2019-10-24 20:25:49
Linux内核设计与实现 学习笔记 (三)
第 9 章 内核同步介绍
在单处理器时,只有在中断发生的时候,或者在内核代码明确地请求重新调度、执行另外一个任务时,数据才能被访问。
- 锁技术: Linux kernel提供了多种锁机制,如自旋锁、信号量、互斥量、读写锁、顺序锁等。各种锁的简单比较如下,具体实现和使用细节这里就不展开了,可以参考《Linux内核设计与实现》等书的相关章节。
- 自旋锁,不休眠,无进程上下文切换开销,可以用在中断上下文和临界区小的场合;
- 信号量,会休眠,支持同时多个并发体进入临界区,可以用在可能休眠或者长的临界区的场合;
- 互斥量,类似与信号量,但只支持同时只有一个并发体进入临界区;
- 读写锁,支持读并发,写写/读写间互斥,读会延迟写,对读友好,适用读侧重场合;
- 顺序锁,支持读并发,写写/读写间互斥,写会延迟读,对写友好,适用写侧重场合;
锁技术虽然能有效地提供并行执行下的竞态保护,但锁的并行可扩展性很差,无法充分发挥多核的性能优势。锁的粒度太粗会限制扩展性,粒度太细会导致巨大的系统开销,而且设计难度大,容易造成死锁。除了并发可扩展性差和死锁外,锁还会引入很多其他问题,如锁惊群、活锁、饥饿、不公平锁、优先级反转等。不过也有一些技术手段或指导原则能解决或减轻这些问题的风险。 - 按统一的顺序使用锁(锁的层次),解决死锁问题;
- 指数后退,解决活锁/饥饿问题;
- 范围锁(树状锁),解决锁惊群问题;
- 优先级继承,解决优先级反转问题;
- 原子技术:原子技术主要是解决cache和内存不一致性和乱序执行对原子访问的破坏问题。Linux kernel中主要的原子原语有:
- ACCESS_ONCE()、READ_ONCE() and WRITE_ONCE():禁止编译器对数据访问的优化,强制从内存而不是缓存中获取数据;
- barrier():乱序访问内存屏障,限制编译器的乱序优化;
- smb_wmb():写内存屏障,刷新store buffer,同时限制编译器和CPU的乱序优化;
- smb_rmb():读内存屏障,刷新invalidate queue,同时限制编译器和CPU的乱序优化;
- smb_mb():读写内存屏障,同时刷新store buffer和invalidate queue,同时限制编译器和CPU的乱序优化;
- atomic_inc()/atomic_read()等:整型原子操作; 严格来说,Linux kernel作为系统软件,实现受硬件影响很大,不同硬件有不同的内存模型,因此,不同于高级语言,Linux kernel的原子原语语义并没有一个统一模型。比如在SMP的ARM64 CPU上,barrier、smb_wmb、smb_rmb的实现与smb_mb都是一样的,都是volatile (“” ::: “memory”)。 另外,再多提一句的是,atomic_inc()原语为了保证原子性,需要对cache进行刷新,而缓存行在多核体系下传播相当耗时,其多核下的并行可扩展性差。
- 无锁技术:原子技术,是无锁技术中的一种,除此之外,无锁技术还包括RCU、Hazard pointer等。值得一提的是,这些无锁技术都基于内存屏障实现的。
- Hazard pointer主要用于对象的生命周期管理,类似引用计数,但比引用计数有更好的并行可扩展性;
- RCU(Linux RCU 机制详解)适用的场景很多,其可以替代:读写锁、引用计数、垃圾回收器、等待事物结束等,而且有更好的并行扩展性。但RCU也有一些不适用的场景,如写侧重;临界区长;临界区内休眠等场景。
- 不过,所有的无锁原语也只能解决读端的并行可扩展性问题,写端的并行可扩展性只能通过数据分割技术来解决。
- 数据分割技术:分割数据结构,减少共享数据,是解决并行可扩展性的根本办法。对分割友好(即并行友好)的数据结构有:
- 数组
- 哈希表
- 基树(Radix Tree)/稀疏数组
- 跳跃列表(skip list)
使用这些便于分割的数据结构,有利于我们通过数据分割来改善并行可扩展性。 除了使用合适的数据结构外,合理的分割指导规则也很重要: - 读写分割:以读为主的数据与以写为主的数据分开;
- 路径分割:按独立的代码执行路径来分割数据;
- 专项分割:把经常更新的数据绑定到指定的CPU/线程中;
- 所有权分割:按CPU/线程个数对数据结构进行分割,把数据分割到per-cpu/per-thread中; 4种分割规则中,所有权分割是分割最彻底的。
以上这些多核并行编程内容基本上涵盖了Linux kernel中所有的并发编程关键技术。当然并行编程还有很多其他技术没有应用到Linux kernel中的,如无副作用的并行函数式编程技术(Erlang/Go等)、消息传递、MapReduce等等。
9.1 临界区和竞争条件
- 临界区:访问和共享数据操作的代码段;
- 同步:避免并发和防止竞争条件;
- 执行线程:所有正在执行的代码实例的总称。
处理器一般都提供对数据访问的原子操作。来防止数据的乱序
9.2 加锁
锁强制确保一次有且只有一个线程对数据结构进行操作,或者禁止其它访问。

锁是使用原子操作实现的,而原子操作不存在竞争。
9.2.1 造成并发执行的原因
用户空间之所以需要同步;是因为用户程序会被调度程序抢占和重新调度。因为单核系统中线程之间是相互交叉进行的,因此也可以称为伪并发进行。
内核中并发执行的原因:中断、软中断和tasklet、内核抢占、睡眠及用户空间的同步、对称多处理。
注意:两个处理器绝对不能同时访问同一共享数据。
9.2.2 了解要保护什么
在Linux 内核编译时,可以配置CONFIG_SMP配置选项控制内核是否支持SMP.当期没有被设置时就不会被编入不必要的代码.
9.3 死锁
死锁产生的条件和避免手段,请参照往期博客.
9.4 争用和扩展性
高度争用的锁会成为系统的瓶颈。锁的设计在开始阶段都很粗,但是当竞争问题变得严重式,设计就更加精细的加锁方向进行。
第 10 章 内核同步方法
10.1 原子操作
参考连连接:
原子操作是其它同步方法的基石–原子操作可以保证指令以原子的方式执行–执行过程不被打断。即使原子操作存在,但是由于执行顺序的不同;问题也有可能发生。

