2019-11-02 20:25:49
Linux内核设计与实现 学习笔记 (四)
CPU内存管理总结
1. x86/x64处理器体系结构寻址模式
参考链接:
1.1 处理器体系结构
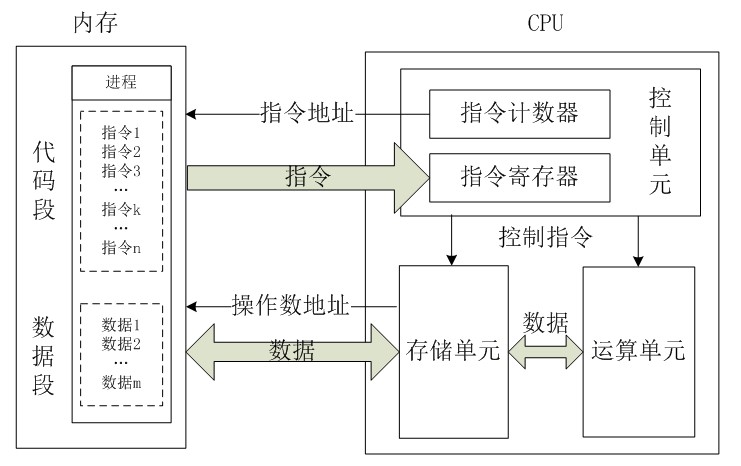
CPU处理器的主要结构如下:
- 控制单元:控制单元是整个CPU的指挥控制中心,由指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC(Operation Controller)等,对协调整个电脑有序工作极为重要。
- 运算单元:是运算器的核心。可以执行算术运算(包括加减乘数等基本运算及其附加运算)和逻辑运算(包括移位、逻辑测试或两个值比较)。相对控制单元而言,运算器接受控制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来指挥的,所以它是执行部件。
- 存储单元:包括CPU片内缓存和寄存器组,是CPU中暂时存放数据的地方,里面保存着那些等待处理的数据,或已经处理过的数据,CPU访问寄存器所用的时间要比访问内存的时间短。采用寄存器,可以减少CPU访问内存的次数,从而提高了CPU的工作速度。
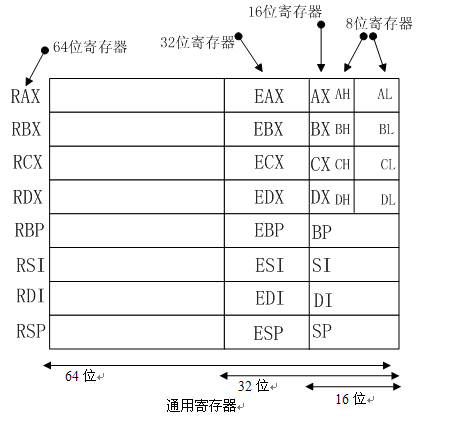
1.1.2 寄存器结构
在之前的文章C/C++ 的一个符号操作问题中也介绍过,寄存器的类别和基本结构.其主要结构如下图所示:
专用寄存器:

以上所列出的一些通用寄存器(注:其中RSP为专用寄存器,之所以把它放在通用寄存器组中只是为了方便记忆整个模型),除了数据位宽度不同之外,并无多大差别:
- RAX(累加器):RAX如果是8/16/32位寻址,则只改变该寄存器的一部分。累加器用于乘法、除法及一些调整指令,同时也可以保存存储单元的偏移地址。
- RBX(基址):用于保存存储单元的偏移地址,同时也能寻址存储器数据,作为偏移地址访问数据时默认使用数据段基址DS作为段前缀。
- RCX(计数):可保存访问存储单元的偏移地址,或在串指令(REP/REPE/REPNE)以及移位、循环和LOOP/LOOPD指令中用作计数器。
- RDX(数据):可使用RDX/EDX/DX/DH/DL寻址,同时作为通用寄存器也用于保存乘法形成的部分结果或者除法之前的部分被除数,也可用于寻址存储单元。
- RBP(基指针):可用RBP/EBP/BP寻址,同时作为偏移地址访问存储单元时默认使用堆栈段基址SS作为段前缀。
- RDI(目的变址):可用RDI/EDI/DI寻址,常用于在串指令中寻址目的数据串。
- RSI(源变址):如RDI一样,RSI也可作为通用寄存器使用,通常为串指令寻址源数据串。
段寄存器CS、DS、ES、SS、FS、GS以及RSP为专用寄存器,以下是这些寄存器的概要描述:
- RSP(堆栈指针):RSP寻址称为堆栈的存储区,通过该指针存取堆栈数据。用作16位寄存器时使用SP,如果是32位则为ESP。
- CS(代码段):代码段寄存器存放程序所使用的代码在存储器中的基地址。 • DS(数据段):存放数据段的基地址
- ES(附加段):该段寄存器通常在串指令(LODS/STOS/MOVS/INS/OUTS)中使用,主要用于在存储器中将数据进行成块转移。
- SS(堆栈段):为堆栈定义一个存储区域。主要用来存放过程调用所需参数、本地局部变量以及处理器状态等。
- FS与GS:这两个段寄存器是386~Core2中新增的段寄存器,以允许程序访问附加的存储器段。可以将其视为“通用的段寄存器”,通过将段的基地址存入这两个寄存器中可以实现自定义的寻址操作,从而增加了编程的灵活性。
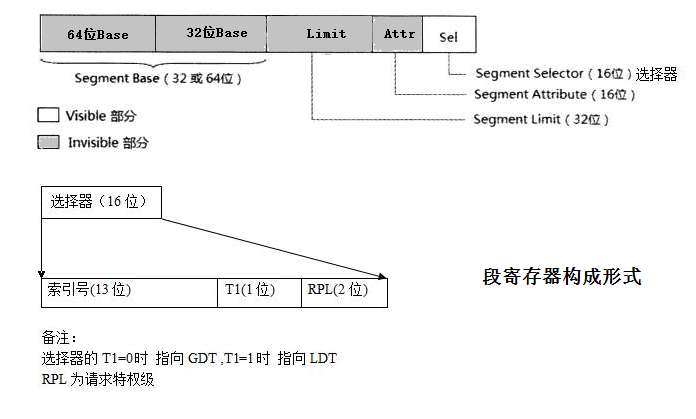
每一个寄存器都有一个”可见”部分和一个”隐藏”部分。(这个隐藏部分有时也指一个”描述符缓存”(descriptor cache)或者”阴影寄存器”(shadow register))。当一个段选择器被加载到段寄存器的可见部分,处理器也会自动把基址,段界限,和段描述符中的访问控制信息加载到段寄存器的隐藏部分。把信息缓存在段寄存器(可见和隐藏部分)允许处理器不经过额外的总线循环(bus cycles)去段描述符总读取基址和界限来转换地址。当描述符表发生了更改,软件有义务重新加载段寄存器。如果不这样做,段寄存器中使用的老段描述符还是会继续使用。
1.1.3 地址总线
参考链接: CPU的设计原理,数据总线和地址总线;
RIP寻址代码段中当前执行指令的下一条指令,当处理器工作在实模式下时使用16位的IP寄存器,当工作于保护模式时则使用32位的EIP。指令指针可由转移指令或调用指令修改。需要注意的是,在64位模式中由于处理器包含40位地址总线,所以总共可以寻址240=1TB的内存。 具体的地址总线数目需要看CPU的设计,linux操作系统最多支持48根地址总线。
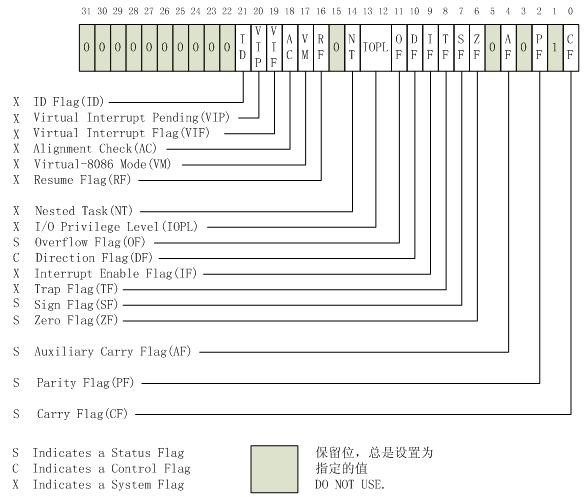
EFLAGS(program status and control) register主要用于提供程序的状态及进行相应的控制,在64-bit模式下,EFLGAS寄存器被扩展为64位的RFLGAS寄存器,高32位被保留,而低32位则与EFLAGS寄存器相同。
1.2 处理器工作及寻址模式
对于实际的内存条而言,处理器把它当做8位一个字节的序列来管理和存取(内存对齐的原因),每一个内存字节都有一个对应的地址,我们叫它物理地址,用地址可以表示的长度叫做寻址空间。而CPU是如何去访问内存单元里的数据的方式就叫做寻址。
-
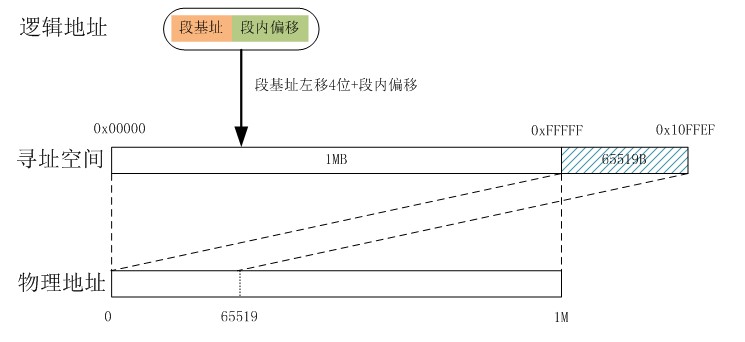
实模式:即“段地址”+“段内偏移量”,它们分别由段寄存器+通用寄存器,保存,即基址+变址的方式进行寻址。例如,ES=0x1000,DI=0xFFFF,那么这个数据ES:DI在内存里的绝对物理地址就是:
AD(Absolute Address)=(ES)*(0x10)+(DI)=0x1FFFF。早期低位计算机中使用。但是因为物理内存的短缺,使用将使用空闲的物理地址重复映射(用户空间的原型??).现代计算机为了兼容性,基本都运行在这个实模式下,但是数据容易被病毒木马等进行修改。 - 保护模式(IA-32模式):硬件CPU引入的地址保护的概念。并使用段页描述方式。增加了GDTR (global descriptor talbe register)指向全局段描述符数组(表);LDTR (localdescriptor table register)执行局部段描述符数组(表)而6个段寄存器,CS/DS/SS/ES包括后来的FS/GS,其内容不在用作基址,而是用作索引去段描述符数组中查找对应的段描述符。段描述符占8个字节,其定义以及其中各个标志位的定义如下:
-
下表为Linux内核对段描述符的典型设置方式:
| 段 | 基地址 | G | 界限 | S | TYPE | DPL | D | P | |
|---|---|---|---|---|---|---|---|---|---|
| 用户代码段 | 0x0000 | 0000 | 1 | 0xF | FFFF | 1 | 10(0x1010) | 3 | 1 |
| 用户数据段 | 0x0000 | 0000 | 1 | 0xF | FFFF | 1 | 2(0x0010) | 3 | 1 |
| 内核代码段 | 0x0000 | 0000 | 1 | 0xF | FFFF | 1 | 10(0x1010) | 0 | 1 |
| 内核数据段 | 0x0000 | 0000 | 1 | 0xF | FFFF | 1 | 2(0x0010) | 0 | 1 |
上述设置分别与Linux内核中的宏__USER_CS,__USER_DS,__KERNEL_CS,__KERNEL_DS相对应。
- 长模式(IA-32e模式):在长模式下,处理器完全执行64位指令,使用64位地址空间(物理内存的寻址能力却没有被完全扩展到64位,因为目前的众多CPU在其寿命期限之内都没有机会见识到如此巨大的内存)和64操作数。因此,为了降低制造成本,目前的CPU被限制在略少于64位寻址。
2. Linux的内核空间
参考链接:
- Linux的内核空间(低端内存、高端内存)
- linux 用户空间与内核空间——高端内存详解
- Linux x86_64线性地址空间布局
-
Linux内核在x86_64 CPU中地址映射
ps: 参考链接最好都看一下
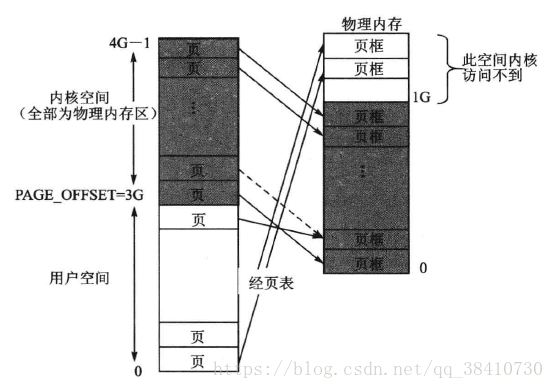
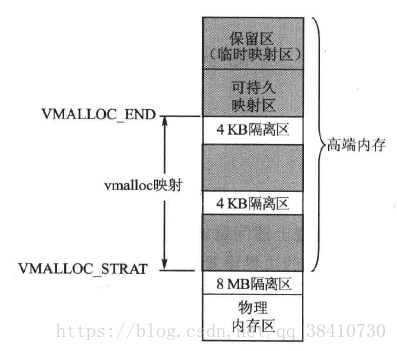
32 位Linux的内核空间,为了兼容性,牺牲了很对,对于逻辑的地址空间,32位对应的4GB,因此在当初的操作系统内核设计时,为了将一部分的逻辑地址空间留给用户空间,因此内核只给自己留了1GB的内核逻辑地址空间。
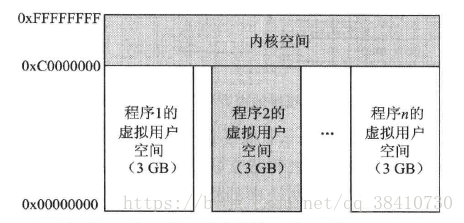
但是这1GB的逻辑内核,当物理内存大于1GB时,便会存在问题。因此除了一部分的直接映射方式之外。Linux内核中,提供了高端内存区(ZONE_HIGHMEM)来随意映射所有可用的物理内存(ps:直接映射只是,建立起了映射管理关系,并没有对物理内存进行读写)
添加高端映射之后:
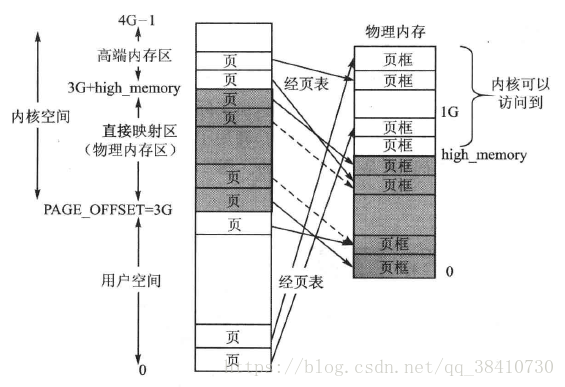
高端映射可以由vmalloc进行分配和管理
64位操作系统采用了4层地址映射(x86 64位内存管理)

其逻辑地址空间分布如下:
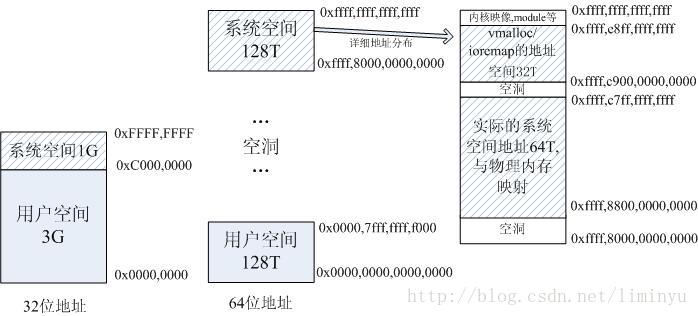
注意:64为操作系统更改了ZONE_HIGHMEM的错误,因此在其中没有ZONE_HIGHMEM。目前的x86_64架构CPU都遵循AMD的Canonical Form,即只有虚拟地址的最低48位才会在地址转换时被使用, 且任何虚拟地址的48位至63位必须与47位一致, 也就是说总的虚拟地址空间为256TB。
那么在64位架构下,如何分配虚拟地址空间的呢? 0000000000000000 – 00007fffffffffff(128TB)为用户空间, ffff800000000000 – ffffffffffffffff(128TB)为内核空间。
而且内核空间中有很多空洞, 越过第一个空洞后, ffff880000000000 – ffffc7ffffffffff(64TB)才是直接映射物理内存的区域, 也就是说默认的PAGE_OFFSET为ffff880000000000.
