NVCC学习笔记
参考链接: NVCC Introduction;nvcc编译器参数;
2019-1-17
CUDA编译流程简介
参考链接: NVCC CUDA编译流程;
NVCC是一种编译器驱动,通过命令行选项可以在不同阶段启动不同的工具完成编译工作,其目的在于隐藏了复杂的CUDA编译细节,并且它不是一个特殊的CUDA编译驱动而是在模仿一般的通用编译驱动如gcc,它接受一定的传统编译选项如宏定义,库函数路径以及编译过程控制等。所有非CUDA编译步骤扔给通用的C编译器,在Windows下是MS的”cl”编译器,而在Linux下是gcc。CUDA程序编译的路径会因在编译选项时设置的不同CUDA运行模式而不同,如模拟环境的设置等。nvcc封装了四种内部编译工具:
- nvopencc : (C:\CUDA\open64\bin)
- ptxas
- fatbin
- cudafe
NVCC 编译流程
- 预处理:
输入的cu文件有一个预处理过程,这一过程包括的步骤有将该源文件里的宏以及相关引用文件扩展开,然后将预编译已经产生的与C有关的CUDA系统定义的宏扩展开,并合并分支编译的结果。CUDA源文件经过预处理过程后会生成具有.cup后缀名的经过预处理的源文件,经过预处理的源文件是再现程序bug的最好形式。通常,这个预处理过程是隐式完成的,如果想要显示执行,可以用命令
nvcc -E x.cu -o x.cup或nvcc -E x.cu > x.cup来实现。 - 前后端设备分离: 将预处理的结果送给CUDA前端,即CUDAfe。通过CUDAfe分离源文件,然后调用不同的编译器分别编译。cudafe被称为CUDA frontend,会被调用两次,完成两个工作:一是将主机代码与设备代码分离,生成gpu文件,二是对gpu文件进行dead code analysis,传给nvopencc,未来的版本可能没有第二次调用。 Nvopencc生成ptx文件传给ptxas,最后将cubin或ptx传给fatbin组合成一个设备代码描述符。
- 生成编译代码: 编译阶段CUDA源代码对C语言所扩展的部分将被转成regular ANSI C的源文件,也就可以由一般的C编译器进行更多的编译和连接。也即是设备代码被编译成ptx(parallel thread execution)代码和/或二进制代码,host代码则以C文件形式输出,在编译时可将设备代码描述符链接到所生成的host代码,将其中的cubin对象作为全局初始化数据数组包含进来,但此时,kernel执行配置也要被转换为CUDA运行启动代码,以加载和启动编译后的kernel。在调用CUDA驱动API时,CUDA运行时系统会查看这个描述符,根据当前的GPU load一块具有合适ISA的image,然后便可单独执行ptx代码或cubin对象,而忽略nvcc编译得到的host代码。 Nvcc的各个编译阶段以及行为是可以通过组合输入文件名和选项命令进行选择的。它是不区分输入文件类型的,如object, library or resource files,仅仅把当前要执行编译阶段需要的文件传递给linker。
NVCC编译过程和兼容性详解
参考链接: NVCC编译过程和兼容性详解;
CUDA编译阶段将源文件中包含C++ externed(cuda 相关代码)的内容变换到标准的C++代码,然后交给c++编译器进行进一步的编译和链接。如图:

NVCC主要编译流程上文中有简单描述;主要注意的是fatbinary,fatbinary,fat是肥的意思,(这里简单讲解,下文会有深入的理解),为了让应用程序适应不同的GPU,fatbinary里可能会有多种GPU的实现,程序在运行的时候会根据自己的特点选择合适的最高效的GPU实现进行运行: CUDA 运行时系统(GPU驱动程序)会监视fatbinary文件中的内容,每次程序运行时,CUDA 运行时系统(GPU驱动程序)都会找到fatbinary中最合适部分并映射到当前GPU。(fatbinary会有适合不同的GPU的实现);
GPU 中的“代”
GPU中的代是指NVIDIA GPU架构和计算能力的评价标准,如sm_30、sm_70,sm_50等;分别对应不同的GPU架构;算能力高的GPU可以运行编译成低代的程序,反之则不行,如计算能力6.1的GPU可以运行编译成compute_30,sm_30的程序);一个GPU代中的二进制兼容性可以在某些条件下得到保证,因为它们共享基本的指令集。 两个GPU版本之间的情况就是这样,它没有功能上的差异(例如,当一个版本是另一个版本的缩小版本时),或者一个版本在功能上被包含在另一个版本中。 后者的一个例子是基础的Kepler版本sm_30,其功能是所有其他Kepler版本的子集:针对sm_30编译的任何代码将在所有其他Kepler GPU上运行。
GPU中的小“代”
除了sm_20,sm_30,sm_50,sm_60这些大的代号,还有sm_21, sm_35, sm_53 ,sm_61这些小代,这些小代不会做大的改变,会有一些小的调整,如调整寄存器和处理器集群的数量,这只影响执行性能,不会改变功能。程序更精确的对应GPU代号可能可以达到最佳性能。
GPU中的应用程序兼容性
参考链接: Matching CUDA arch and CUDA gencode for various NVIDIA architectures
–两端式编译结构,真实GPU与虚拟GPU;
- CUDA程序的编译必须经历两个过程,即虚拟框架和真实框架,虚拟框架决定了程序最小的可运行GPU框架,而真实框架决定了程序可运行的最小的实际GPU。 例如-arch=compute_30;-code=sm_30表示计算能力3.0及以上的GPU都可以运行编译的程序。但计算能力2.0的GPU就不能运行了。
- 即时编译(Just-In-Time)机制让程序可以在大的GPU框架内动态选择与电脑GPU最合适的小代。
- –generate-code保证用户GPU可以动态选择最适合的GPU框架(最适合GPU的大代和小代)。
CPU中不同代CPU应用程序的兼容性很好,已发布的指令集体系结构是确保当这些分布式应用程序成为主流时能够继续在新版CPU上运行的常用机制。这种情况对于GPU而言是不同的,因为NVIDIA不能保证二进制兼容性,nvcc依靠两阶段编译模型来确保应用程序与未来GPU世代的兼容性。即虚拟架构和真实架构:虚拟架构确定编译成的代号的功能,真实架构确定编译成的真实代号的功能和性能。
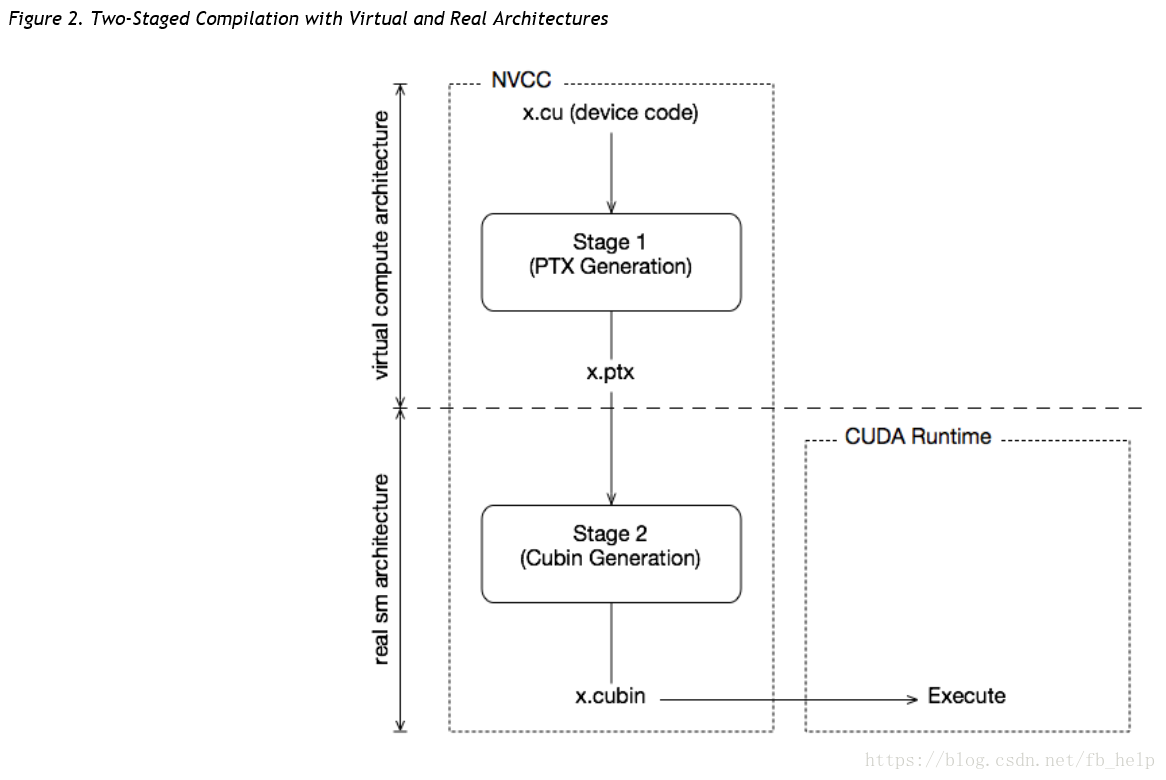
虚拟GPU与真实GPU之间向上兼容;当虚拟GPU版本低于真实GPU时程序能够正常运行;NVIDIA中即时编译(JIT)能够好的体现兼容性。虚拟GPU架构特性表如下:
| 虚拟列表 | 添加的新特性 |
|---|---|
| compute_30 and compute_32 | Basic features,Kepler support,Unified memory programming |
| compute_35 | Dynamic parallelism support |
| compute_50, compute_52, and compute_53 | Maxwell support |
| compute_60, compute_61, and compute_62 | Pascal support |
| compute_70 and compute_72 | Volta support |