内核中提供了两组原子操作接口–整数操作和位操作;
10.1.1 原子操作
整数的原子操作只能针对atomic_t类型的数据进行处理。这样原子函数就只接受atomic_t的操作。是固体部分atomic_t确保编译器不对相应的值进行访问优化–原子操作最终接收到正确的内存地址,而不是只是一个别名。并且可以屏蔽不同体系结构之间的差异;
//linux/types.h
typedef struct{
volatile int counter;
} atomic_t;
SPARC体系结构上,缺乏原子指令操作;32位int类型的低8位被嵌入了一个锁;避免并发访问。
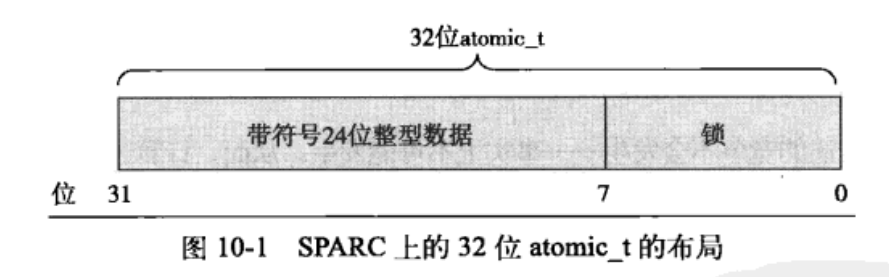
原子操作整数最常见的用途就是实现计数器。使用下面的原子整数操作可以避免锁的使用。
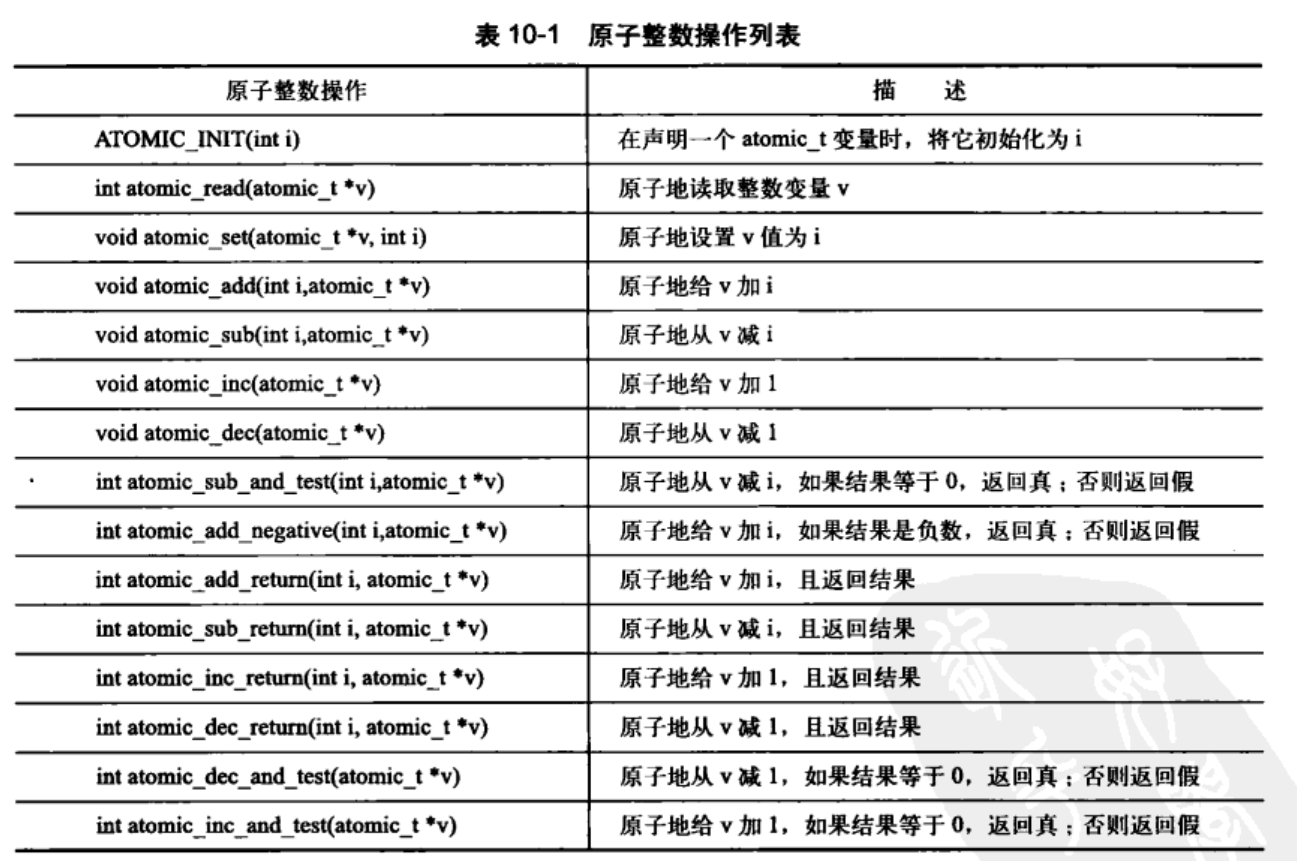
原子性与顺序性的比较
原子性确保指令在执行期间不被打断,要么完全执行完,要么不执行。顺序性确保即使两台或者多条指令处理下载独立的执行线程中,甚至独立的处理器上,他们本来应该的执行顺序确依然要保持。
10.1.2 64位原子操作
因为移植性原因,atomic_t变量大小无法在体系结构之间改变,所以其即便是在64位体系结构下也是32位的。因此存在atomic64_t类型基本功能完全相同,不同的只有整型变量大小变化。
typdef struct{
volatile long counter;
}atomic64_t;
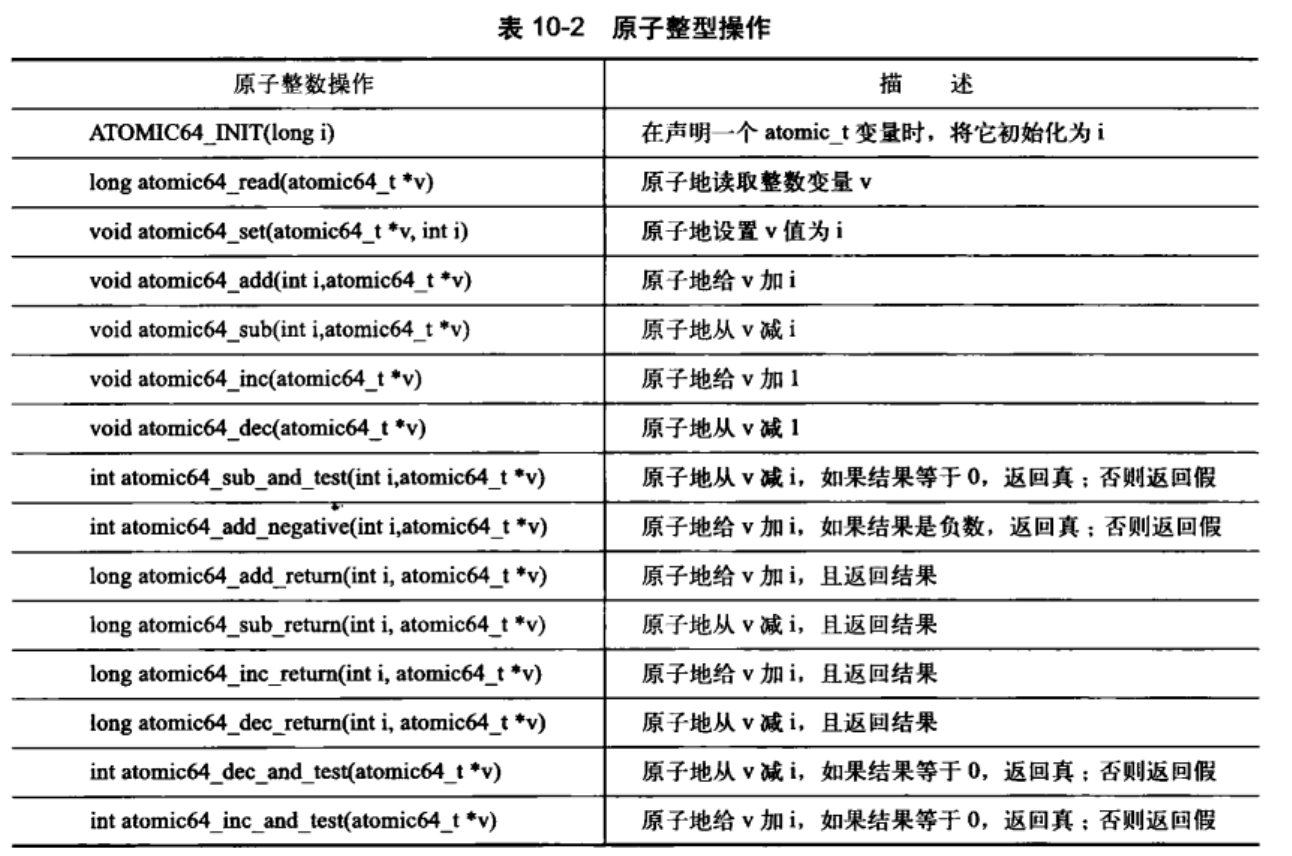
10.1.3 原子位操作
内核在asm/bitops.h中定义了对应的操作。位操作是对普通的内存地址进行操作的。它的参数是一个指针和一个位号。一般32位中;第0位是最低有效位,31位是给定地址的最高有效位。原子位操作是对普通的指针进行的操作,所以不像原子整形对应atomic_t;没有特殊的数据类型。只要指针指向了任何数据都可以进行操作。
unsigned long word=0;
set_bit(0,&word); /* 第0位被设置(原子地) */
set_bit(1,&word); /* 第1位被设置(原子地) */
printk("%u1\n",word); /* 打印3 */
clear_bit(1,&word); /* 清空第1位 */
change_bit(0,&word); /* 翻转第0位的值,这里它被清空 */
/* 原子的设置第0位并且返回设置前的值(0) */
if(test_and_set_bit(0,&word)){
/* 永远不为真 */
}
/* 将原子位指令与一般的c指令语句混合在一起 */
word=7;