既然现在内核直接映射的物理内存区域有64TB, 而且一般情况下,极少有计算机的内存能达到64TB(别说64TB了,1TB内存的也很少很少),所以整个内核虚拟地址空间都能够一一映射到计算机的物理内存上,因此,不再需要 ZONE_HIGHMEM这个分区了,现在对物理内存的划分,只有ZONE_DMA, ZONE_NORMAL
64位的实际逻辑内存空间布局如下(最左边为当前使用的48为逻辑地址空间):

详细内存布局如下:
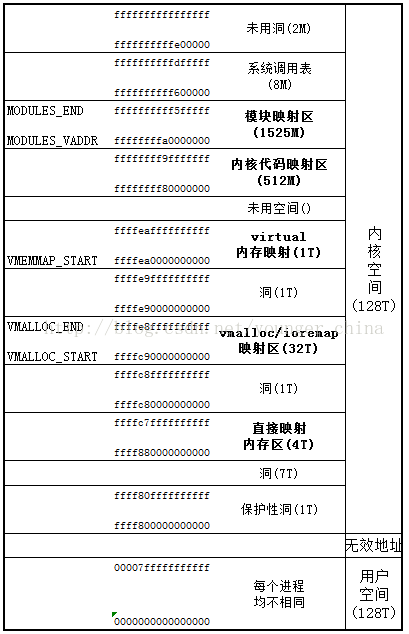
具体信息可以在Linux的/proc/meminfo中看到。
3. linux NUMA技术
参考技术:
- linux NUMA技术
- Linux内核学习笔记:SMP、UMA、NUMA
- 服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA)
- 服务器三大体系 SMP、NUMA、MPP 之详解
NUMA(Non-Uniform Memory Access Architecture)即非一致性内存访问技术。NUMA系统有多个Node通过高速互连的网络联系起来的系统。而Node则是由一组cpu和本地内存组成。不同的Node有不同的物理内存,由于Node访问本地内存和访问其它节点的内存的速度是不一致的,为了解决非一致性访问内存对性能的影响,有一些工具可以使用。包括 numactl,autonuma, HPE-AIX等。
第 13 章 虚拟文件系统
参考链接:
ps:第一篇文章总结的非常好,不做过多叙述
FS对于具体文件系统来说,相当于一个管理者,提供统一的文件系统接口。对于内核其他子系统以及在操作系统之上的用户程序而言,所有的文件系统都是一样的。实际上,要支持新的文件系统,主要需要完成的工作就是编写这些接口函数。虚拟文件系统主要有以下几个作用:
- (1)对具体文件系统的数据结构进行抽象,以统一的数据结构进行管理;
- (2)接收用户层的调用,例如write、read、open等;
- (3)支持多种具体文件系统之间的相互访问;
- (4)接收内核其他子系统的操作请求,特别是内存管理子系统.
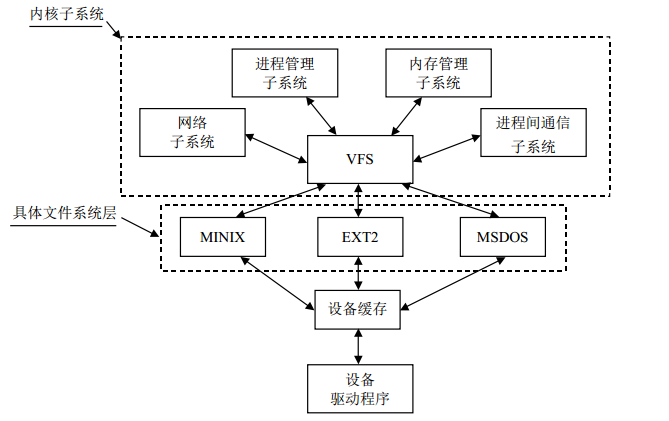
图1 Linux中文件系统的逻辑关系示意图。
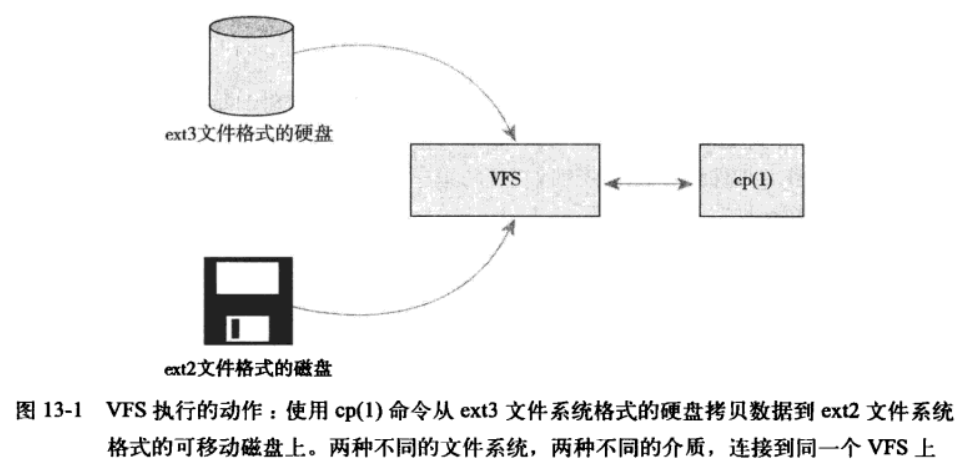
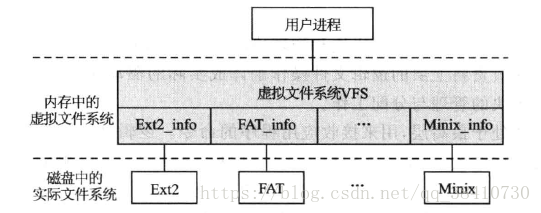
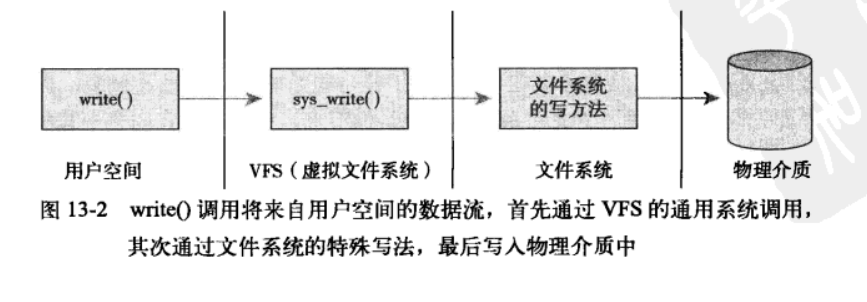
13.4 VFS 对象及其数据结构
从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。为了描述 这个结构, VFS采用面向对象的设计思路。将其分为不同的对象,并提供了对象的操作方式:
- 文件 一组在逻辑上具有完整意义的信息项的系列。在Linux中,除了普通文件,其他诸如目录、设备、套接字等 也以文件被对待。总之,“一切皆文件”。
- 目录 目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成 文件路径。在Linux中,目录也是以一种特殊文件被对待的,所以用于文件的操作同样也可以用在目录上。
- 目录项 在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项。
- 索引节点 用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同 的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。
- 超级块 用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节 点数等,存放于磁盘的特定扇区中。
概念在磁盘中的位置关系图如下:

13.5 超级块对象
描述整个文件系统的信息。其只存在于内存中。定义在include/fs/fs.h中。主要域含义如下:
struct super_block
{
struct list_head s_list; /*指向超级块链表的指针*/
/************描述具体文件系统的整体信息的域*****************/
kdev_t s_dev; /* 包含该具体文件系统的块设备标识符。例如,对于 /dev/hda1,其设备标识符为 0x301*/
unsigned long s_blocksize; /*该具体文件系统中数据块的大小,以字节为单位 */
unsigned char s_blocksize_bits; /*块大小的值占用的位数,例如,如果块大小为 1024 字节,则该值为 10*/
unsigned long long s_maxbytes; /* 文件的最大长度 */
unsigned long s_flags; /* 安装标志*/
unsigned long s_magic; /*魔数,即该具体文件系统区别于其他文件系统的一个标志*/
/**************用于管理超级块的域******************/
struct list_head s_list; /*指向超级块链表的指针*/
struct semaphore s_lock /*锁标志位,若置该位,则其他进程不能对该超级块操作*/
struct rw_semaphore s_umount /*对超级块读写时进行同步*/
unsigned char s_dirt; /*脏位,若置该位,表明该超级块已被修改*/
struct dentry *s_root; /*指向该具体文件系统安装目录的目录项*/
int s_count; /*对超级块的使用计数*/
atomic_t s_active;
struct list_head s_dirty; /*已修改的索引节点形成的链表 */
struct list_head s_locked_inodes;/* 要进行同步的索引节点形成的链表*/
struct list_head s_files
/***********和具体文件系统相联系的域*************************/
struct file_system_type *s_type; /*指向文件系统的
file_system_type 数据结构的指针 */
struct super_operations *s_op; /*指向某个特定的具体文件系统的用于超级块操作的函数集合 */
struct dquot_operations *dq_op; /* 指向某个特定的具体文件系统用于限额操作的函数集合 */
u; /*一个共用体,其成员是各种文件系统的 fsname_sb_info 数据结构 */
};
其对应的超级块操作如下:
struct super_operations {
/* 给定的超级块下创建和初始化一个新的索引节点对象 */
struct inode *(*alloc_inode)(struct super_block *sb);
/* 释放给定的索引节点 */
void (*destroy_inode)(struct inode *);
/* 当索引节点被修改时,执行函数更新日志文件系统 */
void (*dirty_inode) (struct inode *);
/* 将给定的索引几点写入磁盘, wait表示是否需要同步操作*/
int (*write_inode) (struct inode *, int wait);
/* 最后一个索引节点的引用被释放后,VFS会调用该函数。进行删除节点 */
void (*drop_inode) (struct inode *);
/* 删除指定节点 */
void (*delete_inode) (struct inode *);
/* 卸载文件系统时,由VFS调用,用来释放超级块。调用者必须一直持有s_lock锁 */
void (*put_super) (struct super_block *);
/* 用给定的超级块更新磁盘上的超级快,VFS通过该函数对内存中的超级快和磁盘中的超级快进行同步,调用者必须一直持有s_lock锁 */
void (*write_super) (struct super_block *);
/* 文件系统的数据元与磁盘上的文件系统同步。wait指定是否同步 */
int (*sync_fs)(struct super_block *sb, int wait);
/* */
int (*freeze_fs) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
/* 获取文件系统状态,指定文件系统相关的统计信息放在statfs中 */
int (*statfs) (struct dentry *, struct kstatfs *);
/* 指定新的安装选项重新安装文件系统时调用,调用者必须一直持有s_lock锁 */
int (*remount_fs) (struct super_block *, int *, char *);
/* 释放索引节点,并清空包含相关数据的所有页面 */
void (*clear_inode) (struct inode *);
/* 中断安装操作,该函数被网络文件系统使用,如NFS */
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
int (*show_stats)(struct seq_file *, struct vfsmount *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
};
调用方式:sb->s_op->write_super(sb);sb是指向文件系统超级块的指针,从该指针进入超级块对应的函数表,并从中获得write_super()函数。相当于C++中的this指针。
13.7 索引节点对象
文件系统处理文件所需要的所有信息都放在称为索引节点的数据结构中,索引节点对于文件是唯一的。具体文件系统的索引节点是存储在磁盘上的,是一种静态结构,要使用它,必须调入内存,填写VFS的索引节点,因此,也称VFS索引节点为动态节点。VFS索引节点的数据结构inode在/include/fs/fs.h/中定义如下:
struct inode
{
/**********描述索引节点高速缓存管理的域****************/
struct list_head i_hash; /*指向哈希链表的指针*/
struct list_head i_list; /*指向索引节点链表的指针*/
struct list_head i_dentry;/*指向目录项链表的指针*/
struct list_head i_dirty_buffers;
struct list_head i_dirty_data_buffers;
/**********描述文件信息的域****************/
unsigned long i_ino; /*索引节点号*/
kdev_t i_dev; /*设备标识号 */
umode_t i_mode; /*文件的类型与访问权限 */
nlink_t i_nlink; /*与该节点建立链接的文件数 */
uid_t i_uid; /*文件拥有者标识号*/
gid_t i_gid; /*文件拥有者所在组的标识号*/
kdev_t i_rdev; /*实际设备标识号*/
off_t i_size; /*文件的大小(以字节为单位)*/
unsigned long i_blksize; /*块大小*/
unsigned long i_blocks; /*该文件所占块数*/
time_t i_atime; /*文件的最后访问时间*/
time_t i_mtime; /*文件的最后修改时间*/
time_t i_ctime; /*节点的修改时间*/
unsigned long i_version; /*版本号*/
struct semaphore i_zombie; /*僵死索引节点的信号量*/
/***********用于索引节点操作的域*****************/
struct inode_operations *i_op; /*索引节点的操作*/
struct super_block *i_sb; /*指向该文件系统超级块的指针 */
atomic_t i_count; /*当前使用该节点的进程数。计数为 0,表明该节点可丢弃或被重新使用 */
struct file_operations *i_fop; /*指向文件操作的指针 */
unsigned char i_lock; /*该节点是否被锁定,用于同步操作中*/
struct semaphore i_sem; /*指向用于同步操作的信号量结构*/
wait_queue_head_t *i_wait; /*指向索引节点等待队列的指针*/