| compute_75 | Turing support |
NVIDIA GPU真实架构如下:
| 真实的架构 | 功能更新 |
|---|---|
| sm_30 and sm_32 | Basic features,Kepler support |
| sm_35 | Dynamic parallelism support |
| sm_50, sm_52, and sm_53 | Maxwell support |
| sm_60, sm_61, and sm_62 | Pascal support |
| sm_70 | Volta support |
| sm_75 | Turing support |
NVIDIA SM与compute对应的真实显卡
| 标志参数 | 对应架构 | 对应显卡型号系列 |
|---|---|---|
| SM20 or SM_20, compute_30 | Fermi cards (CUDA 3.2 until CUDA 8) | GeForce 400, 500, 600, GT-630 |
| SM_30, compute_30 | Kepler cards (CUDA 5 until CUDA 10) | Kepler architecture (e.g. generic Kepler, GeForce 700, GT-730) |
| SM35 or SM_35, compute_35 | Kepler cards (CUDA 5 until CUDA 10) | Tesla K40 |
| SM37 or SM_37, compute_37 | Kepler cards (CUDA 5 until CUDA 10) | Tesla K80 |
| SM_50, compute_50 | Maxwell cards (CUDA 6 until CUDA 11) | Tesla/Quadro M series |
| SM52 or SM_52,compute_52 | Maxwell cards (CUDA 6 until CUDA 11) | Quadro M6000 , GeForce 900, GTX-970, GTX-980, GTX Titan X |
| SM53 or SM_53, compute_53 | Maxwell cards (CUDA 6 until CUDA 11) | Tegra (Jetson) TX1 / Tegra X1, Drive CX, Drive PX, Jetson Nano |
| SM60 or SM_60, compute_60 | Pascal (CUDA 8 and later) | Quadro GP100, Tesla P100, DGX-1 (Generic Pascal) |
| SM61 or SM_61, compute_61 | Pascal (CUDA 8 and later) | GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030, Titan Xp, Tesla P40, Tesla P4, Discrete GPU on the NVIDIA Drive PX2 |
| SM62 or SM_62, compute_62 | Pascal (CUDA 8 and later) | Integrated GPU on the NVIDIA Drive PX2, Tegra (Jetson) TX2 |
| SM70 or SM_70, compute_70 | Volta (CUDA 9 and later) | DGX-1 with Volta, Tesla V100, GTX 1180 (GV104), Titan V, Quadro GV100 |
| SM72 or SM_72, compute_72 | Volta (CUDA 9 and later) | Jetson AGX Xavier, Drive AGX Pegasus, Xavier NX |
| SM75 or SM_75, compute_75 | Turing (CUDA 10 and later) | GTX/RTX Turing – GTX 1660 Ti, RTX 2060, RTX 2070, RTX 2080, Titan RTX, Quadro RTX 4000, Quadro RTX 5000, Quadro RTX 6000, Quadro RTX 8000, Quadro T1000/T2000, Tesla T4 |
| SM80 or SM_80, compute_80 | Ampere (CUDA 11 and later) | NVIDIA A100 (the name “Tesla” has been dropped – GA100), NVIDIA DGX-A100 |
| SM86 or SM_86, compute_86 | Ampere (CUDA 11 and later) | Tesla GA10x cards, RTX Ampere – RTX 3080, GA102 – RTX 3090, RTX A6000, RTX A40 |
| SM90 or SM_90, compute_90 | Hopper (CUDA 12 [planned] and later) | NVIDIA H100 (GH100) |
NVCC在提高兼容性的处理方式上采用了两种机制:即时编译(JIT)和fatbinaries
即时编译(Just-In-Time)
过指定虚拟代码架构而不是真实的GPU,nvcc推迟PTX代码的组装,直到应用程序运行时(目标GPU完全已知)。 例如,当应用程序在sm_50或更高版本的架构上启动时,下面的命令允许生成完全匹配的GPU二进制代码。
Just-in-Time Compilation of Device Code;
nvcc xx.cu –gpu-architecture=compute_50 –gpu-code=compute_50
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_52
即使编译,即程序运行时,再根据当前的GPU编译成自己计算能力动态编译成应用程序。这就可以让GPU选择想要的版本进行编译。即双compute_的组合。但这种只能保证同一代的兼容性。 注意:当GPU计算能力低于编译的虚拟框架时,JIT将失败。
使用--generate-code可以编译多种GPU架构的代码。
nvcc x.cu \
--generate-code arch=compute_50,code=sm_50 \
--generate-code arch=compute_50,code=sm_52 \
--generate-code arch=compute_53,code=sm_53
nvcc x.cu \
--generate-code arch=compute_50,code=compute_50 \
--generate-code arch=compute_53,code=compute_53
nvcc x.cu \
--generate-code arch=compute_50,code=[sm_50,sm_52] \
--generate-code arch=compute_53,code=sm_53
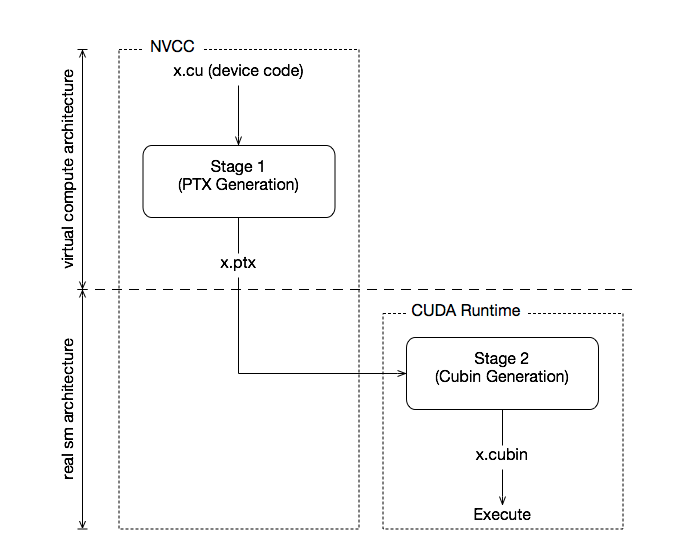