/* 搜索第一个被设置的位 */
int find_first_bit(unsigned long *addr,unsigned int size);
/* 搜索第一个未被设置的位 */
int find_first_zero_bit(unsigned long *addr,unsigned int size);
10.2 自旋锁
参考链接:
为了对复杂的数据结构进行访问和修改,需要锁来提供保护。
Linux内核中的自旋锁(spin lock)–最多只能被一个可执行线程持有。一个执行简称试图获得一个自旋锁,就会一直进行忙循环旋转等待,直到锁可以被使用。一般是请求线程睡眠,直到锁重新可用时再唤醒它。持有自旋锁的时间最好小于完成两次上下文切换的时间。
10.2.1 自旋锁方法
自旋锁的实现基本通过汇编实现,相关代码定义在asm/spinlock.h中。需要用到的接口定义在<linux/spinlick.h>中。基本使用形式如下;
DEFINE_SPINLOCK(mr_lock);
spin_lock(&mr_lock);
/* 临界区 */
spin_unlock(&mr_lock);
注意:内核实现的自旋锁不能在递归中使用;必须自己手动释放这个锁
中断处理程序不能使用信号量(会导致睡眠);但可以使用自旋锁。但是一定要先禁止本地中断(同一个处理器)。否则会程序之间的竞争会引起自旋。不同处理器上无此考虑。内核提供的禁止中断同时请求锁的接口使用方法如下:
DEFINE_SPINLOCK(mr_lock);
unsigned long flags;
/* 保存中断的当前状态 */
spin_lock_irqsave(&mr_lock,flags);
/* 临界区域 */
/* 解锁指定的锁 */
spin_unlock_irqrestore(&mr_lock,flags);
单处理器中,在编译时抛弃掉了锁机制,但是任然需要关闭中断以禁止中断处理程序访问共享数据。加锁和解锁分别可以禁止和允许内核抢占。
锁应该主要针对数据。
编译内核时,可以开启CONFIG_DEBUG_SPINLOCK选项,为使用自旋锁的代码加入调试检测手段。可以进行锁的调试。需要进一步全程调试锁,应该打开CONFIG_DEBUG_LOCK_ALLOC选项。
10.2.2 其它针对自旋锁的操作
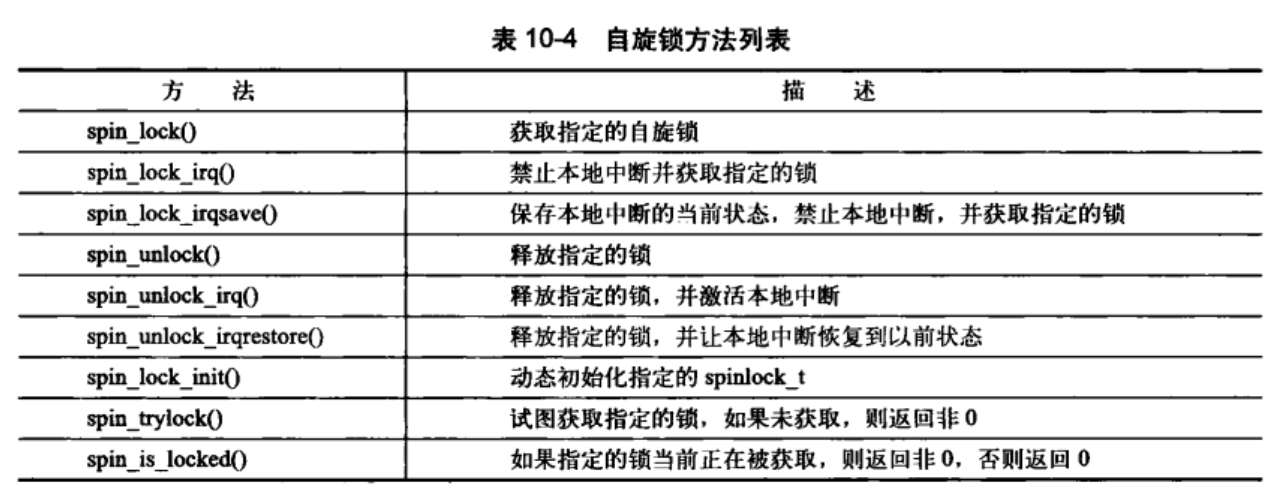
pin lock接口API如下
| 接口API的类型 | spinlock中的定义 | raw_spinlock的定义 |
|---|---|---|
| 定义spinlock并初始化 | DEFINE_SPINLOCK |
DEFINE_RAW_SPINLOCK |
| 动态初始化spin lock | spin_lock_init |
raw_spin_lock_init |
| 获取指定的spin lock | spin_lock |
raw_spin_lock |
| 获取指定的spin lock同时disable本CPU中断 | spin_lock_irq |
raw_spin_lock_irq |
| 保存本CPU当前的irq状态,disable本CPU中断并获取指定的spin lock | spin_lock_irqsave |
raw_spin_lock_irqsave |
| 获取指定的spin lock同时disable本CPU的bottom half | spin_lock_bh |
raw_spin_lock_bh |
| 释放指定的spin lock | ` spin_unlock ` | raw_spin_unlock |
| 释放指定的spin lock同时enable本CPU中断 | spin_unlock_irq |
raw_spin_unock_irq |
| 释放指定的spin lock同时恢复本CPU的中断状态 | spin_unlock_irqstore |
raw_spin_unlock_irqstore |
| 获取指定的spin lock同时enable本CPU的bottom half | spin_unlock_bh |
raw_spin_unlock_bh |
| 尝试去获取spin lock,如果失败,不会spin,而是返回非零值 | spin_trylock |
raw_spin_trylock |
| 判断spin lock是否是locked,如果其他的thread已经获取了该lock,那么返回非零值,否则返回0 | spin_is_locked |
raw_spin_is_locked |
10.2.3 自旋锁和下半部分
函数spin_lock_bh()用于获取指定锁,同时禁止下半部分的执行。spin_unlock_bh()执行相反的操作。
下半部分和进行上下文共享数据时,必须对进程上下文中的共享内存进行数据保护,所以需要同时进行加锁和禁止下半部分的执行,在恰当的时间还需要禁止中断。
同类型的tasklet不可能同时运行。所以对于同来tasklet中的共享数据不需要保护。但是不同tasklet需要保护;但是不需要进行下半部分的禁止,因为同一个处理器上绝对不会有tasklet相互抢占的情况
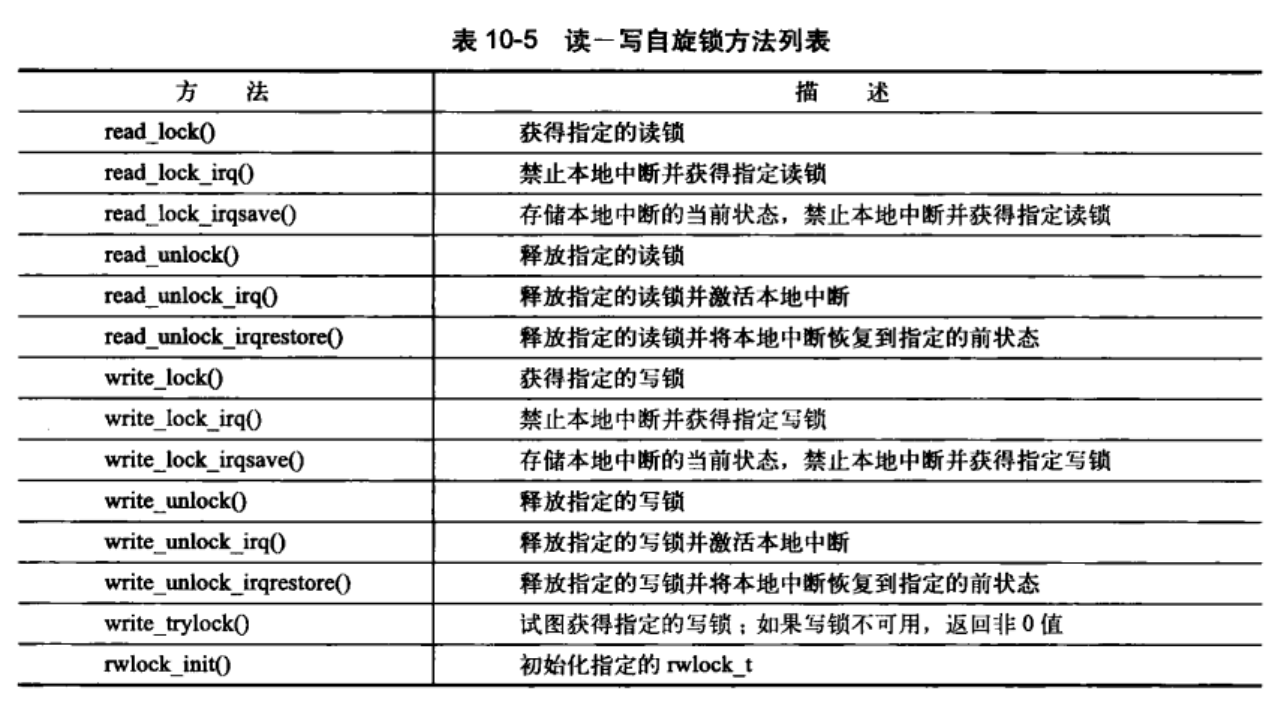
10.3 读-写自旋锁
参考链接: Linux系统编程7:读写锁
Linux中提供了针对生产者消费者的读写自旋锁。其写锁最多只能被一个写任务持有。读写锁也称共享/排斥锁;并发/排斥锁.使用流程大致如下:
/* 初始化读写锁 */
DEFINE_RWLOCK(mr_rwlock);
/* 读者代码 */
read_lock(&rm_rwlock);
/* 只读临界区 */
read_unlock(&mr_rwlock);
/* 写者部分代码 */
write_lock(&mr_rwlock);
/* 代码临界区 */
write_lock(&mr_rwlock);
注意:
- 同时使用读写锁,否则会造成死锁。因为写锁会不断自旋;直到等待所有的读者释放锁–包括他自己。
- 大量的读者会使得,写锁处于饥饿状态
10.4 信号量
参考链接:
Linux中的信号量是一种睡眠锁(自旋锁不会引起睡眠;进程的睡眠相当于重新调度);信号量会将其推进一个等待队列;然后让其睡眠。处理器重新获得自由,从而去执行其它代码。信号量的开销比自旋锁大;利用率比较高。
有用结论:
- 信号量适合锁被长时间持有的进程。
- 由于执行线程在锁被争用时会睡眠;所以只能在进程上下文中才能获得信号量锁,因为在中断上下文中是不能进行调度的。
- 可以在持有信号量时去睡眠;因为当其他进程试图获得同一信号量时不会因此而死锁
- 占用信号量的同时不能占用自旋锁,否则睡眠时,会造成自旋锁的等待方的死锁。
10.4.1 计数信号量和二值信号量
信号量同时允许持有者数量可以在声明信号量是指定。每次持有一个则–i;释放一个++i。当i=1时,称为二值信号量(互斥信号量)。不为1时为计数信号量。其本质在于两个原子操作P()和V();现在系统将这两个操作称之为down()和up()。
10.4.2 创建和初始化信号量
信号量相关代码在文件asm/semaphore.h中。strcut semaphore表示信号量。声明方法如下:
/* 静态声明和初始化 */
struct semaphore name;
sema_init(&name,count);
/* 静态预定义初始化 */
static DECLARE_MUTEX(name);
/* 动态创建一个信号量 */
init_MUTEX(sem);
使用方法如下:
/* 定义并声明一个信号量 */
static DECLARE_MUTEX(mr_sem);
/* 尝试获取信号量 */
if(down_interruptible(&mr_sem)){
/* 信号被接受,信号量还未获取 */
}
/* 临界区 */
/* 释放给定的信号量 */
up(&mr_sem);

10.5 读写信号量
定义在linux/rwsem.h中;可以由static DECLARE_RWSEM(name)或者init_rwsem(struct rw_semaphore *sem)进行生成。
所有的读写信号量都是互斥信号量–引用计数等于1;但是只针对写者。
static DECLARE_RWSEM(mr_rwsem);
/* 试图获取信号量用于读 */
down_read(&mr_rwsem);
/* 只读临界区 */
/* 释放信号量 */
up_read(&mr_rwsem);
/* 试图获取写信号量 */
down_write(&mr_rwsem);
/* 写临界区 */
/* 释放信号量 */
up_write(&mr_sem);
10.6 互斥体
互斥体–一个更加简单的睡眠锁。指的是任何可以强制睡眠的强制互斥锁。初始化方法如下:
/* 静态定义 */
DEFINE_MUTEX(name);
/* 动态初始化 */
mutex_init(&mutex);
/* 互斥量加锁 */
mutex_lock(&mutex);
/* 临界区 */
mutex_unlock(&mutex);
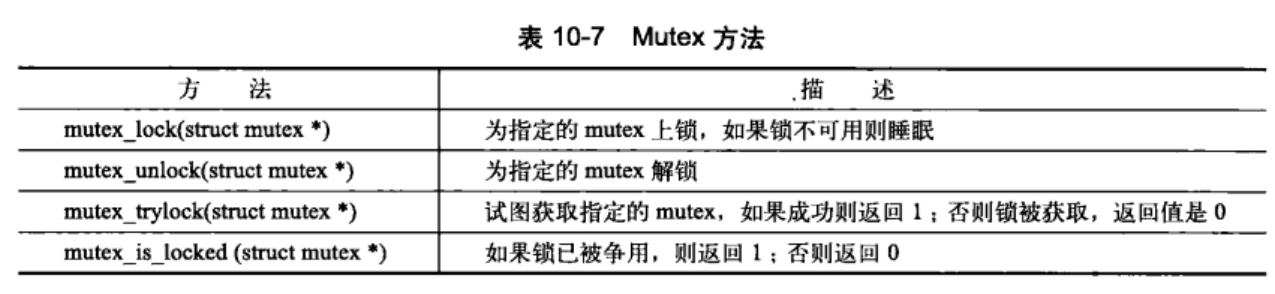
MUTEX的特性如下:
- 计数永远是1;任何时刻只有一个任务可以持有
- mutex上锁者必须负责给其解锁–必须在同一个上下文中。因此其不适合内核同用户空间的复杂同步场景;常用场景是:在同一上下文中上锁和解锁
- 递归地上锁和解锁是不允许的。不能递归的持有同一个锁。
- 当持有一个mutex时,进程不可以退出
- mutex不能在中断或者下半部分中使用;即使使用
mutex_tryolck()也不行 - mutex只能通过官方API管理;不可被拷贝、手动初始化或者重复初始化。
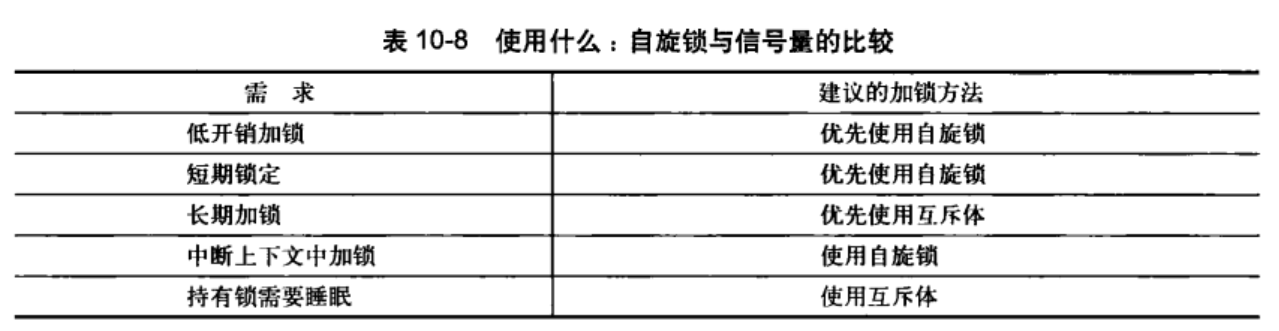
10.6.1 信号量和互斥体
建议首选mutex.
10.6.2 自旋锁和互斥体
10.7 完成变量
完成变量(completion variable):一个任务打出信号通知另外一个任务发生了某个特定事件;来完成两个任务的同步。例如vfork()系统调用完成时;使用完成变量唤醒父进程。其定义在linux/completion.h中。使用一下的方法进行初始化
DECLARE_COMPLETION(mr_comp);
init_completion(mr_comp);

10.8 BLK:大内核锁
BLK是一个全局自旋锁,主要是实现Linux最初的SMP过渡到细粒度加锁机制。其特性如下
- 持有它的任务仍然可以睡眠。当任务无法调度时(睡眠);锁被自动丢弃;调度时,锁重新获得
- 是一种递归锁,进程可以多次请求
- 只能在进程上下文中使用。
- 新用户不允许使用BLK
旧的接口,并不推荐使用。在被持有时会禁止内核抢占。单一处理器内核中,BKL并不执行实际的加锁操作

