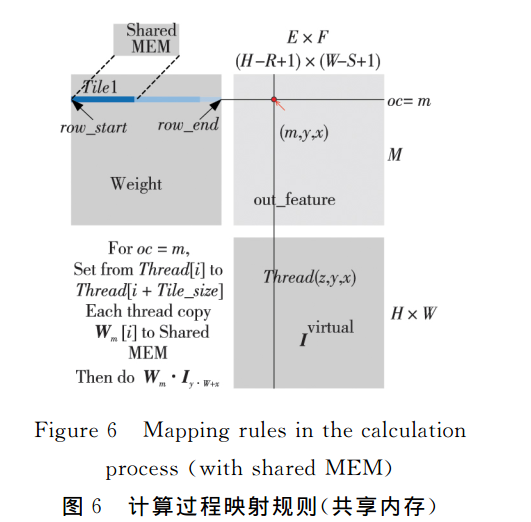
- 将Wm放入共享内存
- 将Wm分块化,块Tile_i设置为特定长度下的一维数组–block下的线程总数,线程Thread(z,y,x)将Title_i数据写入共享内存后进行等待,直到所有线程完成数据的分布
- Thread(z,y,x)完成内存共享向量Tile_i与向量I(y*W+x)的内积运算。具体计算如下:
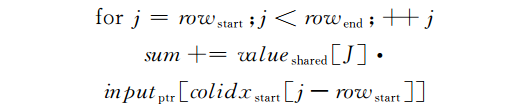
- 每次累加之后,访问共享内存未命中时,证明计算完毕,替换下一个Tile块到共享内存
- m中的所有数据计算完毕;将当前点的sum输出:output[(mE+y)F+x]=sum;
- 只对权重矩阵稀疏度达到0.6以上的才使用共享内存算法,避免过多的内存访问问题。
该解决方案(作者和您的评价)如何评价?(What is the evaluation of the solution (both author’s and yours)?)
在直接稀疏卷积的基础之上,使用了block的共享内存优化,本质上还是对于GPU访问存储的优化。注意这里最终连续存储的是channels中的数据,因此,可以直接进行计算加减
文章中的疑惑或者不了解?(What do you have questions about or don’t you understand?)
代码的具体实现流程
在采用这种方法之前,您需要了解什么?(What would you need to know before you would adopt this approach?)
- CNN基本操作
- 压缩CNN的方法:
- 基于分解:
- 基于删减(剪枝)
- SCNN(Sparse Convolutional Neural Networks)
- CUDA
- cuBLAS
- cuSPARSE
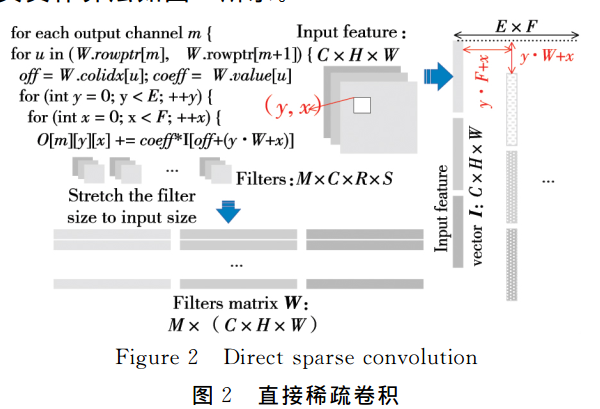
faster cnns with direct sparse convolutions and guided pruning 直接稀疏卷积和引导剪枝
论文的贡献(作者和您的意见)?(What are the paper’s contributions (author’s and your opinion)?)
作者文章中的贡献(paper’s contributions)
- 针对卷积层关键优化路径上完成直接稀疏卷积 算法在GPU架构上的并行化实现,打破GPU上采用传统稠密算法的局限性,给出了一种可行且高效的GPU加速SCNN方案。
- 采用最大限度的线程映射,充分利用GPU的硬件计算资源,防止产生稀疏结构运算对GPU资源的浪费
- 采用最优的任务调度,合理安排每个单线程的任务工作,减少线程同步过程中某一部分线程的等待时间,提高资源利用率
- 充分利用直接稀疏卷积算法数据处理过程中的数据局部性,增加数据复用,对于同一个block的所有线程,采用共享内存来减少数据访存时间
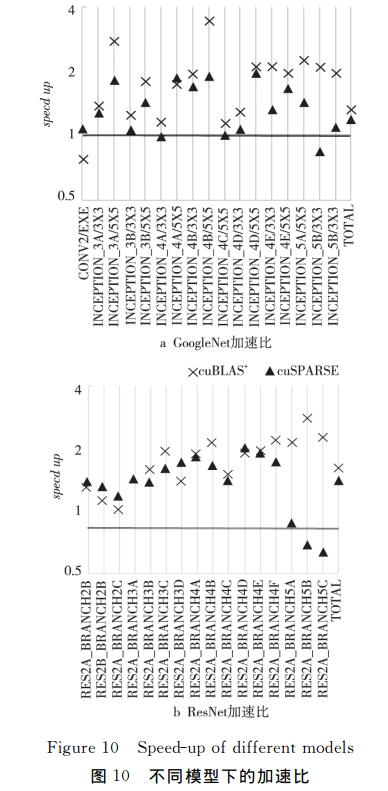
网络实现的加速比
| 网络类型 | 相对cuBLAS加速比 | 相对cuSPARSE加速比 |
|---|---|---|
| AlexNet | 1.07~1.23 | 1.31~1.42 |
| GoogleNet | 1.17~3.51 | 1.09~2.00 |
| ResNet | 1.32~5.00 | 1.07~3.22 |
不同模型上的加速比
个人认为他的贡献(your opinion about paper’s contributions)
在直接稀疏卷积基础之上,改进了内存访问,对于大共享内存的GPU性能比较好。
这项研究(作者和您的研究)的未来方向是什么?(What are future directions for this research (author’s and yours)?)
这项研究作者的未来研究方向(What are future directions for this research author’s)
这项研究你的未来研究方向(What are future directions for this research yours)
这种内存访问优化算法在不同卷积大小和内存上的访问优化,另外探究输入batch_size对设备的具体影响。