使用CUDA分离编译
cuda5之后支持在设备上分离编译的模式,但是仍然以一个文件作为默认编译方式可以通过添加 --device-c 参数来实现分离编译,再使用--device-link来进行相关的链接。
过程如下图所示:

单个的编译流程和上图相似。
注意
- 编译过程中的32/64中间文件,会产生错误链接。
- 设备编译的.o文件必须链接到host编译的.o文件,否则会产生_cudaRegisterLinkedBinary_name错误
- 分离编译中的
__CUDA_ARCH__关键字不能出现在header中,因为不同的目标可能包含不同的行为。如果都包含在header中并且依赖__CUDA_ARCH__在链接时就会产生错误。多个版本中的行为只有一个会被使用。 -
-keep选项可以让文件在当前文件夹中被编译,这样中间文件不会放在临时文件夹中。 - 当使用
--keep时,清除文件,需要使用--keep --clean-targets。否则文件不能被正常清除。 - 使用
nvcc --resource-usage acos.cu输出文件的相关注册信息。
代码的适应性更改
使用static关键字,可能得到多个设备符号在不同的文件中
Fatbinaries
在JIT中克服启动延迟,同时仍允许在新GPU上执行的另一种解决方案是指定多个代码实例,如nvcc x.cu –gpu-architecture = compute_50 –gpu-code = compute_50,sm_50,sm_52该命令为两个Kepler变体生成精确代码,以及在遇到下一代GPU时由JIT使用的PTX代码。nvcc将其设备代码组织在fatbinaries中,这些代码能够保存相同GPU源代码的多个翻译。在运行时,CUDA驱动程序将在设备功能启动时选择最合适的翻译。
即一次保存多个精确的真实框架的二进制结果,当程序被传给GPU时,GPU选择最好的结果,因为一次性加入了多个真实框架,所以被称为‘fat‘。但这也仅仅是保证了大代之间的兼容性。
在编译参数选择时也可以使用-generate-code参数,他会在编译时产生不同代的PTX再配合JIT或者fatbinary实现所有GPU兼容。因此在使用cuda程序兼容性的时候,指定虚拟架构决定cuda运行下限,再通过指定-generate-code或者-gpu-code=xxx,xxxx,xxxx,...实现程序的兼容性;
NVCC 参数解析
参考链接: CUDA_Compiler_Driver_NVCC;
C++ NVCC编译参数关键字
NVCC关键字有如下:
| 关键字 | 作用描述 |
|---|---|
__NVCC__ |
Defined when compiling C/C++/CUDA source files |
__CUDACC__ |
Defined when compiling CUDA source files |
__CUDACC_RDC__ |
Defined when compiling CUDA sources files in relocatable device code mode |
__CUDACC_DEBUG__ |
Defined when compiler CUDA source files in the device-debug mode |
__CUDACC_RELAXED_CONSTEXPR__ |
Defined when the --expt-relaxed-constexpr flag is specified on the command line |
__CUDACC_EXTENDED_LAMBDA__ |
Defined when the --expt-extended-lambda flag is specified on the command line |
__CUDACC_VER_MAJOR__ |
Defined with the major version number of nvcc
|
__CUDACC_VER_MINOR__ |
Defined with the minor version number of nvcc
|
__CUDACC_VER_BUILD__ |
Defined with the build version number of nvcc
|
NVCC中文件类型和解析:
| Input File Prefix | Description |
|---|---|
.cu |
CUDA source file, containing host code and device functions |
.c |
C source file |
.cc, .cxx, .cpp
|
C++ source file |
.ptx |
PTX intermediate assembly file |
.cubin |
CUDA device code binary file (CUBIN) for a single GPU architecture |
.fatbin |
CUDA fat binary file that may contain multiple PTX and CUBIN files |
.o, .obj
|
Object file |
.a, .lib
|
Library file |
.res |
Resource file |
.so |
Shared object file |
NVCC 编译选项
| Phase | Long Name | Short Name | Default Output File Name |
|---|---|---|---|
| CUDA compilation to C/C++ source file | --cuda |
-cuda |
.cpp.ii appended to source file name, as in x.cu.cpp.ii. This output file can be compiled by the host compiler that was used by nvcc to preprocess the .cufile. |
| C/C++ preprocessing | --preprocess |
-E |
|
| C/C++ compilation to object file | --compile |
-c |
Source file name with suffix replaced by o on Linux and Mac OS X, or obj on Windows |
| Cubin generation from CUDA source files | --cubin |
-cubin |
Source file name with suffix replaced by cubin
|
| Cubin generation from PTX intermediate files. | --cubin |
-cubin |
Source file name with suffix replaced by cubin |
| PTX generation from CUDA source files | --ptx |
-ptx |
Source file name with suffix replaced by ptx
|
| Fatbinary generation from source, PTX or cubin files | --fatbin |