注意:自旋锁在单核处理器环境无效;编译器会自动优化取消它;防止锁因为上下文切换被获取,造成死锁.(为什么说“自旋锁在单处理器环境下无效”)
10.9 顺序锁
顺序锁简称seq锁。提供了简单是机制,用于读写共享数据。主要依靠一个序列计数器来实现。当有数据被写入时,会得到一个锁,并且顺序值会增加,在读取数据之前和之后,序列号都被读取。如果相同则过程没有被写操作打断过。如果是偶数就表明写操作没有发生(写操作会编程奇数,释放编程偶数)
使用方法如下:
/* 定义一个锁 */
seqlock_t mr_seq_lock=DEFINE_SEQLOCK(mr_seq_lock);
/* 写锁 */
write_seqlock(&mr_seq_lock);
write_sequnlock(&mr_seq_lock);
/* 读锁被操作 */
unsigned long seq;
do{
seq=read_seqbegin(&mr_seq_lock);
/* 读这里的数据 */
}while(read_seqretry(&mr_seq_lock,seq));
顺序锁使用与数据读者较多的情况;因为这样的校验机制,可以允许写者在能够抢占到对应的信号量。写着不像读写锁那样容易饿死。例如Linux中的jiffies变量存储了Linux机器启动到当前的时间。它的获取实际上就使用了顺序锁
u64 get_jiffies_64(void)
{
unsigned long seq;
u64 ret;
do{
seq=read_seqbegin(&xtime_lock);
ret=jiffies_64;
}while(read_seqretry(&xtime_lock,seq));
reurn ret;
}
/* 更改时间值操作 */
write_seqlock(&xtime_lock);
jiffies_64+=1;
write_sequnlock(&xtime_lock);
10.10 禁止抢占
内核是抢占性的;可能随时被停下来。因此一个任务与被抢占的任务可能会在同一个临界区内运行(新调度的任务可能访问被切换的同一个变量)。内核抢占代码使用自旋锁作为非抢占区域的标记。一个自旋锁被持有,内核便不能进行抢占。
可以通过preempt_disable()禁止内核抢占。直到preempt_enable()被启用之后才能重新启用。

也可以使用get_cpu()函数;这个函数在返回当前处理器号前首先会关闭内核抢占。
int cpu;
/* 禁止内核抢占,将cpu设置为当前处理器 */
cpu=get_cpu();
/* 对每个处理器的数据进行操作 */
/* 给于内核抢占性 */
put_cpu();
10.11 顺序和屏障
为了防止编译器对指令的乱序,可以屏障(barriers)保证代码顺序的固定执行。例如:rmb()提供一个“读”内存屏障。确保跨越rmb()的载入动作不会发生重排序–其之前的操作不会被重新排在该调用之后;之后的操作不会排在该调用之前。