unsigned char i_dirt; /*表明该节点是否被修改过,若已被修改,则应当将该节点写回磁盘*/
struct file_lock *i_flock; /*指向文件加锁链表的指针*/
struct dquot *i_dquot[MAXQUOTAS]; /*索引节点的磁盘限额*/
/************用于分页机制的域**********************************/
struct address_space *i_mapping; /* 把所有可交换的页面管理起来*/
struct address_space i_data;
/**********以下几个域应当是联合体****************************************/
struct list_head i_devices; /*设备文件形成的链表*/
struct pipe_inode_info i_pipe; /*指向管道文件*/
struct block_device *i_bdev; /*指向块设备文件的指针*/
struct char_device *i_cdev; /*指向字符设备文件的指针*/
/*************************其他域***************************************/
unsigned long i_dnotify_mask; /* Directory notify events */
struct dnotify_struct *i_dnotify; /* for directory notifications */
unsigned long i_state; /*索引节点的状态标志*/
unsigned int i_flags; /*文件系统的安装标志*/
unsigned char i_sock; /*如果是套接字文件则为真*/
atomic_t i_writecount; /*写进程的引用计数*/
unsigned int i_attr_flags; /*文件创建标志*/
__u32 i_generation /*为以后的开发保留*/
/*************************各个具体文件系统的索引节点********************/
union; /*类似于超级块的一个共用体,其成员是各种具体文件系统的 fsname_inode_info 数据结构 */
}
与VFS的超级块一样,VFS的i节点也是既包含虚拟文件系统的通用管理系统,又包含具体文件系统i节点的私有信息。其中,结构的指针generic_ip就指向了具体文件系统i节点的私有信息,该信息也被保存在内存的一个结构中。
例如:当虚拟文件系统与Ext2文件系统对接时,指针generic_ip就指向Ext2文件系统的i节点信息结构ext2_inode_info。即系统在安装Ext2系统时,会在内存中创建一个ext2_inode_info结构实例,并将磁盘文件系统Ext2的i节点的部分私有信息提取到该结构。
结构struct ext2_inode_info的代码如下:
struct ext2_inode_info {
__le32 i_data[15]; //数据库块指针数组
__u32 i_flags; //文件打开方式
__u32 i_faddr;
__u8 i_frag_no; //第一个碎片号
__u8 i_frag_size; //碎片大小
__u16 i_state;
__u32 i_file_acl; //文件访问控制链表
__u32 i_dir_acl;
__u32 i_dtime; //文件删除时间
__u32 i_block_group; //文件所在块组号
struct ext2_block_alloc_info *i_block_alloc_info;
__u32 i_dir_start_lookup;
#ifdef CONFIG_EXT2_FS_XATTR
struct rw_semaphore xattr_sem;
#endif
#ifdef CONFIG_EXT2_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
rwlock_t i_meta_lock;
struct mutex truncate_mutex;
struct inode vfs_inode;
struct list_head i_orphan; /* unlinked but open inodes */
};
当虚拟文件与Ext2文件系统相关联时,VFS的索引节点如下图所示:
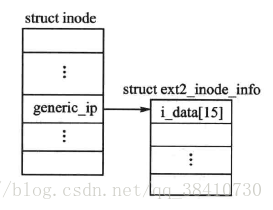
每个文件都有一个inode,每个inode有一个索引节点号i_ino;inode中有两个设备号,i_dev和i_rdev。除特殊文件外,每个节点都存储在某个设备上,这就是 i_dev。如果索引节点所代表的并不是常规文件,而是某个设备,那就还得有个设备号,这就是 i_rdev;每个索引节点都会复制磁盘索引节点包含的一些数据,比如文件占用的磁盘块数。属于”正在使 用”或”脏”链表的索引节点对象也同时存放在一个称为inode_hashtable链表中。
其操作调用方式如下:i->i_op->truncate(i)
struct inode_operations {
/* 创建一个新的索引节点 */
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
/* 在特定目录中寻找索引节点,该索引节点要对应于denrty中给出的文件名 */
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
/* 创建一个硬链接,dentry参数指定硬链接名,链接对象是dir中的old_dir */
int (*link) (struct dentry *,struct inode *,struct dentry *);
/* 删除一个硬链接 */
int (*unlink) (struct inode *dir,struct dentry *dentry);
/* 创建一个软链接 */
int (*symlink) (struct inode *dir,struct dentry *dentry,const char *sysname);
/* 创建一个文件夹,最后为一个模式*/
int (*mkdir) (struct inode *,struct dentry *,int mode);
int (*rmdir) (struct inode *,struct dentry *);
/* 创建特殊文件,文件在dir目录中,其目录项为dentry,关联的设备为rdev,mode设置权限 */
int (*mknod) (struct inode *dir,struct dentry *dentry,int mode,dev_t rdev);
/* 重命名 */
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
/* 拷贝数据到特定的缓冲buffer中。 */
int (*readlink) (struct dentry *, char *,int buflen);
/* 查找执行的索引节点存储在nameidata中 */
void * (*follow_link) (struct dentry *, struct nameidata *);
/* 清除查找后的结果 */
void (*put_link) (struct dentry *, struct nameidata *, void *);
/* 修改文件的大小 */
void (*truncate) (struct inode *);
/* 检查文件是否允许特定的访问模式 */
int (*permission) (struct inode *, int);
/* 通知发生了改变事件,一般被notify_change()调用 */
int (*setattr) (struct dentry *, struct iattr *);
/* 在通知索引节点需要从磁盘中更新时,VFS会调用该函数,扩展属性允许key/value这样的一对值与文件关联 */
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
/* 给dentry指定的文件设置扩展属性。属性名为name,值为value */
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
/* 向value中拷贝给定文件的扩展属性name对应的数值 */
ssize_t (*getxattr) (struct dentry *, const char *, void * value, size_t);
/* 将指定文件的所有属性拷贝到一个缓冲列表 */
ssize_t (*listxattr) (struct dentry *, char *, size_t);
/* 删除指定属性 */
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
long (*fallocate)(struct inode *inode, int mode, loff_t offset,
loff_t len);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start,
u64 len);
};
13.9 目录对象
VFS的dentry结构 结构dentry是实际文件系统的目录项在虚拟文件系统VFS中的对应物,实质上就是前面所讲的目录缓冲区。当系统访问一个具体文件时,会根据这个文件在磁盘上的目录在内存中创建一个dentry结构,它除了要存放文件目录信息之外,还要存放有关文件路径的一些动态信息。
例如:它建立了文件名与节点inode之间的联系,保存了目录项与其父、子目录之间的关系。之所以建立这样的一个文件目录的对应物,是为了同一个目录被再次访问时,其相关信息就可以直接由dentry获得,而不必再次重复访问磁盘。
结构dentry在文件include/linux/dcache.h中定义如下:
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* 记录目录项被引用次数的计数器 */
spinlock_t d_lock; /* 目录项的标志 */
int d_mounted;
struct inode *d_inode; /* 与文件名相对应的inode */
struct hlist_node d_hash; /* 目录项形成的散列表 */
struct dentry *d_parent; /* 指向父目录项的指针 */
struct qstr d_name; //包含文件名的结构
struct list_head d_lru; /* 已经没有用户使用的目录项的链表 */
union {
struct list_head d_child; /* 父目录的子目录项形成的链表 */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* i节点别名的链表 */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
const struct dentry_operations *d_op; //指向dentry操作函数集的指针
struct super_block *d_sb; /* 目录树的超级块,即本目录项所在目录树的根 */
void *d_fsdata; /* 文件系统的特定数据 */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* 短文件名 */
};
结构中的域d_name是qstr类型的结构。该结构的定义如下:
struct qstr {
unsigned int hash; //文件名
unsigned int len; //文件名长度
const unsigned char *name; //散列值
};
内核通过维护一个散列表dentry_hashtable来管理dentry。系统一旦在内存中建立一个dentry,该dentry结构就会被链入散列表的某个队列中。
结构中的域d_count记录了本dentry被访问的次数。当某个dentry的d_count的值为0时,就意味着这个dentry结构已经没有用户使用了,这时这个dentry会被d_lru链入一个由系统维护的另一个队列dentry_unused中。由于内核从不删除曾经建立的dentry,于是,同一个目录被再次访问时,其相关信息就可以直接由dentry获得,而不必重复访问存储文件系统的外存。