-fatbin |
Source file name with suffix replaced by fatbin |
| Linking relocatable device code. | --device-link |
-dlink |
a_dlink.obj on Windows or a_dlink.o on other platforms |
| Cubin generation from linked relocatable device code. | --device-link--cubin |
-dlink-cubin |
a_dlink.cubin |
| Fatbinary generation from linked relocatable device code | --device-link--fatbin |
-dlink-fatbin |
a_dlink.fatbin |
| Linking an executable |
|
a.exe on Windows or a.out on other platforms |
|
| Constructing an object file archive, or library | --lib |
-lib |
a.lib on Windows or a.a on other platforms |
| make dependency generation | --generate-dependencies |
-M |
|
| make dependency generation without headers in system paths. | --generate-nonsystem-dependencies |
-MM |
|
| Running an executable | --run |
-run |
### MVCC 命令选项;
NVCC 命令工具使用方法和参数解析详见nvcc --help;
#### 常用参数和功能如下:
| 全称 | 简写 | 作用 |
|---|---|---|
--output-file [file] |
-o [file] |
输出目标文件 |
--pre-include [file1,file2,...] |
-inlude [file1,file2,...] |
添加头文件 |
--library [library] |
-l [library] |
添加动态链接文件 |
--define-macro def,… |
-D |
Specify macro definitions for use during preprocessing or compilation. |
--undefine-macro def,… |
-U |
Undefine macro definitions during preprocessing or compilation. |
--include-path path,… |
-I |
Specify include search paths. |
--system-include path,… |
-isystem |
Specify system include search paths. |
--library-path path,… |
-L |
Specify library search paths (see Libraries). |
--output-directory directory |
-odir |
Specify the directory of the output file. This option is intended for letting the dependency generation step (see --generate-dependencies) generate a rule that defines the target object file in the proper directory. |
--compiler-bindir directory |
-ccbin |
Specify the directory in which the compiler executable resides. The host compiler executable name can be also specified to ensure that the correct host compiler is selected. In addition, driver prefix options (--input-drive-prefix, --dependency-drive-prefix, or --drive-prefix) may need to be specified, if nvcc is executed in a Cygwin shell or a MinGW shell on Windows. |
--cudart {none/shared/static} |
-cudart |
Specify the type of CUDA runtime library to be used: no CUDA runtime library, shared/dynamic CUDA runtime library, or static CUDA runtime library. Allowed values for this option: none, shared, static. Default value: static
|
--libdevice-directory directory |
-ldir |
Specify the directory that contains the libdevice library files when option --dont-use-profile is used. Libdevice library files are located in the nvvm/libdevice directory in the CUDA Toolkit. |
nvcc9.0 help信息如下
Usage : nvcc [options] <inputfile>
Options for specifying the compilation phase
============================================
More exactly, this option specifies up to which stage the input files must be compiled,
according to the following compilation trajectories for different input file types:
.c/.cc/.cpp/.cxx : preprocess, compile, link
.o : link
.i/.ii : compile, link
.cu : preprocess, cuda frontend, PTX assemble,
merge with host C code, compile, link
.gpu : cicc compile into cubin
.ptx : PTX assemble into cubin.