注意:对于不同体系结构,屏障的实际效果差别很大。Intel x86 不执行乱序存储,wrmb()就什么都不做
第 11 章 定时器和时间管理
11.2 节拍率:HZ
系统定时器频率(HZ)是通过静态预处理定义的。体系结构的不同,HZ的值也不同。具体的值定义在<asm/param.h>中定义了这个值。注意大多数体系结构的节拍率是可以调节的。
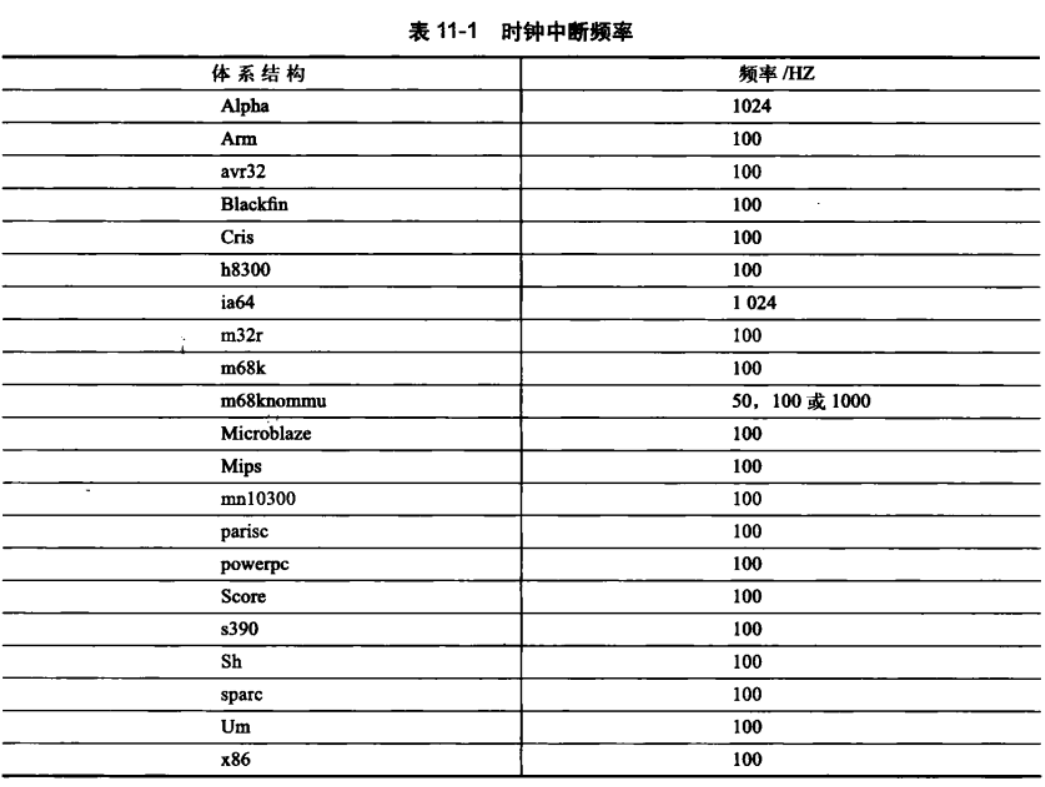
11.2.1 理想的HZ值
使用高频会让时钟中断产生的更加频繁;会给整个系统带来如下好处:
- 更高的时钟中断解析度;可以提高时间驱动时间的解析度
- 提高了时间驱动事件的准确度
- 执行时间有更高的运行精度
劣势:
- 系统负担过重;处理器需要花费大量的时间来处理中断程序。
- 打乱处理器高度缓存增加耗电。
可以在编译内核时,选择不同的时钟频率来指定不同的HZ值。也可以设置CONFIG_HZ配置选项让cpu根据动态时钟的周期来进行选择。
11.3 jiffies
参考链接:
这个变量用来记录自系统启动依赖产生的节拍的总数。启动时该变量初始化为0。没次时钟中断处理程序就会增加该变量的值。jiffies一秒内增加的值为HZ;系统运行时间为jiffies/HZ。其定义在文件linux/jiffies.h中:extern unsigned long volatile jiffies;
11.3.1 jiffies的内部表示
为了避免jiffies的溢出;使用了64位的数来对其进行存储;使用jiffies_64变量的初值覆盖jiffies变量:
jiffies=jiffies_64;
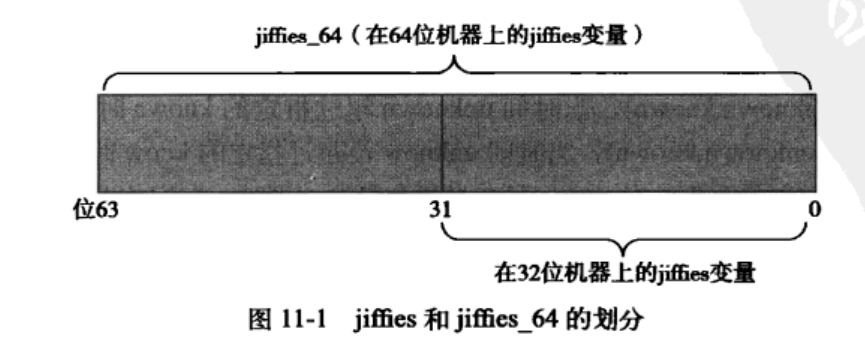
一般访问代码只会读取jiffies_64 的低32位。可以通过get_jiffies_64()函数读取整个64位数值。
11.3.2 jiffies 的回绕
当其变量的存储值超过它的最大范围之后会发生溢出。继续增加会恢复到0。注意当使用jiffies为比较标准作为判断时,可能因为发生回绕;造成其值为0,发生错误的判断;内核提供了对应的宏来处理这种判断:time_after、time_before、time_after_eq、time_before_eq
11.3.3 用户空间和HZ
为了避免内核中的HZ值更改,造成用户空间程序的异常结果;使用USER_HZ来代表用户空间看到的HZ值。通过一定的公式来进行计算;函数jiffies_64_to_clock_t()将64位的单位从HZ转换为USER_HZ。
11.4 硬时钟和定时器
操作系统提供了系统定时器和实时时钟。
11.4.1 实时时钟(RTC)
存放系统时间的设备,即便系统关闭之后,它也可以依靠主板上的微型电池提供电力保持系统的计时。系统启动时会读取RTC来初始化墙上时间,时间存在xtime中。
11.4.2 系统定时器
提供一种周期性触发中断机制(电子晶振分频或者衰减测量器)。x86体系结构中;主要采用可编程中断时钟(PIT)
11.5 时钟中断处理程序
时钟中断处理程序:
- 体系结构相关部分(硬件中断);主要内容如下:
- 获得xtime_lock锁,保护时间戳访问
- 应答或者重新设置系统时钟(需要时)
- 周期性地使用墙上时间更新实时时钟
- 调用体系结构无关的时钟例程:
tick_periodic()
- 体系结构无关部分(中断处理),使用
tick_periodic()执行下面的更多工作- 给jiffies_64变量增加1
- 更新资源消耗的统计值,比如当前进程所消耗的系统时间和用户时间
- 执行已经到期的动态定时器
- 执行sheduler_tick()函数
- 更新墙上时间,该时间存放在xtime变量中
- 计算平均负载值
11.6 实际时间
当前实际时间(墙上时间)定义在文件kernel/time/timekeeping.c中
struct timespec xtime;
timespec定义在文件<linux/time.h>中,形式如下:
struct timespec{
_kernel_time_t tv_sec /* 秒 */
long tv_nsec; /* ns */
}
xtime.tv_sec以秒为单位,存放着UTC以来经过的所有时间。其读写需要xtime_lock锁,它不是普通自旋锁而是一个seqlock锁。使用下面的代码进行时间的读取
unsigned long seq;
do{
unsigned long lost;
seq=read_seqbegin(&xtime_lock);
usec=timer->get_offset();
lost=jiffies-wall_jiffies;
if(lost)
usec+=lost*(1000000/HZ);
sec=xtime.tv_sec;
usec+=(xtime.tv_nsec/1000);
}while(read_seqretry(&xtime_lock,seq));
用户获得墙上时间的主要接口是gettimeofday();调用sys_gettimeofday()接口,定义于kernel/time.c
asmlinkage long sys_gettimeofday(struct timeval *tv,struct timezone *tz)
{
if(likely(tv)){
struct timeval ktv;
do_gettimeofday(&ktv);
if(copy_to_user(tv,&ktv,sizeof(ktv)))
return -EFAULT;
}
if(unlikely(tz)){
if(copy_to_user(tz,&sys_tz,sizeof(sys_tz)))
return -EFAULT;
}
return 0;
}
当输入参数非空时,其参数会进行调用。函数使用示例如下:
void sysUsecTime()
{
struct timeval tv;
struct timezone tz;
struct tm *p;
gettimeofday(&tv, &tz);
printf("tv_sec:%ld\n",tv.tv_sec);
printf("tv_usec:%ld\n",tv.tv_usec);
printf("tz_minuteswest:%d\n",tz.tz_minuteswest);
printf("tz_dsttime:%d\n",tz.tz_dsttime);
p = localtime(&tv.tv_sec);
printf("time_now:%d%d%d%d%d%d.%ld\n", 1900+p->tm_year, 1+p->tm_mon, p->tm_mday, p->tm_hour, p->tm_min, p->tm_sec, tv.tv_usec);
}
int main(void)
{
sysLocalTime();
printf("============gettimeofday==============\n");
sysUsecTime();
return 0;
}
11.7 定时器
定时器由结构timer_list表示,定义在文件<linux/timer.h>中
struct timer_list{
struct list_head entry; /* 定时器链表的入口 */
unsigned long expires; /* 以jiffies为单位的定时值 */
void (*function)(unsigned long) /* 定时器处理函数 */
unsigned long data; /* 传给处理函数的长整型参数 */
struct tvec_t_base_s *base; /* 定时器内部值,用户不要使用 */
}
定时器使用方法如下:
/* 创建定时器 */
struct timer_list my_timer;
/* 初始化内部定时器结构,分配内存 */
init_timer(&my_timer);
/* 预定义超时函数 */
void my_timer_function(unsigned long data);
/* 填充结构中需要的值 */
my_timer.expires=jiffies+delay /* 定时器超时时的节拍数 */
my_timer.data=0; /* 给定时器处理函数传入0值 */
my_timer.function=my_function; /* 定时器超时时函数的调用 */
/* 启动激活定时器 */
add_timer(&my_timer);
/* 更改定时器超时时间;设置新的定时器 */
mod_timer(&my_timer,jiffies+new_delay);
/* 删除定时器 */
del_timer(&my_timer);
/* 异步等待并删除定时器 */
del_timer_sync(&my_timer);
注意不要删除超时的定时器,它们会自动删除。del_timer()保证定时器不会被激活。但是对于多处理,需要使用del_timer_sync(&my_timer)来进行异步操作,等待其它核上的定时器的结束。
11.7.2 定时器条件竞争
因为定时器和当前执行代码的异步性,因此可能存在条件竞争;应该尽量使用del_timer_sync()取代del_timer()函数。
因为内核异步执行中断处理程序,所以应该重点保护定时器中断处理程序中的共享数据。
11.7.3 实现定时器
内核在时钟中断之后会执行定时器,更新当前时间。
void run_local_timers(void)
{
hrtimer_run_queues();
/* 执行定时器软中断 */
raise_softirq(TIMER_SOFTIRQ);
softlockup_tick();
}
执行中断,在当前处理器上运行所有的超定时器。为了提高定时器的搜索效率,内核将定时器按照超时时间划分为五组。当定时器超时时间接近时,定时器将随组一起下移。保证了定时器管理代码的高效性。
11.8 延迟执行
内核提供了许多延迟方法处理各种延迟要求。
11.8.1 忙等待
最简单的延迟方法,仅仅在延迟时间是节拍的整数倍,或者精确度要求不高时才可以使用。本质上是在循环中不断旋转直到希望的时钟节拍数耗尽
/* 10个节拍 */
unsigned long timeout=jiffies+10;
while(time_before(jiffies,timeout))
;
这个方法会消耗CPU资源,效率比较低,当等待时间较长时,应该尽量让任务挂起,允许内核重新执行调度任务。
unsigned long timeout=jiffies+5*HZ;
while(time_before(jiffies,timeout)){
/* 重新执行调度 */
cond_resched();
}
volatile 使得jiffies每次都直接从主内存中货色,不是通过寄存器中的变量别名来访问。从而确保前面的循环能按照预期的方式执行。
11.8.2 短延迟
时间很多(比时钟节拍还短)。并且对延迟的时间很精确。内核提供了下面单个延迟函数,定义在<linux/delay.h>和<asm/delay.h>中。并使用jiffies
/* 指定微妙(us)延迟 */
void udelay(unsigned long usecs);
/* 指定纳秒延迟 */
void ndelay(unsigned long nsecs);
/* 指定毫秒延迟 */
void mdelay(unsigned long msecs);
mdelay间接使用ndelay,ndelay使用udelay();udelay依靠执行次数循环达到延迟效果(由内核判断1s内执行多少次循环)。udelay更多的是根据循环的比例进行设置。
BogoMIPS:bogus(伪的)和MIPS(每秒处理百万指令);主要记录处理器空闲时的速度。该值存放在loop_per_jiffy中,可以由/proc/cpuinfo进行读取
内核在启动时利用calibrate_delay()计算loop_per_jiffy值。udelay()应当只在小延迟中调用,因为快速机器上的大延迟可能导致溢出。尽量减少使用mdelay以避免忙等待,消耗CPU资源。
11.8.3 schedule_timeout()
让延迟执行的任务睡眠到指定的延迟时间耗尽后再重新运行。主要是重新调度,因此该方法也不能保证睡眠时间正好等于指定的延迟时间,只能尽量靠近过。指定时间到达后,内核唤醒被延迟的任务并将其重新放回运行队列,用法如下:
/* 将任务设置为可中断睡眠状态 */
set_current_state(TASK_INTERRUPTIBLE);
/* 小睡一会儿,“s”秒后唤醒 */
schedule_timeout(s*HZ);
注意:
- 使用schedule_timeout任务之前,必须将其窗台设置为
TASK_INTERRUPTIBLE(可接受信号)或者TASK_UNINTERRUPTIBLE(不可接收信号)。 - schedule_timeout()需要调用调度程序,必须保证用时短,调用代码应该处于进程上下文中,并且不能持有锁。
- 可以使用
schedule_timeout()函数代替schedule()函数来,让任务等待某个特定事件的到来。
第 12 章 内存管理
内核的特性决定其内存分配,不像用空间那样简单,处理分配错误也是十分困难。
12.1 页
内核键页作为内存管理的基本单位。内存管理单元(MMU,管理内存并把虚拟地址转换为物理地址的硬件)是以页为氮气进行处理。虚拟内存中页是最小单位。
体系结构不同支持的页大小也不同,大多数32位体系结构支持4KB的页,64位支持8KB的页。4KB表示支持4KB大小页,并且有1GB物理内存的机器上,二级页表,物理内存会被划分为262144(2^18)个页。内核使用struct page结构表示系统中的每个物理页,位于linux/mm_types.h中。主要结构如下:
struct page{
/* 存放页的状态(是否为脏页)等 */
unsigned long flags;
/* 页被引用的次数统计,为-1时表示内核中没有引用这一页 */
atomic_t _count;
/* 页缓存引用数目 */
atomic_t _mapcount;
/* 私有数据指向 */
unsigned long priavte;
/* 指向页相关的地址空间 */
struct address_space *mapping;
pgoff_t index;
struct list_head lru;
/* 指向页的虚拟地址 */
void *virtual;
}
virtual域是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址。高端内存,并不是永久地映射到内核地址空间上。这时virtual值为NULL。需要时必须,动态映射这些页。
注意:
- page是与物理页相关而不是与虚拟页相关;内核仅仅用这个数据结构来描述当前时刻在相关的物理页中存放的东西
- 系统中的每个物理页都要分配一个这样的结构体。
12.2 区
参考连链接:
因为硬件的限制性,因此需要内核把页划分为不同的区(zone)。内核对具有相似特性的页来进行分组。Linux中主要处理的硬件缺陷内存寻址问题如下:
- 只能用特定的内存地址来执行DMA(直接内存访问)
- 一些体系结构的内存的物理寻址范围比虚拟寻址范围大的多。一些内存不能永久地映射到内核空间上。
针对上述问题,Linux主要使用了四种区:
- ZONE_DMA–区上页能用来执行DMA操作
- ZONE_DMA32–和ZONE_DMA相似,不过只能被32位设备访问。某些体系结构中该区比ZONE_DMA更大。
- ZONE_NORMAL–包含能正常映射的页。
- ZONE_HIGHMEM–包含“高端内存”,其中的页不能永久地映射到内核地址空间。
注意:不同体系结构上分区方式不同。
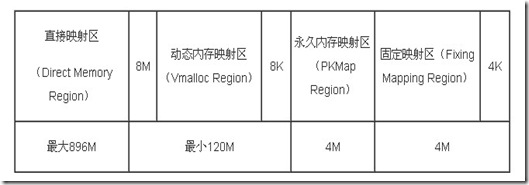
ZONE_HIGHMEM的工作方式也差不多。在32位x86系统上,其为高于869MB的所有物理内存。其它体系结构上,其ZONE_HIGHMEM为空。

内核又将3~4G的虚拟地址空间,划分为如下几个部分:

896MB又可以细分为ZONE_DMA和ZONE_NORMAL区域.
- 低端内存(ZONE_DMA):3G-3G+16M 用于DMA __pa线性映射
- 普通内存(ZONE_NORMAL):3G+16M-3G+896M __pa线性映射 (若物理内存<896M,则分界点就在3G+实际内存)
- 高端内存(ZONE_HIGHMEM):3G+896-4G 采用动态的分配方式
ZONE_DMA+ZONE_NORMAL属于直接映射区:虚拟地址=3G+物理地址 或 物理地址=虚拟地址-3G,从该区域分配内存不会触发页表操作来建立映射关系。
ZONE_HIGHMEM属于动态映射区:128M虚拟地址空间可以动态映射到(X-896)M(其中X位物理内存大小)的物理内存,从该区域分配内存需要更新页表来建立映射关系,vmalloc就是从该区域申请内存,所以分配速度较慢。
直接映射区的作用是为了保证能够申请到物理地址上连续的内存区域,因为动态映射区,会产生内存碎片,导致系统启动一段时间后,想要成功申请到大量的连续的物理内存,非常困难,但是动态映射区带来了很高的灵活性(比如动态建立映射,缺页时才去加载物理页)。
整体映射关系如下:
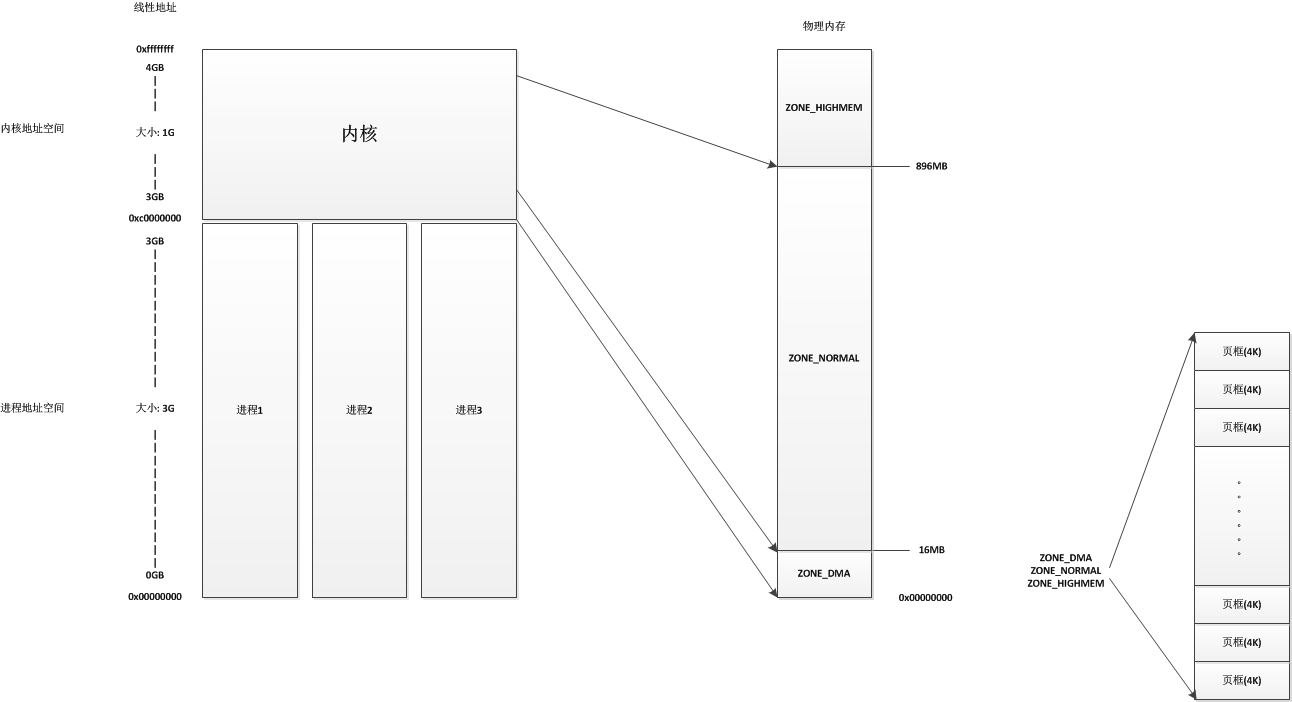
内核将物理内存等分成N块4KB,称之为一页,每页都用一个struct page来表示。
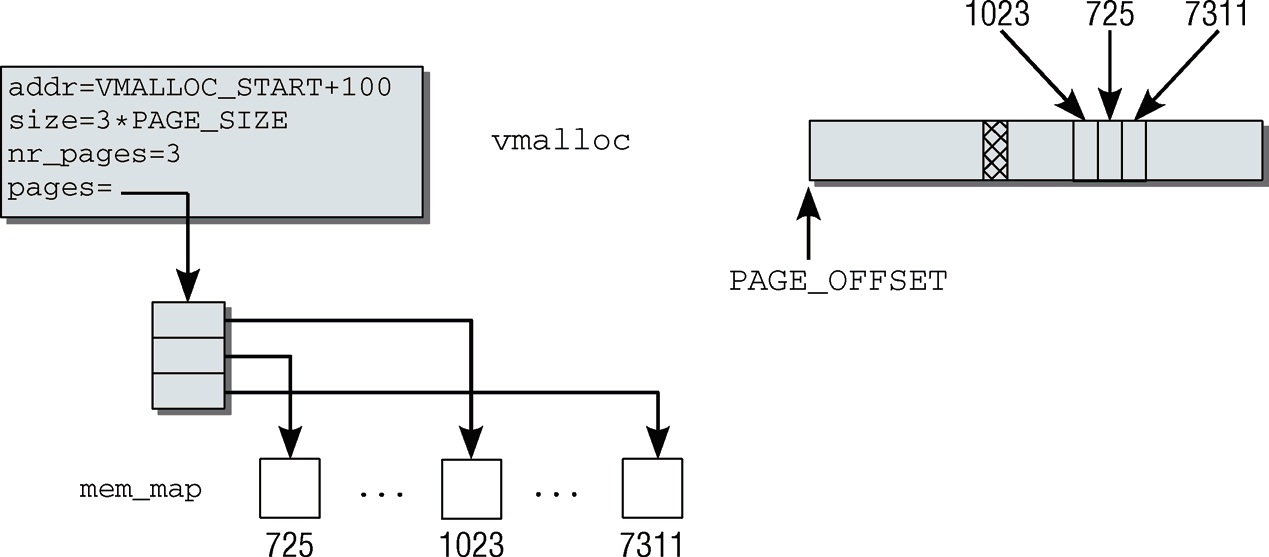
下图是通过vmalloc申请了3个page大小的内存示例图,由此可见该区域是虚拟地址连续,物理地址不一定连续:
alloc_page和__get_free_page最终都是调用的同一个子函数:
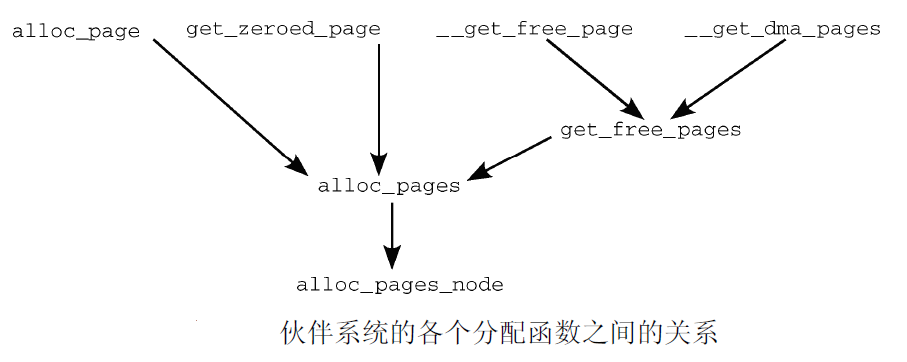
- kmalloc: 只能在低端内存区域分配(基于ZONE_NORMAL),最大32个PAGE,共128K,kzalloc/kcalloc都是其变种 (slab.h中如果定义了KMALLOC_MAX_SIZE宏,那么可以达到8M或者更大)
- vmalloc: 只能在高端内存区域分配(基于ZONE_HIGHMEM)
- alloc_page: 可以在高端内存区域分配,也可以在低端内存区域分配,最大4M(2^(MAX_ORDER-1)个PAGE)
- __get_free_page: 只能在低端内存区域分配,get_zeroed_page是其变种,基于alloc_page实现
- ioremap是将已知的一段物理内存映射到虚拟地址空间,物理内存可以是片内控制器的寄存器起始地址,也可以是显卡外设上的显存,甚至是通过内核启动参数“mem=”预留的对内核内存管理器不可见的一段物理内存。
kmalloc和vmalloc申请的内存块大小是以字节为单位(实际上考虑到最小细分度,开辟的可能比申请的多,存在些许浪费),而__get_free_page申请的内存块大小是以PAGE数量为单位。
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
/*
* __get_free_pages() returns a 32-bit address, which cannot represent
* a highmem page
*/
VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0);
page = alloc_pages(gfp_mask, order);
if (!page)
return 0;
return (unsigned long) page_address(page);
}
由上可见,__get_free_pages不能为带__GFP_HIGHMEM标志的请求分配内存。
kmalloc和__get_free_page函数返回的地址都是虚拟地址,和物理地址只差一个固定的偏移值3G,无需操作页表。 alloc_page返回的是第一个物理页的page指针,需要经过page_address函数才能取得虚拟地址。 (使用alloc_page(s)在高端内存申请大于1个page的内存,就无法保证物理地址上的连续性)
kmalloc基于slab实现的,slab是为分配小内存提供的一种高效机制(slab会把page再细分成更小的颗粒)

大页: 如果进程太多,页表数据会非常大,此时可以把默认的页大小由4K改为2M或者更大。
如果想要实现大数据DMA,可以用kmalloc申请N个buffer,用SG DMA(非SG的叫Block DMA)技术传输
有些64位体系结构,如Intel的x86-64体系结构可以映射和处理64位的内存空间。因此x86_64没有ZONE_HIGHMEM区,所有的物理内存都处于ZONE_DMA和ZONE_NORMAL区。用户空间默认从高端内存分配所需内存,虽然x86_64没有高端内存也没有关系,内核设计了适当的回退机制,用户空间一样可以在低端内存分配内存,只不过需要二次映射,浪费一点效率。
拓展:关于64位的内存分配
参考链接:
在 x86-64 下,处理器默认 CS, DS, ES, SS的段基址为 0,所以下面就不讨论逻辑地址到线性地址的转换了,因为基址为0,经过运算后线性地址和逻辑地址是一样的。
分页过程会将48-bit的线性地址转换为52-bit的物理地址, 可以看出虽然是64bit的操作系统但在处理器层面并没有提供2^64大小的访问范围.48-bit 线性地址可以有以下 3 种映射分配
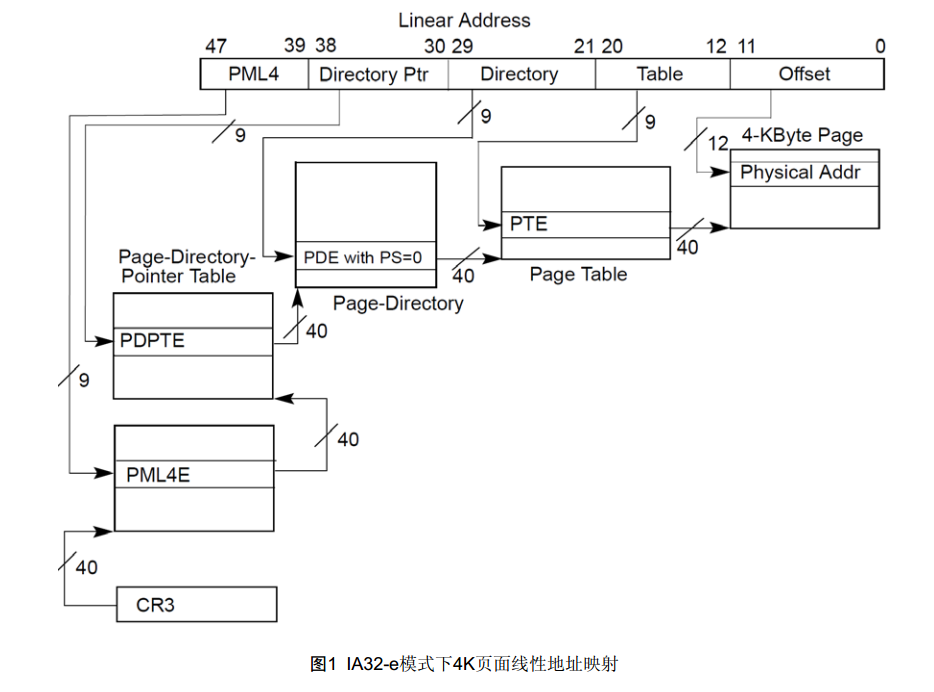
x86_64线性地址不是64bit,物理地址也不是64位,Intel当前CPU最高物理地址是52bit,但实际支持的物理内存地址总线宽度是40bit。x86CPU仅支持64位虚拟地址中的48位。对于用户模式地址,64位中的虚拟地址高16位的地址总被设置为0x0;对于内核模式地址,总被设置为0xF.
这是因为x86_64处理器地址线只有48条,故而导致硬件要求传入的地址48位到63位地址必须相同。