另外,当本目录项有父目录节点时,其dentry结构通过域d_child挂入父目录项的子目录d_subdirs队列中,同时使指针d_parent指向父目录的dentry结构。若本目录有子目录,则将它们挂接在域d_subdirs指向的队列中。
dentry操作如下:
struct dentry_operations {
/* 判断目录项是否有效 */
int (*d_revalidate)(struct dentry *, struct nameidata *);
/* 生成一个散列值 */
int (*d_hash) (struct dentry *, struct qstr *);
/* 比较两个文件名 */
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
/* 删除count为0的dentry */
int (*d_delete)(struct dentry *);
/* 释放一个dentry对象 */
void (*d_release)(struct dentry *);
/* 丢弃目录项对应的inode */
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
};
目录对象有三种有效状态:
- 被使用:对应一个有效的索引节点,并且d_count为正值。基本不会被丢弃
- 未被使用:对应有效的索引节点,但是d_count为0;可以丢弃
- 负状态:没有对应的有效索引节点,因为索引节点已经被删除了。但是目录项仍然保留,以便快速解析以后的路径查询。
13.9.2 页目录缓存
为了避免每次操作都要遍历整个目录树,内核将目录对象缓存在目录项缓存(dcache)中。其中包含主要三个部分如下:
- “被使用的”目录项链表:通过索引节点的i_dentry项链接相关的索引节点。连一个索引节点可能有多个链接,可能有多个目录项对象。
- “最近被使用的”双向链表:包含未被使用的和负状态的目录项对象。插入较多。链头节点的数目比链尾节点的数据要新。
- 散列表和相应的散列函数用来快速的将给定路径解析为相关目录项对象。
13.11 文件对象
每个文件都有一个32位的数字来表示下一个读写的字节位置,Linux中专门使用数据结构file来保存打开文件的文件位置,此外,file结构还把指向该文件索引节点的指针也放在其中。file结构形成一个双链表,称为系统打开文件表,其最大长度为NR_FILE,在fs.h中定义为8192。file结构在include/inux/fs.h中定义如下:
struct file
{
struct list_head f_list; /*所有打开的文件形成一个链表*/
struct dentry *f_dentry; /*指向相关目录项的指针*/
struct vfsmount *f_vfsmnt; /*指向 VFS 安装点的指针*/
struct file_operations *f_op; /*指向文件操作表的指针*/
mode_t f_mode; /*文件的打开模式*/
loff_t f_pos; /*文件的当前位置*/
unsigned short f_flags; /*打开文件时所指定的标志*/
unsigned short f_count; /*使用该结构的进程数*/
unsigned long f_reada, f_ramax, f_raend, f_ralen, f_rawin;/*预读标志、要预读的最多页面数、上次预读后的文件指针、预读的字节数以及预读的页面数*/
int f_owner; /* 通过信号进行异步 I/O 数据的传送*/
unsigned int f_uid, f_gid; /*用户的 UID 和 GID*/
int f_error; /*网络写操作的错误码*/
unsigned long f_version; /*版本号*/
void *private_data; /* tty 驱动程序所需 */
};
13.12 文件操作
struct file_operations {
struct module *owner;
/* 更新偏移纸指针,由系统调用lleek*(调用它) */
loff_t (*llseek) (struct file *, loff_t, int);
/* 从给定文件的offset偏移处读取conut字节的数据到buf中,同时更新文件指针,一般由read进行调用 */
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
/* 从给定的buf中取出conut字节的数据,写入给定文件的offset偏移处,同时更新文件指针 */
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
/* 返回目录列表中的下一个目录,由系统调用readdir()调用它 */
int (*readdir) (struct file *, void *, filldir_t);
/* 函数睡眠等待给定文件活动,由系统调用poll()调用它 */
unsigned int (*poll) (struct file *, struct poll_table_struct *);
/* 用来 */
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
/* 将给定的文件映射到指定的地址空间上。由系统调用mmap()调用它 */
int (*mmap) (struct file *, struct vm_area_struct *);
/* 创建一个新的文件对象,并将其和对应的索引节点对象关联起来 */
int (*open) (struct inode *, struct file *);
/* 更新一个文件相关信息 */
int (*flush) (struct file *);
/* 当文件最后一个引用被注销时,该函数会被VFS调用,具体功能由文件系统决定 */
int (*release) (struct inode *, struct file *);
/* 将给定的所有缓存数据写回磁盘,由系统调用fsync()调用它 */
int (*fsync) (struct file *, struct dentry *, int datasync);
/* 打开或关闭异步I/O的通告信号 */
int (*fasync) (int, struct file *, int);
/* 给指定文件上锁 */
int (*lock) (struct file *, int, struct file_lock *);
/* 从给定文件中读取数据,并将其写入由vector描述的count个缓冲中去,同时增加文件的偏移量。由系统调用readv()调用它 */
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
/* 由给定vector描述的count个缓冲中的数据写入到由file指定的文件中去,同时减小文件的偏移量。由系统调用writev()调用它 */
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
/* 从一个文件向另外一个文件发送数据 */
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long,
unsigned long, unsigned long);
};
13.12.2 主要结构之间的关系
超级块是对一个文件系统的描述;索引节点是对一个文件物理属性的描述;目录项是对一个文件逻辑属性的描述。一个进程所处的位置是由fs_struct来描述的,一个进程(或用户)打开的文件是由file_struct来描述的,而整个系统所打开的文件是由file结构描述的。图2表示不同数据结构之间的关系:
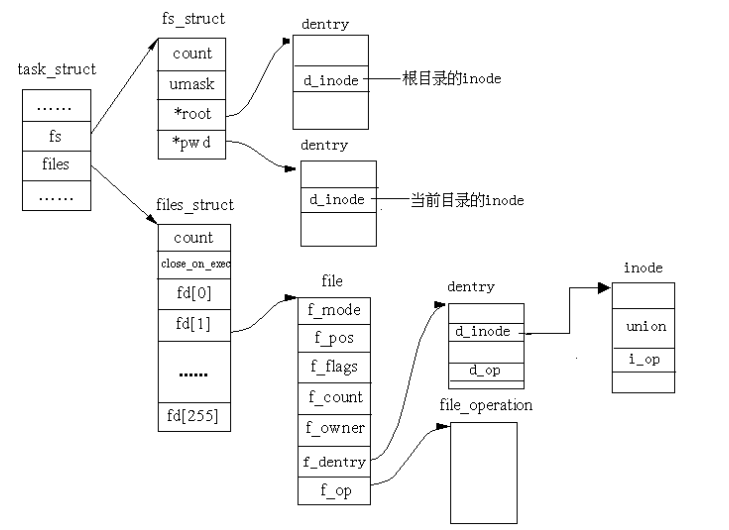
13.13 和文件系统相关的数据结构
根据文件系统所在的物理介质和数据在物理介质上的组织方式来区分不同的文件系统类型的。 file_system_type结构用于描述具体的文件系统的类型信息。被Linux支持的文件系统,都有且仅有一 个file_system_type结构而不管它有零个或多个实例被安装到系统中。
而与此对应的是每当一个文件系统被实际安装,就有一个vfsmount结构体被创建,这个结构体对应一个安装点。
//<linux/fs.h>
struct file_system_type {
const char *name; /*文件系统的名字*/
struct subsystem subsys; /*sysfs子系统对象*/
int fs_flags; /*文件系统类型标志*/
/*在文件系统被安装时,从磁盘中读取超级块,在内存中组装超级块对象*/
struct super_block *(*get_sb) (struct file_system_type*,
int, const char*, void *);
void (*kill_sb) (struct super_block *); /*终止访问超级块*/
struct module *owner; /*文件系统模块*/
struct file_system_type * next; /*链表中的下一个文件系统类型*/
struct list_head fs_supers; /*具有同一种文件系统类型的超级块对象链表*/
};
//<linux/mount.h>
struct vfsmount
{
struct list_head mnt_hash; /*散列表*/
struct vfsmount *mnt_parent; /*父文件系统*/
struct dentry *mnt_mountpoint; /*安装点的目录项对象*/
struct dentry *mnt_root; /*该文件系统的根目录项对象*/
struct super_block *mnt_sb; /*该文件系统的超级块*/
struct list_head mnt_mounts; /*子文件系统链表*/
struct list_head mnt_child; /*子文件系统链表*/
atomic_t mnt_count; /*使用计数*/
int mnt_flags; /*安装标志*/
char *mnt_devname; /*设备文件名*/
struct list_head mnt_list; /*描述符链表*/
struct list_head mnt_fslink; /*具体文件系统的到期列表*/
struct namespace *mnt_namespace; /*相关的名字空间*/
};
vfsmount结构体中维护的各种链表,就是为了能够跟踪这些关联信息。mnt_flags中存储了一定的安装标志如下:

13.14 和进程相关的数据结构
系统中每个进程都有自己的一组打开的文件。如:根文件系统、当前工作目录、安装点等。其中file_struct、fs_struct、namespace将VFS层和系统的进程紧密结合在一起
file_struct 由进程描述符中的files目录项指向。所有单个进程相关的信息(打开文件及文件描述符)都包含在其中,其结构如下:
struct files_struct {//打开的文件集
atomic_t count; /*结构的使用计数*/
struct fdtable *fdt; /* 指向其它fd表的指针*/
struct fdtable fdtab; /* 基fd表 */
spinlock_t file_lock; /* 单个文件的锁*/
int next_fd; /* 缓存下一个可用的fd */
struct embedded_fd_set close_on_exec_init; /* exec()时关闭的文件描述符链接 */
struct embedded_fd_set open_fds_init; /* 打开的文件描述符链表 */
struct file *fd_aray[NR_OPEN_DEFAULT]; /* 缺省的文件数组对象 */
……
};
fs_struct结构体由进程描述符符fs域致电该。它包含文件系统和进程相关的信息,定义在文件<linux/fs_struct.h>中,下面是它的具体结构和各项描述
struct fs_struct {//建立进程与文件系统的关系
int users; /* 用户数目 */
rwlock_t lock; /* 保护该结构体的锁 */
int umask; /* 掩码 */
int int_exec; /* 当前正在执行的文件 */
struct path root; /* 根目录路径 */
struct path pwd; /*当前工作目录的路径 */
};
namespace结构体,定义在文件<linux/mmt_namespace.h>中,由进程描述符中的mmt_namespace域指向。它使得每一个进程在系统中都看到唯一的安装文件系统–不仅是唯一的根目录,而且是唯一的文件系统层次结构。