--cuda (-cuda)
Compile all .cu input files to .cu.cpp.ii output.
--cubin (-cubin)
Compile all .cu/.gpu/.ptx input files to device-only .cubin files. This
step discards the host code for each .cu input file.
--fatbin(-fatbin)
Compile all .cu/.gpu/.ptx/.cubin input files to device-only .fatbin files.
This step discards the host code for each .cu input file.
--ptx (-ptx)
Compile all .cu/.gpu input files to device-only .ptx files. This step discards
the host code for each of these input file.
--preprocess (-E)
Preprocess all .c/.cc/.cpp/.cxx/.cu input files.
--generate-dependencies (-M)
Generate a dependency file that can be included in a make file for the .c/.cc/.cpp/.cxx/.cu
input file (more than one are not allowed in this mode).
--compile (-c)
Compile each .c/.cc/.cpp/.cxx/.cu input file into an object file.
--device-c (-dc)
Compile each .c/.cc/.cpp/.cxx/.cu input file into an object file that contains
relocatable device code. It is equivalent to '--relocatable-device-code=true
--compile'.
--device-w (-dw)
Compile each .c/.cc/.cpp/.cxx/.cu input file into an object file that contains
executable device code. It is equivalent to '--relocatable-device-code=false
--compile'.
--device-link (-dlink)
Link object files with relocatable device code and .ptx/.cubin/.fatbin files
into an object file with executable device code, which can be passed to the
host linker.
--link (-link)
This option specifies the default behavior: compile and link all inputs.
--lib (-lib)
Compile all inputs into object files (if necessary) and add the results to
the specified output library file.
--run (-run)
This option compiles and links all inputs into an executable, and executes
it. Or, when the input is a single executable, it is executed without any
compilation or linking. This step is intended for developers who do not want
to be bothered with setting the necessary environment variables; these are
set temporarily by nvcc).
File and path specifications.
=============================
--output-file <file> (-o)
Specify name and location of the output file. Only a single input file is
allowed when this option is present in nvcc non-linking/archiving mode.
--pre-include <file>,... (-include)
Specify header files that must be preincluded during preprocessing.
--library <library>,... (-l)
Specify libraries to be used in the linking stage without the library file
extension. The libraries are searched for on the library search paths that
have been specified using option '--library-path'.
--define-macro <def>,... (-D)
Specify macro definitions to define for use during preprocessing or compilation.
--undefine-macro <def>,... (-U)
Undefine macro definitions during preprocessing or compilation.
--include-path <path>,... (-I)
Specify include search paths.
--system-include <path>,... (-isystem)
Specify system include search paths.
--library-path <path>,... (-L)
Specify library search paths.
--output-directory <directory> (-odir)
Specify the directory of the output file. This option is intended for letting
the dependency generation step (see '--generate-dependencies') generate a
rule that defines the target object file in the proper directory.
--compiler-bindir <path> (-ccbin)
Specify the directory in which the host compiler executable resides. The
host compiler executable name can be also specified to ensure that the correct
host compiler is selected. In addition, driver prefix options ('--input-drive-prefix',
'--dependency-drive-prefix', or '--drive-prefix') may need to be specified,
if nvcc is executed in a Cygwin shell or a MinGW shell on Windows.
--cudart{none|shared|static} (-cudart)
Specify the type of CUDA runtime library to be used: no CUDA runtime library,
shared/dynamic CUDA runtime library, or static CUDA runtime library.
Allowed values for this option: 'none','shared','static'.
Default value: 'static'.
--libdevice-directory <directory> (-ldir)
Specify the directory that contains the libdevice library files when option
'--dont-use-profile' is used. Libdevice library files are located in the
'nvvm/libdevice' directory in the CUDA toolkit.
--cl-version <cl-version-number> --cl-version <cl-version-number>
Specify the version of Microsoft Visual Studio installation. Note: this
option is to be used in conjunction with '--use-local-env', and is ignored
when '--use-local-env' is not specified. Support for VS2010 and earlier has
been deprecated.
Allowed values for this option: 2010,2012,2013,2015,2017.
--use-local-env --use-local-env
Specify whether the environment is already set up for the host compiler.
Options for specifying behavior of compiler/linker.
===================================================
--profile (-pg)
Instrument generated code/executable for use by gprof (Linux only).
--debug (-g)
Generate debug information for host code.
--device-debug (-G)
Generate debug information for device code. Turns off all optimizations.
Don not use for profiling; use -lineinfo instead.
--generate-line-info (-lineinfo)
Generate line-number information for device code.
--optimize <level> (-O)
Specify optimization level for host code.
--ftemplate-backtrace-limit <limit> (-ftemplate-backtrace-limit)
Set the maximum number of template instantiation notes for a single warning
or error to <limit>. A value of 0 is allowed, and indicates that no limit
should be enforced. This value is also passed to the host compiler if it
provides an equivalent flag.
--ftemplate-depth <limit> (-ftemplate-depth)
Set the maximum instantiation depth for template classes to <limit>. This
value is also passed to the host compiler if it provides an equivalent flag.
--shared(-shared)
Generate a shared library during linking. Use option '--linker-options'
when other linker options are required for more control.
--x {c|c++|cu} (-x)
Explicitly specify the language for the input files, rather than letting
the compiler choose a default based on the file name suffix.
Allowed values for this option: 'c','c++','cu'.
--std {c++03|c++11|c++14} (-std)
Select a particular C++ dialect. Note that this flag also turns on the corresponding
dialect flag for the host compiler.
Allowed values for this option: 'c++03','c++11','c++14'.
--no-host-device-initializer-list (-nohdinitlist)
Do not implicitly consider member functions of std::initializer_list as __host__
__device__ functions.
--no-host-device-move-forward (-nohdmoveforward)
Do not implicitly consider std::move and std::forward as __host__ __device__
function templates.
--expt-relaxed-constexpr (-expt-relaxed-constexpr)
Experimental flag: Allow host code to invoke __device__ constexpr functions,
and device code to invoke __host__ constexpr functions.