64位地址采用4层地址映射,如下图:

pgd、pud、pmd、pte各占了9位,加上12位的页内index,共用了48位。即可管理的地址空间为2^48=256T。而在32位地址模式时,该值仅为2^32=4G。
另外64位地址时支持的物理内存最大为64T,见e820.c中MAX_ARCH_PFN的定义:
#define MAX_ARCH_PFN MAXMEM>>PAGE_SHIFT
其中MAXMEM为2^46,PAGE_SHIFT为12。
而在32位地址时最大支持的物理内存为64G(开启PAE选项)。
相对32位地址空间,64位地址空间的具体地址分布如下:
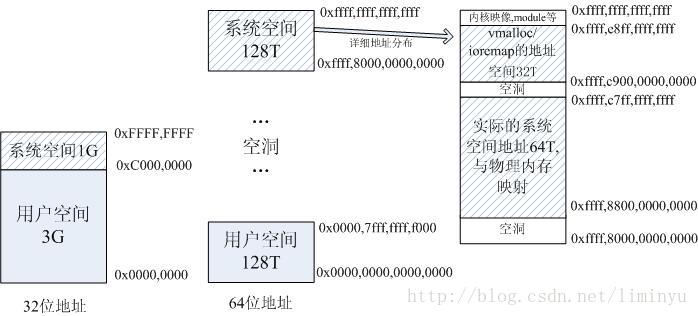
64位地址时将0x0000,0000,0000,0000 – 0x0000,7fff,ffff,f000这128T地址用于用户空间。参见定义:
#define TASK_SIZE_MAX ((1UL<<47)-PAGE_SIZE);注意这里还减去了一个页面的大小做为保护。
而0xffff,8000,0000,0000以上为系统空间地址。注意:该地址前4个都是f,这是因为目前实际上只用了64位地址中的48位(高16位是没有用的),而从地址0x0000,7fff,ffff,ffff到0xffff,8000,0000,0000中间是一个巨大的空洞,是为以后的扩展预留的。
而真正的系统空间的起始地址,是从0xffff,8800,0000,0000开始的,参见:
#define __PAGE_OFFSET _AC(0xffff,8800,0000,0000, UL)
而32位地址时系统空间的起始地址为0xC000,0000。
另外0xffff,8800,0000,0000 – 0xffff,c7ff,ffff,ffff这64T直接和物理内存进行映射,0xffff,c900,0000,0000 – 0xffff,e8ff,ffff,ffff这32T用于vmalloc/ioremap的地址空间。
而32位地址空间时,当物理内存大于896M时(Linux2.4内核是896M,3.x内核是884M,是个经验值),由于地址空间的限制,内核只会将0~896M的地址进行映射,而896M以上的空间用做一些固定映射和vmalloc/ioremap。而64位地址时是将所有物理内存都进行映射。

其中每个区都用strcut zone表示,在<linux/mmzone.h>中定义:
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long _watermark[NR_WMARK];
unsigned long watermark_boost;
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*/
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
unsigned long compact_init_migrate_pfn;
unsigned long compact_init_free_pfn;
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
其中的lock域是一个自旋锁,它防止该结构被并发访问。但它只保护结构,不是保护驻留在这个区中的所有页;没有锁来保护单个页。
watermark数组持有该区的最小值、最低和最高水平值。内核使用水位为每个内存区设置合适的内存消耗基准;该值随着空闲内存的多少而变化。
name域是一个以NULL结束的字符串表示这个区的名字。内核启动期间初始化这个值,其代码位于mm/page_alloc.c中。
12.3 获得页
内核中存在请求内存符底层机制,并提供了对它进行访问的接口。以页为基本单位,进行保存。定义在linux/gfp.h中,其中的核心函数是:
/* 分配2^order个连续的物理页,并返回一个指针,指向第一个页的page结构体,如果出错就返回NULL */
struct page *alloc_pages(gfp_t gfp_mask,unsigned int order);
/* 将页的物理地址转换为逻辑地址,返回指向逻辑地址的指针 */
void *page_address(struct page *page);
/* 直接创建并返回第一个页的逻辑地址 */
unsigned long __get_free_pages(gfp_t gfp_mask,unsigned int order);
/* 获取单个页 */
struct page *alloc_page(gfp_t gfp_mask);
unsigned long __get_free_page()gfp_t gfp_mask);
/* 返回页内容全为0 */
unsigned long get_zeroed_page(unsigned int gfp_mask);

12.3.2 释放页
可以使用如下函数进行页的释放
void __free_pages(struct page *page,unsigned int order)
void free_pages(unsigned long addr,unsigned int order)
void free_page(unsigned long addr)
页的释放错误可能会引起内核的崩溃。
12.4 kmalloc()
其在<linxu/slab.h>中声明;可以获取以字节为党文的一块内核内存。
void *kmalloc(size_t size,gfp_t flags)
12.4.1 gfp_mask标志
页和内存的分配都使用了分配器标志,它有一下三类:
-
行为修饰符:内核应当如何分配所需的内存

 可以同时多个指定:
可以同时多个指定:ptr=kmalloc(size,__GFP_WAIT|__GFP_IO|GFP_FS) - 区修饰符:从那儿进行内存分配。
 注意:
注意:
-
__GFP_HIGHMEM中ZONE_HIGHMEM优先 - 如果没有任何指定,就优先从
ZONE_NORMAL进行分配。 - 不能给
__get_free_pages()或者kmalloc()指定ZONE_HIGHMEM.其返回的是逻辑地址不是page结构,只有alloc_pages()才能分配高端内存
-
- 类型标志:组合了行为修饰符和区修饰符。

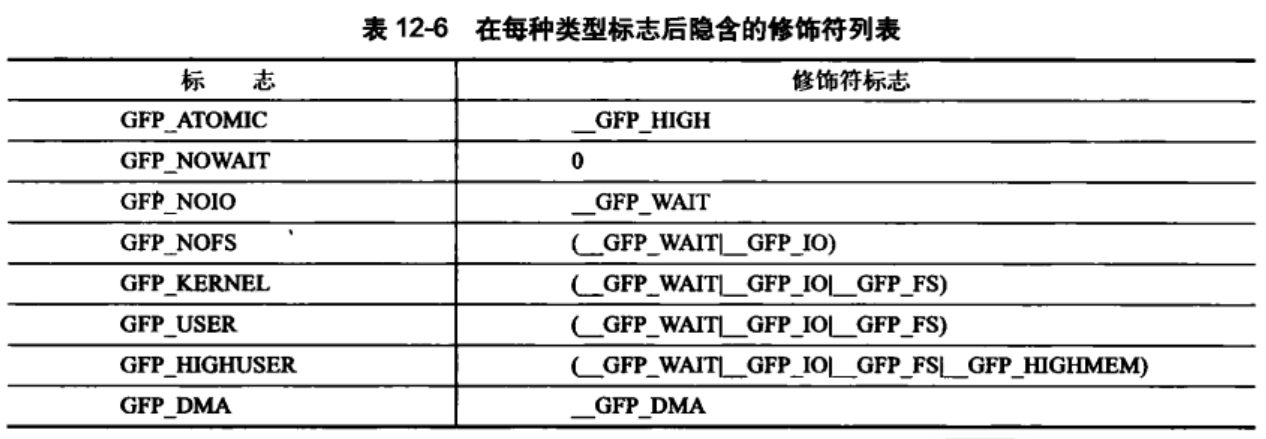
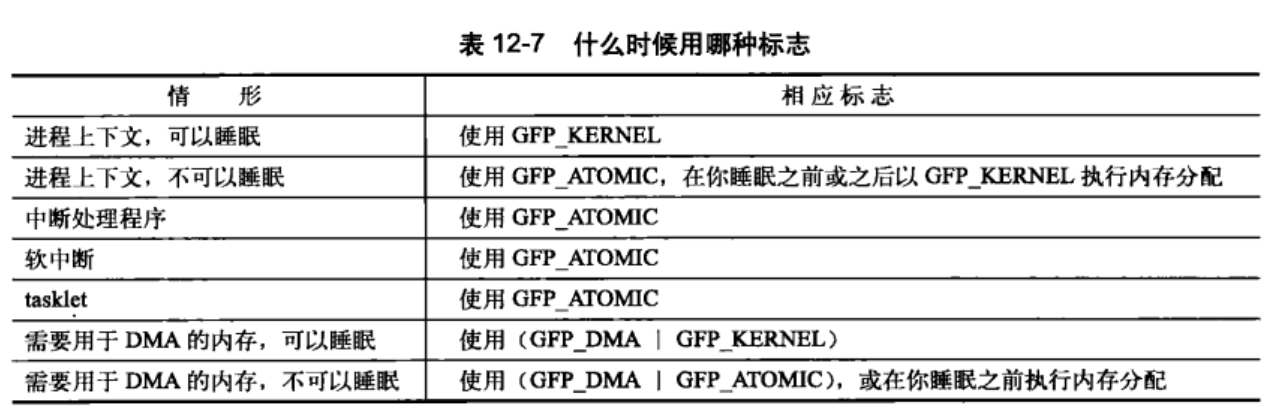
不能睡眠表示,即使没有足够的连续内存块可以使用,内核也可能无法释放出可用内存,因为内核不能让调用者休眠。因此GFP_ATOMIC分配成功的机会比较小。在中断处理程序、软中断和tasklet中使用较多。
12.4.2 kfree()
定义在<linux/slab.h>中
void kfree(const void *ptr);
释放内存已经被释放或者不是由kmalloc分配的将会引起严重后果。注意使用避免内存泄露。
12.5 vmalloc()
vmalloc()主要是逻辑地址的分配,物理内存可能不连续。这也是用户空间分配函数的工作方式。其在物理RAM中不是需要连续的。vmallo()的性能较低,需要对物理地址进行一一映射。会导致比直接内存映射大得多的TLB抖动。使用示例
char* buf;
buf=vmalloc(16*PAGE_SIZE);/* get 16 pages */
if(!buf)
...
vfree(buf);
12.6 slab层
参考链接:
slab层主要作为数据结构高速缓冲层的角色;能方便开发人员随时获取空闲的链表。
Linux内核中基于伙伴算法实现的分区页框分配器适合大块内存的请求,它所分配的内存区是以页框为基本单位的。对于内核中小块连续内存的请求,比 如说几个字节或者几百个字节,如果依然分配一个页框来来满足该请求,那么这很明显就是一种浪费,即产生内部碎片(internal fragmentation)
为了解决小块内存的分配,Linux内核基于Solaris 2.4中的slab分配算法实现了自己的slab分配器。除此之外,slab分配器另一个主要功能是作为一个高速缓存,它用来存储内核中那些经常分配并释放的对象。
slab分配器有以下三个基本目标:
-
减少伙伴算法在分配小块连续内存时所产生的内部碎片;
-
将频繁使用的对象缓存起来,减少分配、初始化和释放对象的时间开销。
-
通过着色技术调整对象以更好的使用硬件高速缓存;
12.6.1 slab层的设计
slab将不同的对象划分为所谓的高速缓存组,其中每个缓存组都存放不同类型的对象。每种对象类型对应一个高速缓存。kmalloc()建立在slab层之上,使用了一组通用高速缓存
高速缓存被划分为slab,一个slab由一个或者多个连续的物理页组成。每个高速缓存由多个slab组成。每个slab包含一些对象成员(被缓存的数据结构)。当内核需要分配一个新的对象时,先从部分满的slab中进行分配。实在找不到就重新分配一个。
磁盘索引节点在内存中由inode进行管理,其由slab进行分配。
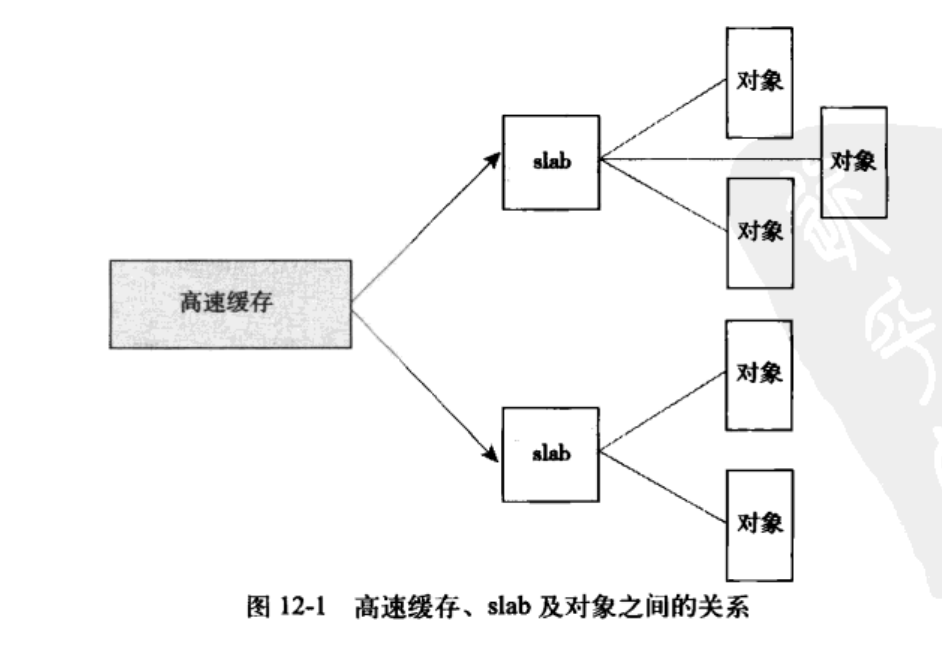
每个高速缓存都使用kmem_cache结构来表示。这个包含三个链表:slabs_full、slabs_partial和slab_empty;存放在kmem_list3(定义于mm/slab.c)结构中.其基本数据结构如下:
struct slab{
/* 链表连接节点 */
struct list_head list;
/* slab着色的偏移量 */
unsigned long colouroff;
/* slab中的第一个对象 */
void *s_mem;
/* slab中已分配的对象数 */
unsigned int inuse;
/* 第一个空闲对象(如果有的话) */
kmem_bufctl_t free;
}
slab分配器可以通过__get_free_pages()创建新的slab