struct mmt_namespace{
atomic_t count; /* 结构的使用计数 */
struct vfsmount *root; /* 根目录的安装点对象 */
struct list_head list; /* 安装点链表 */
wait_queue_head_t poll; /* 轮询的等待队列 */
int event; /* 事件计数 */
}
默认情况下,所有的进程共享通信杨的命名空间。只有在进行clone()操作时使用CLONE_NEWS标志,才会给进程一个唯一的命名空间结构体的拷贝。大多数情况下,都是直接集成父进程的命名空间。
13.15 总结
VFS即虚拟文件系统是Linux文件系统中的一个抽象软件层;因为它的支持,众多不同的实际文件系统才能在Linux中共存,跨文件系统操作才能实现。 VFS借助它四个主要的数据结构即超级块、索引节点、目录项和文件对象以及一些辅助的数据结构,向Linux中不管是普通的文件还是目录、设备、套接字等 都提供同样的操作界面,如打开、读写、关闭等。只有当把控制权传给实际的文件系统时,实际的文件系统才会做出区分,对不同的文件类型执行不同的操作。由此 可见,正是有了VFS的存在,跨文件系统操作才能执行,Unix/Linux中的“一切皆是文件”的口号才能够得以实现。
超级块、安装点和具体的文件系统关系:

13.16 补充知识
13.16.1 文件缓冲区
为了方便文件的读写操作,Linux中在内核内存中设置了一块缓冲区,用来进行相关数据的读写缓冲,提高系统运行效率:
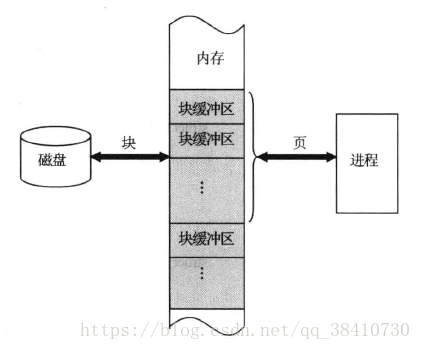
因此,内核中设置了两套用来管理缓冲区的数据结构。
13.16.2 磁盘数据块缓冲区
在Linux中,每一个磁盘数据块缓冲区用buffer_head结构来描述。buffer_head结构如下:
struct buffer_head {
unsigned long b_state; /* 缓冲区状态位图 */
struct buffer_head *b_this_page;/* 指向同一页面的缓冲块,形成环形链表 */
struct page *b_page; /* 指向页缓冲指针 */
sector_t b_blocknr; /* 逻辑块号 */
size_t b_size; /* 块大小 */
char *b_data; /* 指向数据块缓冲区的指针 */
struct block_device *b_bdev; /*指向块设备结构的指针*/
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
atomic_t b_count; /* 块引用计数 */
};
其中,域b_data是指向内存中磁盘块缓冲区的指针;域b_size表示缓冲区的大小。由于进程以页面为单位来访问缓冲区,所以结构中用域b_this_page把同一页面缓冲块组成了一个环形链表。
缓冲区的大小不是固定的,当前Linux支持5种大小的缓冲区,分别是512、1024、2048、4096和8192字节。Linux所支持的文件系统都是用共同的块高速缓冲,在同一时刻,块高速缓冲中存在着来自不同物理设备的数据块,为了支持这些不同大小的数据块,Linux使用几种不同大小的缓冲区。
另外,系统根据磁盘数据块缓冲区的使用状态将它们分别组成了多个队列。
内存中的一个磁盘块缓冲区的队列示意图如下所示:
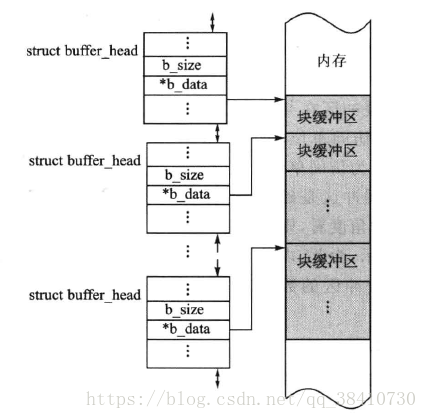
磁盘数据块缓冲区是一种全局资源,可以被所有的文件系统共享使用。
13.16.3 页缓冲区
为了方便进程对文件的使用,并在需要时能把以块为单位的磁盘块缓冲区(块的大小一般为512字节)映射到以页为单位(页的大小一般4k)的用户空间,VFS还建立了页缓冲区。由于进程是通过VFS的i节点来访问文件的,因此,文件的页缓冲区也就被设置在inode结构中。
inode结构中有一个指向自身的i_data域的指针i_mapping,这个i_data域是一个address_space的结构。而每一个页面的所有信息由struct page来描述,它有一个名称为mapping的域,这是一个指针,它指向一个struct address_space类型结构。
缓冲区的数据结构struct address_space的主要内容如下:
struct address_space {
struct inode *host; /* 属主的索引节点 */
struct radix_tree_root page_tree; /* 全部页面的radix数 */
spinlock_t tree_lock; /* and lock protecting it */
unsigned int i_mmap_writable; /* count VM_SHARED mappings */
struct prio_tree_root i_mmap; /* tree of private and shared mappings */
struct list_head i_mmap_nonlinear; /*list VM_NONLINEAR mappings */
spinlock_t i_mmap_lock; /* protect tree, count, list */
unsigned int truncate_count; /* Cover race condition with truncate */
unsigned long nrpages; /* 占用的物理边框总数 */
pgoff_t writeback_index; /* writeback starts here */
const struct address_space_operations *a_ops; /* 页缓冲区操作函数集指针 */
unsigned long flags; /* error bits/gfp mask */
struct backing_dev_info *backing_dev_info; /* 预读信息 */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* 页缓冲区链表 */
struct address_space *assoc_mapping; /* 相关缓存 */
} __attribute__((aligned(sizeof(long))));
页缓冲区与磁盘缓冲区之间的关系如下图所示:
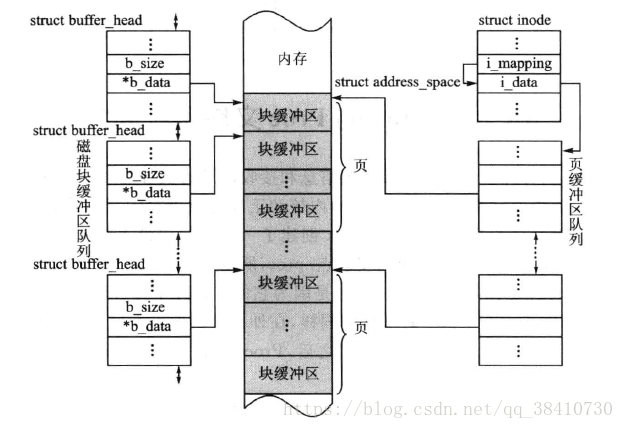
依照Linux的一贯风格,Linux将缓冲区操作函数封装在如下的address_space_operations结构中:
通常,i_fop(inode的指向文件操作函数集的指针)并不直接与块设备联系,而是间接通过a_ops(address_space的页缓冲区操作函数集)读写文件。文件的页缓冲就是i_fop与a_ops之间的缓冲,它是块设备缓冲之上的更高一级缓冲,直接用于具体文件的读写。
Linux中通过Proc文件系统,将所有设备抽象为只存在于内存上的文件,有如下优势:
- 可以利用Proc文件系统的文件,开发一些专门用于获取内核数据的应用程序;
- 完成用户空间和内核空间的通信,能得到内核运行时的数据,安全且方便;
- 利用Proc文件可使进程直接对内核的参数进行配置的特点,可以在不重新编译内核的情况下优化系统配置。
参考链接: 深入理解linux系统下proc文件系统内容
第 14 章 块I/O层
系统中能够随机访(不需要按照顺序)访问固定大小的数据片(chunks)的硬件设备称为块设备。固定大小的数据块就称为块。
字符设备:按照有序字符流的方式有序访问的设备。如串口和键盘。
一般而言你,块设备管理比字符设备难得多。
14.1 剖析一个块设备
块设备中最小的可寻址单元是扇区,一般扇区的大小为2的整数倍,常见的是512字节。也有小的如CD-ROM扇区是2KB大小
块设备的最小逻辑单元是块–文件系统的抽象,只能基于块来访问文件系统。块一般是2的整数倍,不能超过一个页的长度。所以块 必须是扇区的整数倍,并且要小于页面大小。因此其通常大小是512字节、1KB或者4KB
所有设备的I/O必须以扇区为单位进行操作。
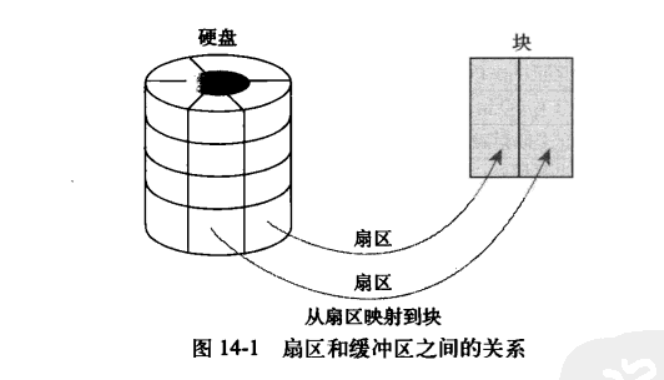
14.3 缓冲区和缓冲区头
详细见13.16.2 磁盘数据块缓冲区
其中bh_state_bits枚举如下:

缓冲区头的目的在于描述磁盘块和物理内存缓冲区(在特定页面商都字节序列)之间的映射关系。
因为缓冲区比较大,操作不方便,使用效率底下。仅仅能描述单个缓冲区,当作为所有I/O容器使用时,缓冲区头会促使内核把对大块数据的I/O操作(比如写操作)分解为对多个buffer_head结构体进行操作。造成不必要的空间浪费。为了避免这种情况,用了bio结构体,灵活且轻量级;
当前的内核在向块设备层提交读写请求时,都会将buffer_head封装在bio结构中,而不再使用原来的buffer_head,例如下面这段代码是ext2文件系统向磁盘写数据的实现:
14.3 bio结构体
目前内核中块I/O操作基本容器由bio结构体表示,它定义在文件<linux/bio.h>中。该结构体代表了正在现场的(活动的)以片段(segment)链表形式组织的块I/O操作。一个片段是一小块连续的内存缓冲区。使得进程可以通过片段来描述缓冲区;即使缓冲区分散在内存的多个位置上,bio结构体也能对内核保证I/O操作的执行。其关键结构描述如下:
//include/linux/blk_types.h
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link */
struct gendisk *bi_disk;
unsigned int bi_opf; /* bottom bits req flags,
* top bits REQ_OP. Use
* accessors.
*/
unsigned short bi_flags; /* status, etc and bvec pool number */
unsigned short bi_ioprio;
unsigned short bi_write_hint;
blk_status_t bi_status;
u8 bi_partno;
struct bvec_iter bi_iter;
atomic_t __bi_remaining;
bio_end_io_t *bi_end_io;
void *bi_private;
#ifdef CONFIG_BLK_CGROUP
/*
* Represents the association of the css and request_queue for the bio.
* If a bio goes direct to device, it will not have a blkg as it will
* not have a request_queue associated with it. The reference is put
* on release of the bio.
*/
struct blkcg_gq *bi_blkg;
struct bio_issue bi_issue;
#ifdef CONFIG_BLK_CGROUP_IOCOST
u64 bi_iocost_cost;
#endif
#endif
union {
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
};
unsigned short bi_vcnt; /* how many bio_vec's */
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
struct bio_set *bi_pool;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0];
};
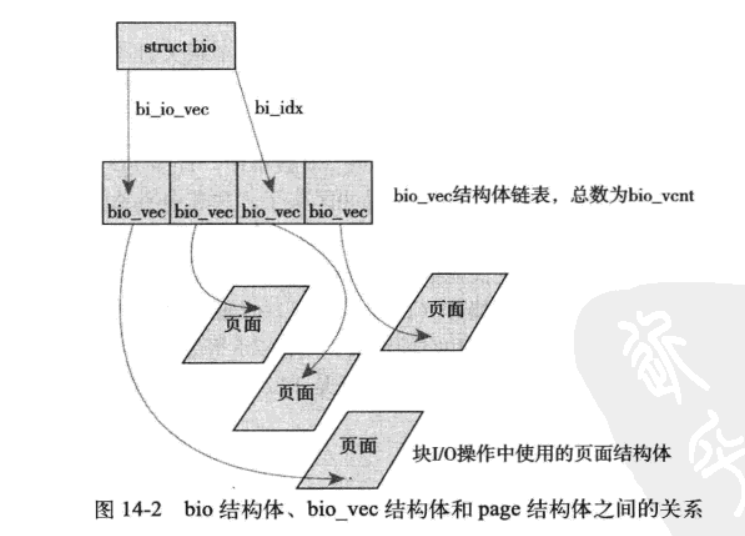
bio结构体的目的是代表现场正在执行的I/O操作,结构体中的主要域都是用来管理信息的,其中关键是bi_io_vecs、bi_vcnt和bi_idx。其关系如下:
14.3.1 I/O向量
参考链接: Linux中page、buffer_head、bio的联系
bi_io_vecs指向一个bio_vec结构体数组,该结构体链表包含了一个特定I/O操作所需要使用到的所有的片段。每个bio_vec结构都是一个形式为<page,offset,len>的向量。描述了片段对应的物理页、块在物理页中的偏移位置、从给定偏移量开始的块长度。整个结构体数组表示了一个完整的缓冲区。bio_vec结构体定义在linux/bio.h文件中:
struct bio_vec{
/* 指向这个缓冲区所驻留的物理页 */