--expt-extended-lambda (-expt-extended-lambda)
Experimental flag: Allow __host__, __device__ annotations in lambda declaration.
--machine {32|64} (-m)
Specify 32 vs 64 bit architecture.
Allowed values for this option: 32,64.
Default value: 64.
Options for passing specific phase options
==========================================
These allow for passing options directly to the intended compilation phase. Using
these, users have the ability to pass options to the lower level compilation tools,
without the need for nvcc to know about each and every such option.
--compiler-options <options>,... (-Xcompiler)
Specify options directly to the compiler/preprocessor.
--linker-options <options>,... (-Xlinker)
Specify options directly to the host linker.
--archive-options <options>,... (-Xarchive)
Specify options directly to library manager.
--ptxas-options <options>,... (-Xptxas)
Specify options directly to ptxas, the PTX optimizing assembler.
--nvlink-options <options>,... (-Xnvlink)
Specify options directly to nvlink.
Miscellaneous options for guiding the compiler driver.
======================================================
--dont-use-profile (-noprof)
Nvcc uses the nvcc.profiles file for compilation. When specifying this option,
the profile file is not used.
--dryrun(-dryrun)
Do not execute the compilation commands generated by nvcc. Instead, list
them.
--verbose (-v)
List the compilation commands generated by this compiler driver, but do not
suppress their execution.
--keep (-keep)
Keep all intermediate files that are generated during internal compilation
steps.
--keep-dir <directory> (-keep-dir)
Keep all intermediate files that are generated during internal compilation
steps in this directory.
--save-temps (-save-temps)
This option is an alias of '--keep'.
--clean-targets (-clean)
This option reverses the behavior of nvcc. When specified, none of the compilation
phases will be executed. Instead, all of the non-temporary files that nvcc
would otherwise create will be deleted.
--run-args <arguments>,... (-run-args)
Used in combination with option --run to specify command line arguments for
the executable.
--input-drive-prefix <prefix> (-idp)
On Windows, all command line arguments that refer to file names must be converted
to the Windows native format before they are passed to pure Windows executables.
This option specifies how the current development environment represents
absolute paths. Use '/cygwin/' as <prefix> for Cygwin build environments,
and '/' as <prefix> for MinGW.
--dependency-drive-prefix <prefix> (-ddp)
On Windows, when generating dependency files (see --generate-dependencies),
all file names must be converted appropriately for the instance of 'make'
that is used. Some instances of 'make' have trouble with the colon in absolute
paths in the native Windows format, which depends on the environment in which
the 'make' instance has been compiled. Use '/cygwin/' as <prefix> for a
Cygwin make, and '/' as <prefix> for MinGW. Or leave these file names in
the native Windows format by specifying nothing.
--drive-prefix <prefix> (-dp)
Specifies <prefix> as both --input-drive-prefix and --dependency-drive-prefix.
--dependency-target-name <target> (-MT)
Specify the target name of the generated rule when generating a dependency
file (see '--generate-dependencies').
--no-align-double --no-align-double
Specifies that '-malign-double' should not be passed as a compiler argument
on 32-bit platforms. WARNING: this makes the ABI incompatible with the cuda’s
kernel ABI for certain 64-bit types.
--no-device-link (-nodlink)
Skip the device link step when linking object files.
Options for steering GPU code generation.
=========================================
--gpu-architecture <arch> (-arch)
Specify the name of the class of NVIDIA 'virtual' GPU architecture for which
the CUDA input files must be compiled.
With the exception as described for the shorthand below, the architecture
specified with this option must be a 'virtual' architecture (such as compute_50).
Normally, this option alone does not trigger assembly of the generated PTX
for a 'real' architecture (that is the role of nvcc option '--gpu-code',
see below); rather, its purpose is to control preprocessing and compilation
of the input to PTX.
For convenience, in case of simple nvcc compilations, the following shorthand
is supported. If no value for option '--gpu-code' is specified, then the
value of this option defaults to the value of '--gpu-architecture'. In this
situation, as only exception to the description above, the value specified
for '--gpu-architecture' may be a 'real' architecture (such as a sm_50),
in which case nvcc uses the specified 'real' architecture and its closest
'virtual' architecture as effective architecture values. For example, 'nvcc
--gpu-architecture=sm_50' is equivalent to 'nvcc --gpu-architecture=compute_50
--gpu-code=sm_50,compute_50'.
Allowed values for this option: 'compute_30','compute_32','compute_35',
'compute_37','compute_50','compute_52','compute_53','compute_60','compute_61',
'compute_62','compute_70','sm_30','sm_32','sm_35','sm_37','sm_50','sm_52',
'sm_53','sm_60','sm_61','sm_62','sm_70'.
--gpu-code <code>,... (-code)
Specify the name of the NVIDIA GPU to assemble and optimize PTX for.
nvcc embeds a compiled code image in the resulting executable for each specified
<code> architecture, which is a true binary load image for each 'real' architecture
(such as sm_50), and PTX code for the 'virtual' architecture (such as compute_50).
During runtime, such embedded PTX code is dynamically compiled by the CUDA
runtime system if no binary load image is found for the 'current' GPU.
Architectures specified for options '--gpu-architecture' and '--gpu-code'
may be 'virtual' as well as 'real', but the <code> architectures must be
compatible with the <arch> architecture. When the '--gpu-code' option is
used, the value for the '--gpu-architecture' option must be a 'virtual' PTX
architecture.
For instance, '--gpu-architecture=compute_35' is not compatible with '--gpu-code=sm_30',
because the earlier compilation stages will assume the availability of 'compute_35'
features that are not present on 'sm_30'.
Allowed values for this option: 'compute_30','compute_32','compute_35',
'compute_37','compute_50','compute_52','compute_53','compute_60','compute_61',
'compute_62','compute_70','sm_30','sm_32','sm_35','sm_37','sm_50','sm_52',
'sm_53','sm_60','sm_61','sm_62','sm_70'.