高速缓存分类
- 普通高速缓存:普通高速缓存并不针对内核中特定的对象,它首先会为kmem_cache结构本身提供高 速缓存,这类缓存保存在cache_cache变量中,该变量即代表的是cache_chain链表中的第一个元素。
- 专用高速缓存:是根据内核所需,通过指定具体的对象而创建。
12.6.2 slab分配器的接口
每个高速缓存通过kmem_cache结构来描述,这个结构中包含了对当前高速缓存各种属性信息的描述。所有的高速缓存通过双链表组织在一起,形成 高速缓存链表cache_chain。
slab分配器所提供的小块连续内存的分配是通过通用高速缓存实现的。通用高速缓存所提供的对象具有几何分布的大小,范围为32到131072字节。内核中提供了kmalloc()和kfree()两个接口分别进行内存的申请和释放。
kmem_cache_create()用于对一个指定的对象创建高速缓存。它从cache_cache普通高速缓存中为新的专有缓存分配一个高速 缓存描述符,并把这个描述符插入到高速缓存描述符形成的cache_chain链表中。kmem_cache_destory()用于撤销一个高速缓存, 并将它从cache_chain链表上删除。
一个新的高速缓存通过一下函数创建
struct kmem_cache *kmem_cache_create(
const char *name,/* 高速缓存名称 */
size_t size, /* 高速缓存中每个元素的大小 */
size_t align,/* slab内第一个对象的偏移,保证页内对齐 */
unsigned long flags,/* 可选设置项,用来控制高速缓存的行为 */
void (*ctor)(void *)/* 高速缓存构造函数,添加高速缓存时才被调用一般为NULL */
)
flags可选参数如下:
-
SLAB_HWCACHE_ALIGN–命令slab层把一个slab内的所有对象按照高速缓存对齐。防止“错误的共享”。以浪费内存为待见,进行性能的提升。 -
SLAB_POISON–使用已知的值填充slab,有利于对为初始化内存的访问。 -
SLAB_RED_ZONE–slab层在已分配的内存周围插入“红色警戒区”以探测缓冲越界。 -
SLAB_PANIC–当分配失败时提醒slab层。 -
SLAB_CHACHE_DMA–表示命令slab层使用可以执行DMA的内存给每个slab分配空间。只有分配DMA对象并且必须驻留在ZONE_DMA区时才需要这个标志。
内核初始化期间,定义于kernel/fork.c的fork_init()中会创建高速缓存.
删除一个高速缓存
int kmem_cache_destroy(struct kmem_cache *cachep);
创建高速缓存后可以,通过下列函数获取对象:
-
void kmem_cache_alloc(struct kmem_cache *cachep,gfp_t flags),查找空闲页,没有slab就自己分配一个。 -
void kmem_cache_free(struct kmem_cache *cachep,void *objp):释放一个对象
下面是一个使用示例:
/* 定义全局变量存放高速缓存指针 */
struct kmem_cache *task_struct_cachep;
/* 创建一个task_struct类型的高速缓存,存放在ARCH_MIN_TASKALIGH个字节偏移的地方 */
task_struct_cachep=kmem_cache_create("task_struct",
sizeof(struct task_struct),
ARCH_MIN_TASKALIGH,
SLAB_PANIC|SLAB_NOTRACK,
NULL
);
/* 定义数据结构 */
struct task_struct *tsk;
/* 从高速缓存中获取对象 */
tsk=kmem_cache_alloc(task_struct_cachep,GFP_KERNEL);
if(!tsk) return NULL;
/* 销毁对象,并将内存返回给高速缓存 */
//kmem_cache_free(task_struct_cachep,tsk);
/* 防止被破坏,阻止其被撤销 */
int err;
err=kmem_cache_destroy(task_struct_cachep);
if(err) /* 出错,撤销高速缓存 */
12.7 在栈上的静态分配
内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。
当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;
当进程在内核空间运行时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。 进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信心,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
每个进程的内核栈大小既依赖于体系结构,也与编译选项有关。一般每个进程都用两页(32位8KB,64位16KB)的内核栈。
12.7.1 单页内核栈
内核栈可以是1页也可以是2页,取决于编译时的配置选项。
12.7.1 在栈上光明正大的工作
因为thread_info在栈末端,栈溢出是会损害这个数据,进行动态分配(new)是比较适用于大块内存的分配。动态分配内存是一种明智的选择。
12.8 高端内存的映射
高端内存的页不能永久地映射到内核地址空间上。因此,通过alloc_pages()函数以__GFP_HIGHMEM标志获得的页不可能有逻辑地址。
12.8.1 永久映射
使用void *kmap(struct page *page)函数映射给定的page到内核地址空间。如果是低端则会返回该页的虚拟地址;如果是高端则会建立一个永久映射,再返回地址。函数可以睡眠。可以使用void kunmap(struct page *page)解除对应的映射。
12.8.2 临时映射
参考链接: Linux kmap和kmap_atomic解析;高端内存映射之kmap_atomic固定映射–Linux内存管理(二十一) ;linux内存映射
kernel 可以原子地映射一个高端内存页到 kernel 中的保留映射集中的一个,此保留映射集也是专门用于中断上下文等不能睡眠的地方映射高端内存页的需要。
临时映射,不能睡眠,绝对不会阻塞;通过下列函数建立一个临时映射:
/* 建立临时映射 */
void *kmap_atomic(struct page *page,enum km_type type);
/* 同下列函数取消映射 */
void kunmap_atomic(void *kvaddr,enum km_type type);
kernel可以在多个cpu上同时运行不同的task,然而它们共同使用一个内存地址空间,也就是说,地址空间对于多个cpu看到的是同一个,kmap_atomic使用的是地址空间顶部的一小段地址空间,内核逻辑将这一小段地址空间分成了若干个节,每一节的大小是一个page的大小,可以用来映射一个page,根据公用地址空间的原理,所有的cpu共同使用这些节,因此如何能保证N个cpu调用kmap_atomic不会将page映射到一个地址呢?这就是这个数学公式所起的作用: idx = type + KM_TYPE_NR*smp_processor_id(); vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx); 其中KM_TYPE_NR代表type的最大值加1:
12.9 每个CPU的分配
每个CPU上的数据,对于给定的处理器其数据是唯一的。每个CPU的数据存放在一个数组中。数组中的每一项对应着系统上一个存在的处理器。按照当前处理器号确定这个数组的当前元素。访问数据的方式如下:
int cpu;
/* 获取当前处理器,并禁止内核抢占 */
cpu=get_cpu();
/* 获取数据 */
my_percpu[cpu]++;
printk("my_percpu on cpu=%d is %lu\n",cpu,my_percpu(cpu));
/* 激活内核抢占 */
put_cpu();
12.10 新的每个CPU接口
参考链接: linux percpu机制解析;Linux内核同步机制之(二):Per-CPU变量
操作系统创建percpu接口定义在linux/percpu.h中;声明了所有的接口操作例程,可以在文件mm/slab.c和asm/percpu.h中找到他们的定义。
12.10.1 编译时每个CPU数据
/* 定义每个CPU变量 */
DEFINE_PER_CPU(type,name);
/* 声明变量 */
DECLARE_PER_CPU(type,name);
/* 返回当前cpu的值并++ */
get_cpu_var(name)++;
/* 增加指定处理器上的数据 */
per_cpu(name,cpu)++;
/* 完成,重新激活内核抢占 */
put_cpu_var(name);
注意:per_cpu函数既不会禁止内核抢占,也不会提供任何形式上的锁。
12.10.2 运行时的每个CPU数据
相关原型定义在文件linux/percpu.h中
/* 宏为,系统中的每个处理器分配一个指定类型对象的实例 */
void *allocate_perccpu(type);
void *__alloc_percpu(size_t size,size_t align);
/* 释放内存 */
void free_percpu(const void *);
下面是一个简单的使用
void *percpu_ptr;
unsigned long *foo;
percpu_ptr=alloc_precpu(unsigned long);
if(!ptr)
/* 内存分配错误... */
foo=get_cpu_var(percpu_ptr);
/* 操作foo ... */
/* 重新释放锁 */
put_cpu_var(percpu_ptr);
12.11 使用每个CPU数据的原因
可以有效减少,数据锁定。方便梳理器快速访问内存。
12.12 分配函数的选择
需要连续物理内存,可以使用某个低级页分配器或者kmalloc();
高端内存分配,使用alloc_pages()
虚拟内存使用vmalloc()函数