struct page *bv_page;
/* 这个缓冲区以字节为单位的大小 */
unsigned int bv_len;
/* 缓冲区所驻留页中以字节为单位的偏移量 */
unsigned int bv_offset;
}
bi_vcnt用来描述bi_io_vec指向的数组中的片段数目。bi_idx域指向数组的当前索引。
每个I/O请求通过一个bio结构体描述,其中包含多个块(bio_vec).其操作的第一个片段由bi_io_vec结构体所指向,然后不断更新bi_idx直到达到bi_vcnt的最后一个片段。
bi_cnt域记录bio结构体使用计数,如果其值为0,就应该撤销该bio结构体
现在基本以bio结构体代替了buffer_head结构体有一下好处:
- 容易处理高端内存,它处理的是物理页而不是直接指针。
- bio结构体可以代表普通页I/O,同时也可以代表直接I/O
- 便于执行分散-集中(矢量化)块I/O操作,操作中的数据可取自多个物理页面
- 轻量级,它仅仅是一个矢量数组。
14.4 请求队列
块设备将它们挂起的I/O请求保存在请求队列中,该队列由resues_queue结构体表示。队列只要不为空,队列对应的块设备驱动程序就会从队列头获取请求,然后将其送入对应的块设备上去。每个请求可能由多个bio结构体组成。
注意:虽然磁盘上的块必须连续,但是在内存中这些块并不一定要连续
14.5 I/O调度程序(快表)
为了优化寻址操作,内核会在提交前,先执行名为合并(将多个请求结合成为一个新请求)与排序(请求按照扇区增长的方向有序排序)的预操作。内核中负责提交I/O请求的子系统名为I/O调度程序。(注意I/O调度和进程调度不同哟不要混淆)
14.5.2 Linux 电梯
详见,王道操作系统和linux 磁盘i/o电梯算法
14.5.3 最终期限I/O调度
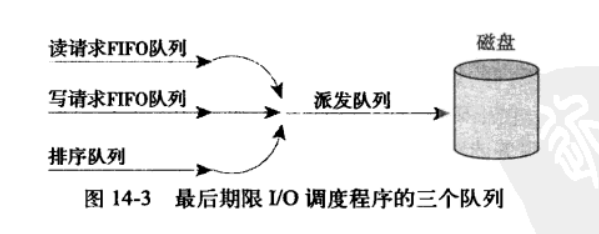
为了避免饥饿,设置最后期限,每个请求都有一个超时时间(默认为读500ms,写为5s),根据读写插入到特定的读/写FIFO队列中。新队列总是被加入到队列尾部,这样就避免了饥饿。最后期限I/O调度程序将请求从排序队列的头部去下,再推入到派发队列中,派发队列然后将请求提交给磁盘驱动,从而保证了最小化的请求寻址。如果请求超时,在从FIFO中提取请求进行服务。
注意:它并不能严格保证请求的响应时间。
14.5.4 预测I/O调度程序
读写分开造成了两次寻址,损害了全局吞吐量。预测调度在最终期限的基础上,添加了一个派发队列。并为每个队列设置了超时时间。主要是增加了预测启发能力。
提交骑牛之后们并不直接返回处理其它请求,而是会有意空闲片刻(空心啊时间可以设置,默认为6ms).可以上引用程序来提交其它读请求–任何对相邻磁盘位置操作的请求都会立刻得到处理。等待时间结束后,预测调度程序会重新返回原来的位置,继续执行以前剩下的请求。
相邻的请求到来,可以减少I/O的操作次数。
14.5.5 完全公正的排序I/O调度程序
完全公正调度(CFQ):将进入的I/O请求放入特定的队列中。队列分类与请求来自的进程有关。每个队列中,刚进入的请求与相邻请求合并在一起,并行插入分类。然后以时间片轮转调度队列,从每个队列中选取请求数,然后进行下一轮调度。确保每个进程结构公平的磁盘贷款片段。一般用于多媒体。
14.5.6 空操作的I/O调度程序
空操作不进行排序,也不进行其它形式的寻址操作。只有执行合并这一点。主要针对块设备。比如闪存卡。等没有寻道复返的块设备。为随机设备而设计
14.5.7 I/O调度程序的选择
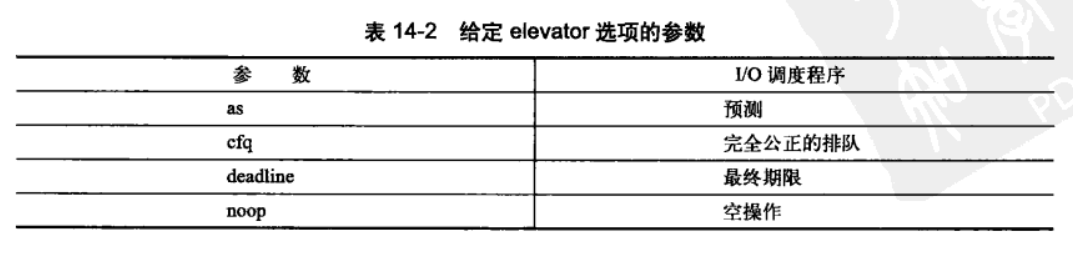
每一种调度程序都可以被启用,并内置在内核中。默认情况下,块设备使用完全公平的I/O调度程序。
第 15 章 进程地址空间
15.1 地址空间
参考链接:
进程地址空间,由可寻址的虚拟内存组成,内核允许进程使用这种虚拟内存中的地址。每个进程都有一个32位或64位的平坦(flat)地址空间(地址空间范围是一个独立的连续空间)。一些操作系统提供了段地址空间(被分段拥有)。每个进程都有唯一的平坦地址空间。一个进程的地址空间与另外一个进程的地址空间即使有相同的内存地址,实际上也彼此不相干–线程
内存地址是一个给定的值,一般是一个范围。这些可访问的合法地址空间为内存区域(memory areas).通过内核,进程可以给自己的地址空间动态的添加或者减少内存区域。
进程只能访问有效内存区域内的地址。如果一个进程以不正确的方式/非有效地址;内核会终止该进程。并返回“段错误的信息”。内存区域包含各种内存对象如下:
- 代码段(text section):代码内存映射
- 数据段(data section):已初始化全局变量的内存映射
- bss段(bss/零页):未初始化的全局变量,页面中的信息全部为0;
- 用户空间栈(stack):用于用户进程的零页内存映射。
- 内存映射段:使用mmap()映射的任何内存段
- c库或者动态链接程序等共享库的代码段、数据段
- 共享内存段:
- 匿名的内存映射,如由malloc()分配的内存。
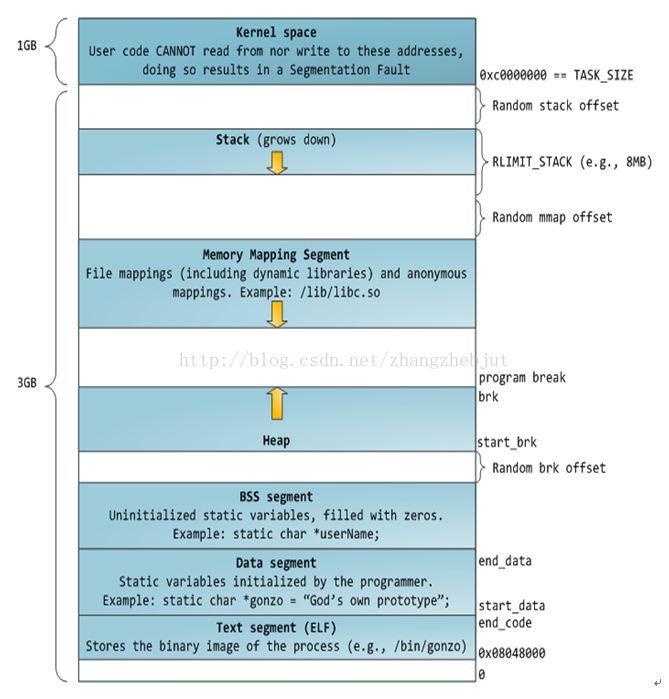
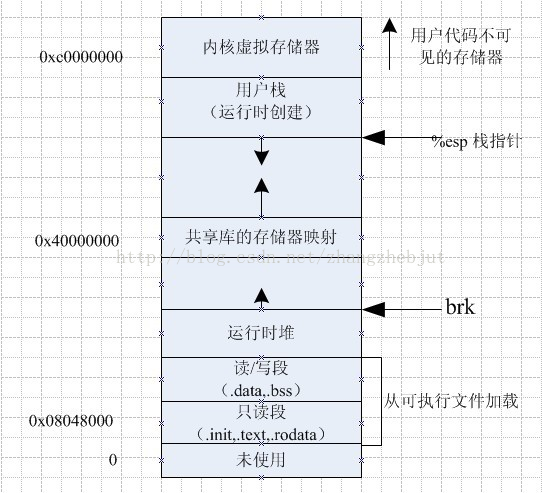

注意:
- 可执行文件和可执行程序是不同的。可执行文件由操作系统装载后才是可执行程序。
- 装载过程中如果发现函数是动态链接库符号,则会将动态链接库中相关数据一起装载。静态链接库无需此过程。
15.2 内存描述符
参考链接: Linux源码解析-内存描述符(mm_struct);
内核使用内存描述符结构体表示进程的地址空间,该结构包含了和地址空间有关的全部信息。
//include/linux/mm_types.h
struct mm_struct {
struct vm_area_struct * mmap; /* 虚拟内存区链表,指向线性区对象的链表头部 */
struct rb_root mm_rb; /* 指向线性区对象的红黑树*/
struct vm_area_struct * mmap_cache; /* last find_vma result 指向最近找到的虚拟区间 */
#ifdef CONFIG_MMU
/*用来在进程地址空间中搜索有效的进程地址空间的函数*/
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
/*释放线性区的调用方法*/
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
#endif
unsigned long mmap_base; /* base of mmap area ,内存映射区的基地址*/
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
pgd_t * pgd; /* 页表目录指针*/
atomic_t mm_users; /* How many users with user space?,共享进程的个数 */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1),主使用计数器,采用引用计数,描述有多少指针指向当前的mm_struct */
int map_count; /* number of VMAs ,线性区个数*/
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* Protects page tables and some counters,保护页表和引用计数的锁 (使用的自旋锁)*/
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage,进程拥有的最大页表数目 */
unsigned long hiwater_vm; /* High-water virtual memory usage ,进程线性区的最大页表数目*/
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
unsigned long start_code, end_code, start_data, end_data; /*维护代码区和数据区的字段*/
unsigned long start_brk, brk, start_stack; /*维护堆区和栈区的字段*/
unsigned long arg_start, arg_end, env_start, env_end; /*命令行参数的起始地址和尾地址,环境变量的起始地址和尾地址*/
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
mm_context_t context;
/* Swap token stuff */
/*
* Last value of global fault stamp as seen by this process.
* In other words, this value gives an indication of how long
* it has been since this task got the token.
* Look at mm/thrash.c
*/
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* 多线程支持 */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
#endif
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct *owner;
#endif
#ifdef CONFIG_PROC_FS
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
unsigned long num_exe_file_vmas;
#endif
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
};
mm_user记录正在使用该地址的进程数目。比如两个线程共享该地址孔昂见,则其值为2。同时mm_count(主题引用数目)也是1。mm_count为0表示没有引用了,该结构体就会被撤销。一般mm_users值为0之后,其才为0.当内存在一个地址空间上操作,并需要使用该地址相关的引用计数时内核便增加mm_count–mm_count存在的意义(区别主使用计数和使用该地址的进程数)
所有的mm_struct结构体都通过自身的mmlist域链接在一个双向链表中,该链表的首元素是init_mm内存描述符。操作该链表时,需要使用mmlist_lock锁来防止并发访问。
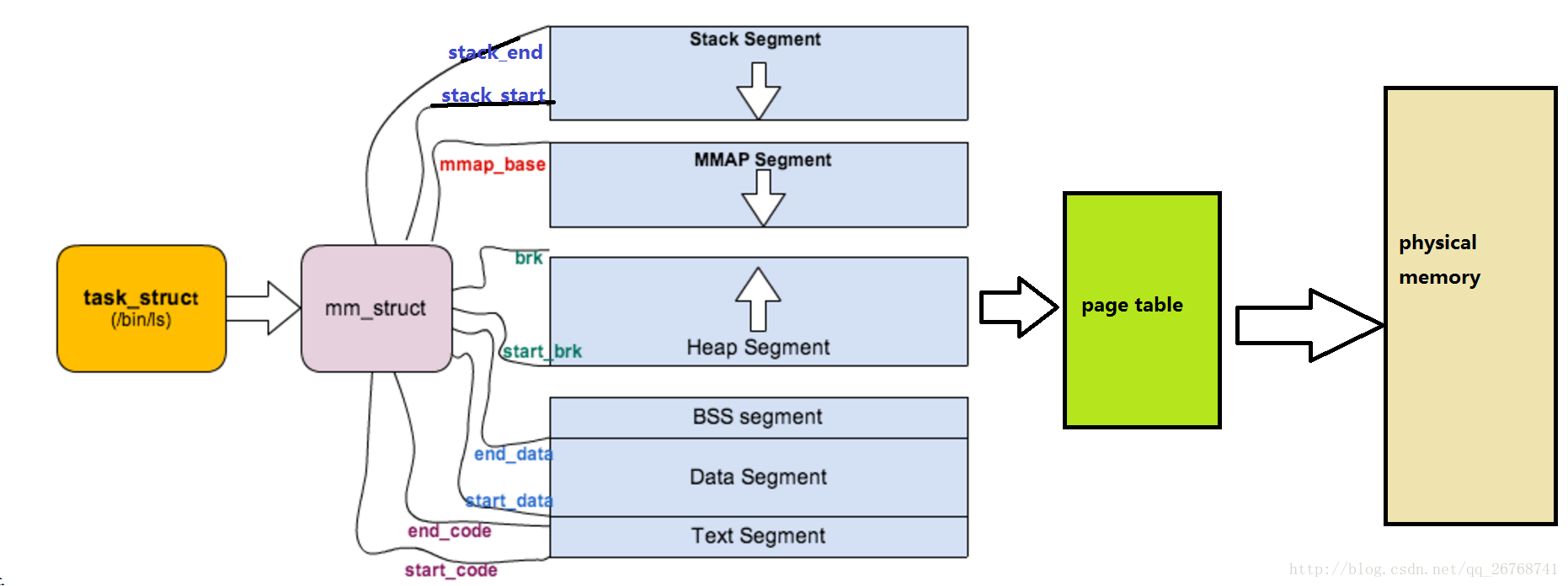
15.2.1 分配内存描述符
task_struct中的mm指向内存分配描述符。fork()函数利用copy_mm()函数复制父进程的内存描述符。mm_struct结构体,实际是通过allocate_mm()宏从mm_cachep_slab缓存中分配得到的。通常每个进程唯一。在调用clone时设置CLONE_VM标志共享地址空间;就会生成线程。copy_mm()将mm域指向其父进程的内存描述符。
15.2.2 撤销内存描述符
进程退出时,内核会调用exit_mm()函数,执行内存的销毁,同时更新一些统计量。函数调用mmput()函数减少内存描述中符的mm_users用户计数,如果计数为0,调用mmdrop()减少mm_count使用计数。使用计数也为0,则调用free_mm()宏通过kmem_cache_free()将mm_struct结构体归还到mm_cachep_slab中(注意理解进程销毁本质上是各种资源的回归。所有进程都是操作系统的子线程不过是可以占用资源罢了)
15.2.3 mm_struct与内核线程
内核线程,没有进程地址空间,没有相关的内存描述符,因此内核线程对应的进程描述符中mm域为空,没有用户上下文。当新的内核线程运行是,为了避免处理器周期向新地址空间进行切换,内核线程将直接使用前一个进程的内存描述符。(内核中共享内存)
当一个进程被调度时,该进程的mm指向的地址空间被装载到内存中,进程描述符中的active_mm域会被更新,指向新的地址空间,内核线程没有地址空间,mm为NULL,内核线程别调度时,内核发现它的mm为NULL。就会保留前一个进程的地址空间,随后跟新内核线程的active_mm域,使其指向前一个进程的内存描述符,使用前一个进程的页表;它们仅仅使用地址空间中内核相关的信息,基本和普通内存相同。
进程消失,mm_struct可能会被内核线程借用
15.3 虚拟内存区域
内存区域由vm_area_struct结构体描述。(逻辑)内存区域在Linux内核中常被称为虚拟内存区域(VMAS):指定地址空间上的一个独立内存范围描述符。内核将其作为一个内存对象进行管理。操作相同,只是指向的位置不同。VMA可以是内存映射文件或者进程用户空间栈