--generate-code <specification>,... (-gencode)
This option provides a generalization of the '--gpu-architecture=<arch> --gpu-code=<code>,
...' option combination for specifying nvcc behavior with respect to code
generation. Where use of the previous options generates code for different
'real' architectures with the PTX for the same 'virtual' architecture, option
'--generate-code' allows multiple PTX generations for different 'virtual'
architectures. In fact, '--gpu-architecture=<arch> --gpu-code=<code>,
...' is equivalent to '--generate-code arch=<arch>,code=<code>,...'.
'--generate-code' options may be repeated for different virtual architectures.
Allowed keywords for this option: 'arch','code'.
--relocatable-device-code {true|false} (-rdc)
Enable (disable) the generation of relocatable device code. If disabled,
executable device code is generated. Relocatable device code must be linked
before it can be executed.
Default value: false.
--entries entry,... (-e)
Specify the global entry functions for which code must be generated. By
default, code will be generated for all entry functions.
--maxrregcount <amount> (-maxrregcount)
Specify the maximum amount of registers that GPU functions can use.
Until a function-specific limit, a higher value will generally increase the
performance of individual GPU threads that execute this function. However,
because thread registers are allocated from a global register pool on each
GPU, a higher value of this option will also reduce the maximum thread block
size, thereby reducing the amount of thread parallelism. Hence, a good maxrregcount
value is the result of a trade-off.
If this option is not specified, then no maximum is assumed.
Value less than the minimum registers required by ABI will be bumped up by
the compiler to ABI minimum limit.
User program may not be able to make use of all registers as some registers
are reserved by compiler.
--use_fast_math (-use_fast_math)
Make use of fast math library. '--use_fast_math' implies '--ftz=true --prec-div=false
--prec-sqrt=false --fmad=true'.
--ftz {true|false} (-ftz)
This option controls single-precision denormals support. '--ftz=true' flushes
denormal values to zero and '--ftz=false' preserves denormal values. '--use_fast_math'
implies '--ftz=true'.
Default value: false.
--prec-div {true|false} (-prec-div)
This option controls single-precision floating-point division and reciprocals.
'--prec-div=true' enables the IEEE round-to-nearest mode and '--prec-div=false'
enables the fast approximation mode. '--use_fast_math' implies '--prec-div=false'.
Default value: true.
--prec-sqrt {true|false} (-prec-sqrt)
This option controls single-precision floating-point squre root. '--prec-sqrt=true'
enables the IEEE round-to-nearest mode and '--prec-sqrt=false' enables the
fast approximation mode. '--use_fast_math' implies '--prec-sqrt=false'.
Default value: true.
--fmad {true|false} (-fmad)
This option enables (disables) the contraction of floating-point multiplies
and adds/subtracts into floating-point multiply-add operations (FMAD, FFMA,
or DFMA). '--use_fast_math' implies '--fmad=true'.
Default value: true.
Options for steering cuda compilation.
======================================
--default-stream {legacy|null|per-thread} (-default-stream)
Specify the stream that CUDA commands from the compiled program will be sent
to by default.
legacy
The CUDA legacy stream (per context, implicitly synchronizes with
other streams).
per-thread
A normal CUDA stream (per thread, does not implicitly
synchronize with other streams).
'null' is a deprecated alias for 'legacy'.
Allowed values for this option: 'legacy','null','per-thread'.
Default value: 'legacy'.
Generic tool options.
=====================
--disable-warnings (-w)
Inhibit all warning messages.
--keep-device-functions (-keep-device-functions)
In whole program compilation mode, preserve user defined external linkage
__device__ function definitions up to PTX.
--source-in-ptx (-src-in-ptx)
Interleave source in PTX. May only be used in conjunction with --device-debug
or --generate-line-info.
--restrict (-restrict)
Programmer assertion that all kernel pointer parameters are restrict pointers.
--Wreorder (-Wreorder)
Generate warnings when member initializers are reordered.
--Wno-deprecated-declarations (-Wno-deprecated-declarations)
Suppress warning on use of deprecated entity.
--Wno-deprecated-gpu-targets (-Wno-deprecated-gpu-targets)
Suppress warnings about deprecated GPU target architectures.
--Werror<kind>,... (-Werror)
Make warnings of the specified kinds into errors. The following is the list
of warning kinds accepted by this option:
cross-execution-space-call
Be more strict about unsupported cross execution space calls.
The compiler will generate an error instead of a warning for a
call from a __host__ __device__ to a __host__ function.
reorder
Generate errors when member initializers are reordered.
deprecated-declarations
Generate error on use of a deprecated entity.
Allowed values for this option: 'cross-execution-space-call','deprecated-declarations',
'reorder'.
--resource-usage (-res-usage)
Show resource usage such as registers and memory of the GPU code.
This option implies '--nvlink-options --verbose' when '--relocatable-device-code=true'
is set. Otherwise, it implies '--ptxas-options --verbose'.
--help (-h)
Print this help information on this tool.
--version (-V)
Print version information on this tool.
--options-file <file>,... (-optf)
Include command line options from specified file.
实例演示和分析
下面是一个 简单的实例运行情况,test.cu
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 256>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
注意:因为cuda安装和软件限制,有时需要使用root权限才能正常使用nvprof进行分析,否则可能提示内存无法访问
接下来使用 --dryrun 可以打印全编译过程而不执行。为了方便理清情况使用--cuda只进行预处理工作
nvcc test.cu -o add_cuda --cuda -keep --dryrun
输出日志如下:
#nvcc编译器中自定义的环境变量
#$ _SPACE_=
#$ _CUDART_=cudart
#$ _HERE_=/usr/local/cuda/bin
#$ _THERE_=/usr/local/cuda/bin
#$ _TARGET_SIZE_=
#$ _TARGET_DIR_=
#$ _TARGET_SIZE_=64
#$ TOP=/usr/local/cuda/bin/..