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* 区间首地址 */
unsigned long vm_end; /* 区间尾部地址 */
/* 前后链表指针, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
/* 数上该VMA的节点 */
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* 结构体所属的地址空间 */
pgprot_t vm_page_prot; /* VMA访问权限 */
unsigned long vm_flags; /* 标志 see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* 匿名VMA对象,Serialized by page_table_lock */
/* 指向结构体的相关操作表指针 */
const struct vm_operations_struct *vm_ops;
/* 存储中的文件偏移量 */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* 被映射的文件(可以为NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
#ifdef CONFIG_SWAP
atomic_long_t swap_readahead_info;
#endif
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
每个内存描述符和进程地址空间都唯一对应(VMA与mm_struct唯一对应)。内存区域位置是[vm_start,vm_end]。(同一个地址空间内的不同内存区间不能重叠)
15.3.1 VMA标志
主要是页面的行为和信息可能取值和含义如下:
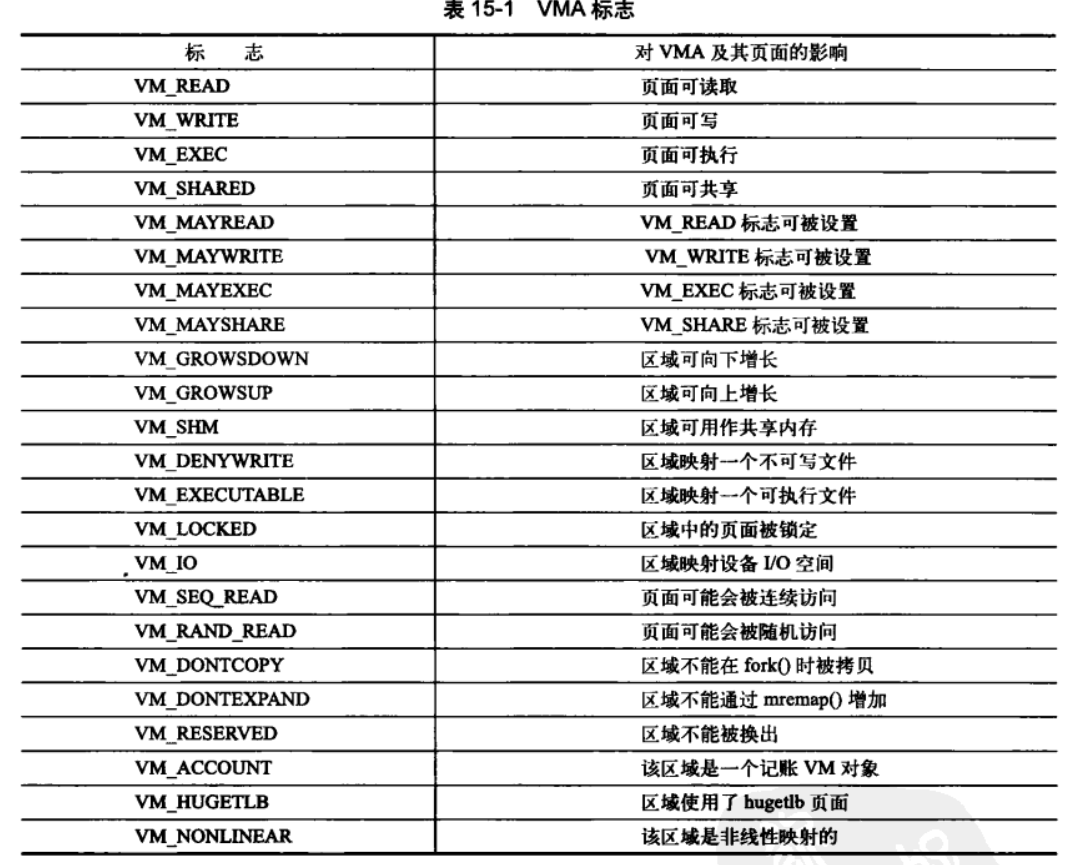
VM_IO在设备驱动程序中mmap()函数进行I/O空间映射时才被设置,该标志也表示内存区域不能被包含在任何进程的存放转存(core dump(coredump介绍;linux下core dump))
VM_SEQ_READ标志韩式内核应用程序对映射内容执行有序的(线性和连续的)读操作;这样内核可以有选择的执行预读文件.VM_RAND_READ与其刚好相反,映射内容执行随机的读操作,内核减少或者取消文件预读。
15.3.2 VMA相关操作
参考链接: 内存管理概述、内存分配与释放、地址映射机制(mm_struct, vm_area_struct)、malloc/free 的实现(必看)
虚拟内存结构如下:

- 内存映射模块(mmap):负责把磁盘文件的逻辑地址映射到虚拟地址,以及把虚拟地址映射到物理地址。
- 交换模块(swap):负责控制内存内容的换入和换出,它通过交换机制,使得在物理内存的页面(RAM 页)中保留有效的页 ,即从主存中淘汰最近没被访问的页,保存近来访问过的页。
- 核心内存管理模块(core):负责核心内存管理功能,即对页的分配、回收、释放及请页处理等,这些功能将被别的内核子系统(如文件系统)使用。
- 结构特定的模块:负责给各种硬件平台提供通用接口,这个模块通过执行命令来改变硬件MMU 的虚拟地址映射,并在发生页错误时,提供了公用的方法来通知别的内核子系统。这个模块是实现虚拟内存的物理基础。

struct vm_operations_struct
{
/* 将指定的内存区域加入到地址空间 */
void (*open)(struct vm_area_struct *area);
/* 将指定的内存区域从地址空间删除,该函数被调用 */
void (*close)(struct vm_area_struct *area);
/* 等没有出现在物理内存中的页面被访问时,该函数被页面故障处理调用 */
*int (*fault) (struct vm_area_struct *,struct vm_fault*);
/* 页面为只读是,该函数被页面故障处理调用 */
*int page_mkwrite(struct vm_area_struct *area,struct vm_fault *vmf);
/* get_user_pages()函数调用失败时,该函数被access_process_vm()调用 */
*int access(struct vm_area_struct *vma,unsigned long address,void *buf,int len,int write)
};
15.3.3 内存区域的树型结构和内存区域的链表结构
内存描述符中的mmap和mm_rb之一访问内存区域。它们包含完全相同的vm_area)struct结构体的指针,仅仅组织方法不同。内核为了内存区域上的各种不同操作都能获得高性能,同时使用了这两种数据结构。
15.3.4 实际使用中的内存域
可以使用/proc文件系统和pmap工具查看给定的进程内存空间和其中所含的内存区域。
如使用cat /proc/24027/maps查看htop的全部内存域如下:
#开始地址-结束地址 访问权限 偏移 主:次设备号 i节点 文件
55cebaed2000-55cebaef9000 r-xp 00000000 08:0e 2100205 /usr/bin/htop
55cebb0f9000-55cebb0fa000 r--p 00027000 08:0e 2100205 /usr/bin/htop
55cebb0fa000-55cebb0fe000 rw-p 00028000 08:0e 2100205 /usr/bin/htop
55cebb0fe000-55cebb0ff000 rw-p 00000000 00:00 0
55cebc1b7000-55cebcdb8000 rw-p 00000000 00:00 0 [heap]
7fcb4c0a8000-7fcb4c0b3000 r-xp 00000000 08:0c 548535 /lib/x86_64-linux-gnu/libnss_files-2.23.so
7fcb4c0b3000-7fcb4c2b2000 ---p 0000b000 08:0c 548535 /lib/x86_64-linux-gnu/libnss_files-2.23.so
7fcb4c2b2000-7fcb4c2b3000 r--p 0000a000 08:0c 548535 /lib/x86_64-linux-gnu/libnss_files-2.23.so
7fcb4c2b3000-7fcb4c2b4000 rw-p 0000b000 08:0c 548535 /lib/x86_64-linux-gnu/libnss_files-2.23.so
7fcb4c2b4000-7fcb4c2ba000 rw-p 00000000 00:00 0
7fcb4c2ba000-7fcb4c2c5000 r-xp 00000000 08:0c 548528 /lib/x86_64-linux-gnu/libnss_nis-2.23.so
7fcb4c2c5000-7fcb4c4c4000 ---p 0000b000 08:0c 548528 /lib/x86_64-linux-gnu/libnss_nis-2.23.so
7fcb4c4c4000-7fcb4c4c5000 r--p 0000a000 08:0c 548528 /lib/x86_64-linux-gnu/libnss_nis-2.23.so
7fcb4c4c5000-7fcb4c4c6000 rw-p 0000b000 08:0c 548528 /lib/x86_64-linux-gnu/libnss_nis-2.23.so
7fcb4c4c6000-7fcb4c4dc000 r-xp 00000000 08:0c 548533 /lib/x86_64-linux-gnu/libnsl-2.23.so
7fcb4c4dc000-7fcb4c6db000 ---p 00016000 08:0c 548533 /lib/x86_64-linux-gnu/libnsl-2.23.so
7fcb4c6db000-7fcb4c6dc000 r--p 00015000 08:0c 548533 /lib/x86_64-linux-gnu/libnsl-2.23.so
7fcb4c6dc000-7fcb4c6dd000 rw-p 00016000 08:0c 548533 /lib/x86_64-linux-gnu/libnsl-2.23.so
7fcb4c6dd000-7fcb4c6df000 rw-p 00000000 00:00 0
7fcb4c6df000-7fcb4c6e7000 r-xp 00000000 08:0c 548539 /lib/x86_64-linux-gnu/libnss_compat-2.23.so
7fcb4c6e7000-7fcb4c8e6000 ---p 00008000 08:0c 548539 /lib/x86_64-linux-gnu/libnss_compat-2.23.so
7fcb4c8e6000-7fcb4c8e7000 r--p 00007000 08:0c 548539 /lib/x86_64-linux-gnu/libnss_compat-2.23.so
7fcb4c8e7000-7fcb4c8e8000 rw-p 00008000 08:0c 548539 /lib/x86_64-linux-gnu/libnss_compat-2.23.so
7fcb4c8e8000-7fcb4ce1f000 r--p 00000000 08:0e 730626 /usr/lib/locale/locale-archive
7fcb4ce1f000-7fcb4ce22000 r-xp 00000000 08:0c 548520 /lib/x86_64-linux-gnu/libdl-2.23.so
7fcb4ce22000-7fcb4d021000 ---p 00003000 08:0c 548520 /lib/x86_64-linux-gnu/libdl-2.23.so
7fcb4d021000-7fcb4d022000 r--p 00002000 08:0c 548520 /lib/x86_64-linux-gnu/libdl-2.23.so
7fcb4d022000-7fcb4d023000 rw-p 00003000 08:0c 548520 /lib/x86_64-linux-gnu/libdl-2.23.so
7fcb4d023000-7fcb4d03a000 r-xp 00000000 08:0c 559690 /lib/x86_64-linux-gnu/libgcc_s.so.1
7fcb4d03a000-7fcb4d239000 ---p 00017000 08:0c 559690 /lib/x86_64-linux-gnu/libgcc_s.so.1
7fcb4d239000-7fcb4d23a000 r--p 00016000 08:0c 559690 /lib/x86_64-linux-gnu/libgcc_s.so.1
7fcb4d23a000-7fcb4d23b000 rw-p 00017000 08:0c 559690 /lib/x86_64-linux-gnu/libgcc_s.so.1
7fcb4d23b000-7fcb4d40d000 r-xp 00000000 08:0e 725176 /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.26
7fcb4d40d000-7fcb4d60d000 ---p 001d2000 08:0e 725176 /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.26
7fcb4d60d000-7fcb4d618000 r--p 001d2000 08:0e 725176 /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.26
7fcb4d618000-7fcb4d61b000 rw-p 001dd000 08:0e 725176 /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.26
7fcb4d61b000-7fcb4d61e000 rw-p 00000000 00:00 0
7fcb4d61e000-7fcb4d636000 r-xp 00000000 08:0c 548522 /lib/x86_64-linux-gnu/libpthread-2.23.so
7fcb4d636000-7fcb4d835000 ---p 00018000 08:0c 548522 /lib/x86_64-linux-gnu/libpthread-2.23.so
7fcb4d835000-7fcb4d836000 r--p 00017000 08:0c 548522 /lib/x86_64-linux-gnu/libpthread-2.23.so
7fcb4d836000-7fcb4d837000 rw-p 00018000 08:0c 548522 /lib/x86_64-linux-gnu/libpthread-2.23.so
7fcb4d837000-7fcb4d83b000 rw-p 00000000 00:00 0
7fcb4d83b000-7fcb4d9fb000 r-xp 00000000 08:0c 548538 /lib/x86_64-linux-gnu/libc-2.23.so
7fcb4d9fb000-7fcb4dbfb000 ---p 001c0000 08:0c 548538 /lib/x86_64-linux-gnu/libc-2.23.so
7fcb4dbfb000-7fcb4dbff000 r--p 001c0000 08:0c 548538 /lib/x86_64-linux-gnu/libc-2.23.so
7fcb4dbff000-7fcb4dc01000 rw-p 001c4000 08:0c 548538 /lib/x86_64-linux-gnu/libc-2.23.so
7fcb4dc01000-7fcb4dc05000 rw-p 00000000 00:00 0
7fcb4dc05000-7fcb4dd0d000 r-xp 00000000 08:0c 548541 /lib/x86_64-linux-gnu/libm-2.23.so
7fcb4dd0d000-7fcb4df0c000 ---p 00108000 08:0c 548541 /lib/x86_64-linux-gnu/libm-2.23.so
7fcb4df0c000-7fcb4df0d000 r--p 00107000 08:0c 548541 /lib/x86_64-linux-gnu/libm-2.23.so
7fcb4df0d000-7fcb4df0e000 rw-p 00108000 08:0c 548541 /lib/x86_64-linux-gnu/libm-2.23.so
7fcb4df0e000-7fcb4df33000 r-xp 00000000 08:0c 527167 /lib/x86_64-linux-gnu/libtinfo.so.5.9
7fcb4df33000-7fcb4e132000 ---p 00025000 08:0c 527167 /lib/x86_64-linux-gnu/libtinfo.so.5.9
7fcb4e132000-7fcb4e136000 r--p 00024000 08:0c 527167 /lib/x86_64-linux-gnu/libtinfo.so.5.9
7fcb4e136000-7fcb4e137000 rw-p 00028000 08:0c 527167 /lib/x86_64-linux-gnu/libtinfo.so.5.9
7fcb4e137000-7fcb4e164000 r-xp 00000000 08:0c 527077 /lib/x86_64-linux-gnu/libncursesw.so.5.9
7fcb4e164000-7fcb4e364000 ---p 0002d000 08:0c 527077 /lib/x86_64-linux-gnu/libncursesw.so.5.9
7fcb4e364000-7fcb4e365000 r--p 0002d000 08:0c 527077 /lib/x86_64-linux-gnu/libncursesw.so.5.9
7fcb4e365000-7fcb4e366000 rw-p 0002e000 08:0c 527077 /lib/x86_64-linux-gnu/libncursesw.so.5.9
7fcb4e366000-7fcb4e38d000 r-xp 00000000 08:0e 654606 /usr/lib/libtcmalloc_minimal.so.4.2.6
7fcb4e38d000-7fcb4e58c000 ---p 00027000 08:0e 654606 /usr/lib/libtcmalloc_minimal.so.4.2.6
7fcb4e58c000-7fcb4e58d000 r--p 00026000 08:0e 654606 /usr/lib/libtcmalloc_minimal.so.4.2.6
7fcb4e58d000-7fcb4e58e000 rw-p 00027000 08:0e 654606 /usr/lib/libtcmalloc_minimal.so.4.2.6
7fcb4e58e000-7fcb4e5b3000 rw-p 00000000 00:00 0
7fcb4e5b3000-7fcb4e5d9000 r-xp 00000000 08:0c 548521 /lib/x86_64-linux-gnu/ld-2.23.so
7fcb4e77e000-7fcb4e786000 rw-p 00000000 00:00 0
7fcb4e7d0000-7fcb4e7d7000 r--s 00000000 08:0e 918486 /usr/lib/x86_64-linux-gnu/gconv/gconv-modules.cache
7fcb4e7d7000-7fcb4e7d8000 rw-p 00000000 00:00 0
7fcb4e7d8000-7fcb4e7d9000 r--p 00025000 08:0c 548521 /lib/x86_64-linux-gnu/ld-2.23.so
7fcb4e7d9000-7fcb4e7da000 rw-p 00026000 08:0c 548521 /lib/x86_64-linux-gnu/ld-2.23.so
7fcb4e7da000-7fcb4e7db000 rw-p 00000000 00:00 0
7ffe68218000-7ffe6823a000 rw-p 00000000 00:00 0 [stack]
7ffe68366000-7ffe68369000 r--p 00000000 00:00 0 [vvar]
7ffe68369000-7ffe6836b000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
显示了内存空间的全部内存域。
注意:多个进程都链接同一个so动态库,代码段共享,数据段不共享(动态链接库被多个进程访问;多个进程间共享动态链接库的原理多进程引用的动态链接库中的全局变量问题).因此多进程调用相同的动态链接库,它的内存地址也是不同的。windows中的dll中的全局变量在被读取是是共享变量,但是当其被写时复制多个页,对应进程不同的数据,保证数据的独立性,这样即节省了资源右保证了数据的独立性。在Linux中,载入的动态链接库实际上可以直接使用外部框架或者其他模块的全局数据,但是在Windows下确是隔离的,不能直接访问到。但是在Linux中的写拷贝机制,使得不能使用动态链接库进行进程间通信。但是windows可以。动态链接库中的全局变量可能因为多次引用造成重复初始化.
15.4 操作内存区域
对内存区域的查找和验证。
15.4.1 find_vmal()
/* 查找第一个vm_end大于addr的区域 */
struct vm_area_struct *find_vmal(struct mm_struct *mm,unsigned long addr){
/* 通过搜索红黑树进行查找,返回起始值不一定是addr,因为需要查找连续的内存 */
/* 提前定义结果 */
struct vm_area_struct *vma=NULL;
if(mm){
vma=mm->mmap_cache;
/* 检查是否符合要求 */
if(!(vma&&vma->vm_end>addr&&vma->vm_start<=addr)){
struct rb_node *rb_node;
/* 获取红黑树的根节点 */
rb_node=mm->mm_rb.rb_node;
vma=NULL;
/* 遍历红黑树 */
while(rb_node){
struct vm_area_struct *vma_tmp;
/* 查找内存范围 */
vma_tmp=rb_entry(rb_node,struct vm_area_struct,vm_rb);
/* 尾部地址大于addr */
if(vma_tmp->vm_end>addr){
vma=vma_tmp;
/* 再次校验 符合要求直接返回*/
if(vma_tmp->vm_start<=addr)
break;
/* 没找到遍历左子树 */
rb_node=rb_node->rb_left;
}else{
/* 遍历右子树 */
rb_node=rb_node->rb_right;
}
}
/* 更新mmap_cache指针 */
if(vma) mm->mmap_cache=vma;
}
}
return vma;
}
15.4.2 find_vma_perv()
其和find_vma()方式相同,不过返回第一个小于addr的VMA.该函数声明在mm/mmap.c和文件<linux/mm.h>中
struct vm_area_struct *find_vma_prev(struct mm_struct *mm,unsigned long addr,struct vm_area_struct **pprev);
15.4.3 find_vma_intersection()
返回第一个和指定地址区间相交的VMA.该函数内联在文件<linux/mm.h>中:
static inline struct vm_area_struct *
find_vma_intersection(struct mm_struct *mm,
unsigned long start_addr,
unsigned long end_addr)
{
struct vm_area_struct *vma;
vma=find_vma(mm,start_addr);
if(vma&&end_addr<=vma->vm_start) vm=NULL;
return vma;
}
15.5 mmap()和do_mmap():创建地址区间
内核使用do_mmap()函数创建一个新的线性地址区间。如果创建的地址区间和一个已经存在的相邻,并且具有相同的访问权限,两个区间将合并为一个。如果不能合并就创建一个新的VMA了。其函数定义如下:
unsigned long do_mmap(
struct file *file, /* 指定映射源文件 */
unsigned long addr, /* 可选,指定搜索空闲区域的起始位置 */
unsigned long len,
unsigned long port,
unsigned long flag,
unsigned long offset /* 映射的文件偏移 */
);
prot参数和flag可选参数如下:
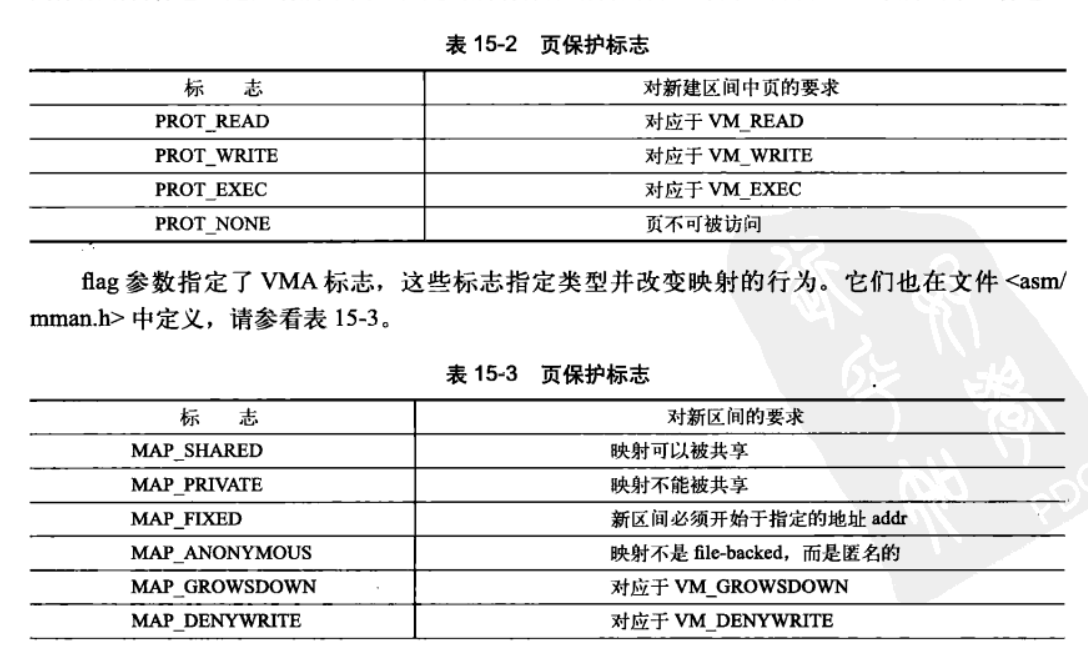

15.6 mummap()和do_mummap()删除地址区间
do_mummap()函数从特定的进程地址空间中删除指定地址区间
int do_mummap(struct mm_struct *m,unsigned long start,size_t len);
int munmap(void *start,size_t length);
相关系统调用使用sys_munmap.是对do_mummap()函数的一个简单的封装
asmlinkage long sys_munmmap(unsigned long addr,size_t len)
{
int ret;
struct mm_struct *mm;
mm=current->mm;
down_write(&mm->mmap_sem);
ret=do_mummap(mm,addr,len);
up_write(&mm->mmap_sem);
return ret;
}
15.7 页表
32位操作系统中使用三级页表进行地址转换;转换过程如下:
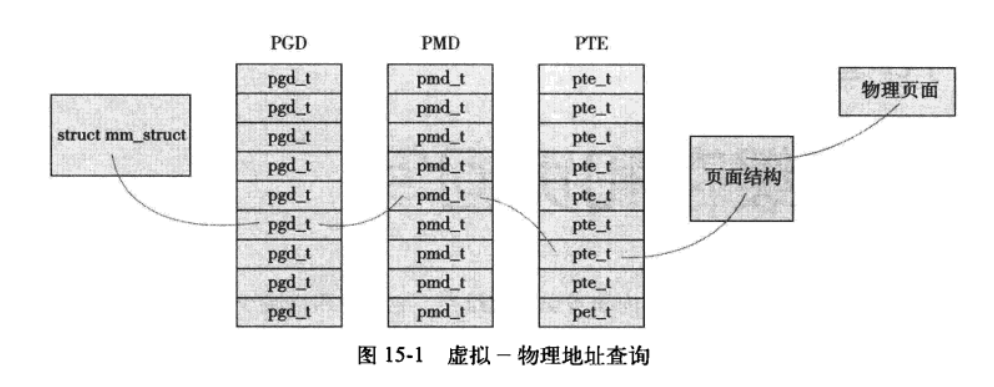
多数体系结构,实现了一个翻译后缓冲器(TLB,块表)。TLB作为一个将虚拟地址映射到物理地址的硬件缓存。
Linux中使用写时拷贝的方式共享页表。