#$ NVVMIR_LIBRARY_DIR=/usr/local/cuda/bin/../nvvm/libdevice
#预定义的LD_LIBRARY_PATH环境变量后面已经省略
#$ LD_LIBRARY_PATH=/usr/local/cuda/bin/ ...
#PATH环境变量后面已经省略
#$ PATH=/usr/local/cuda/bin/../open64/bin:/usr/local/cuda/bin/../nvvm/bin:/usr/local/cuda/bin: ...
#$ INCLUDES="-I/usr/local/cuda/bin/..//include"
#$ LIBRARIES= "-L/usr/local/cuda/bin/..//lib64/stubs" "-L/usr/local/cuda/bin/..//lib64"
#$ CUDAFE_FLAGS=
#$ PTXAS_FLAGS=
#开始进行预处理将test.cu转变为.cpp1.ii和.cpp4.ii
#gcc预处理为test.cpp1.ii
#$ gcc -D__CUDA_ARCH__=300 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -include "cuda_runtime.h" -m64 "test.cu" > "test.cpp1.ii"
#nvcc中的cicc(nvopencc)将 test.cpp1.ii转化为test.ptx 并生成一份附属的test.cudafe1.stub.c
#$ cicc --gnu_version=50400 --allow_managed -arch compute_30 -m64 -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "test.fatbin.c" -tused -nvvmir-library "/usr/local/cuda/bin/../nvvm/libdevice/libdevice.10.bc" --gen_module_id_file --module_id_file_name "test.module_id" --orig_src_file_name "test.cu" --gen_c_file_name "test.cudafe1.c" --stub_file_name "test.cudafe1.stub.c" --gen_device_file_name "test.cudafe1.gpu" "test.cpp1.ii" -o "test.ptx"
#使用ptxas 以sm_30虚拟架构开始将test.ptx 转化为test.sm_30.cubin 注意当存在多种虚拟架构时,会重复进行上述2个步骤。
#$ ptxas -arch=sm_30 -m64 "test.ptx" -o "test.sm_30.cubin"
# 使用fatbinary将test.sm_30.cubin和test.ptx转换为test.fatbin.c;
#$ fatbinary --create="test.fatbin" -64 "--image=profile=sm_30,file=test.sm_30.cubin" "--image=profile=compute_30,file=test.ptx" --embedded-fatbin="test.fatbin.c" --cuda
#使用gcc将host的代码分离出来形成test.cpp4.ii
#$ gcc -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -include "cuda_runtime.h" -m64 "test.cu" > "test.cpp4.ii"
#使用cudafe++ 将test.cpp4.ii和test.cudafe1.stub.c转换为test.cudafe1.cpp文件
#$ cudafe++ --gnu_version=50400 --allow_managed --m64 --parse_templates --gen_c_file_name "test.cudafe1.cpp" --stub_file_name "test.cudafe1.stub.c" --module_id_file_name "test.module_id" "test.cpp4.ii"
#使用gcc预处理test.cudafe1.cpp 将结果转换为我们的目标 "add_cuda"
#$ gcc -E -x c++ -D__CUDA_FTZ=0 -D__CUDA_PREC_DIV=1 -D__CUDA_PREC_SQRT=1 "-I/usr/local/cuda/bin/..//include" -m64 "test.cudafe1.cpp" > "add_cuda"
上面可以较为清晰的看到nvcc中文件分离和预处理的过程。
gcc分离出.cpp1.ii -> cicc为.cpp1.ii添加信息成为test.ptx -> ptxas将其转换为对应的.cubin -> fatbinary将.ptx和.cubin合成为.fatbin.c -> 与gcc生成的.cudafe1.cpp一起进行合成生成最终的add_cuda。
下面来看一下编译与链接的过程:
nvcc test.cu -o add_cuda -keep --dryrun这样来查看生成的整个过程。
#预定义变量
#$ _SPACE_=
#$ _CUDART_=cudart
#$ _HERE_=/usr/local/cuda/bin
#$ _THERE_=/usr/local/cuda/bin
#$ _TARGET_SIZE_=
#$ _TARGET_DIR_=
#$ _TARGET_SIZE_=64
#$ TOP=/usr/local/cuda/bin/..
#$ NVVMIR_LIBRARY_DIR=/usr/local/cuda/bin/../nvvm/libdevice
#$ LD_LIBRARY_PATH=/usr/local/cuda/bin/../lib ...
#$ PATH=/usr/local/cuda/bin/../open64/bin:/usr/local/cuda/bin/../nvvm/bin: ...
#$ INCLUDES="-I/usr/local/cuda/bin/..//include"
#$ LIBRARIES= "-L/usr/local/cuda/bin/..//lib64/stubs" "-L/usr/local/cuda/bin/..//lib64"
#$ CUDAFE_FLAGS=
#$ PTXAS_FLAGS=
# 移除add_cuda_dlink.reg.c
#$ rm add_cuda_dlink.reg.c
#生成test.cpp1.ii
#$ gcc -D__CUDA_ARCH__=300 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -include "cuda_runtime.h" -m64 "test.cu" > "test.cpp1.ii"
#生成test.ptx和test.cudafe1.stub.c
#$ cicc --gnu_version=50400 --allow_managed -arch compute_30 -m64 -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "test.fatbin.c" -tused -nvvmir-library "/usr/local/cuda/bin/../nvvm/libdevice/libdevice.10.bc" --gen_module_id_file --module_id_file_name "test.module_id" --orig_src_file_name "test.cu" --gen_c_file_name "test.cudafe1.c" --stub_file_name "test.cudafe1.stub.c" --gen_device_file_name "test.cudafe1.gpu" "test.cpp1.ii" -o "test.ptx"
#将test.ptx转化为 test.sm_30.cubin
#$ ptxas -arch=sm_30 -m64 "test.ptx" -o "test.sm_30.cubin"
#创建对应的fatbin
#$ fatbinary --create="test.fatbin" -64 "--image=profile=sm_30,file=test.sm_30.cubin" "--image=profile=compute_30,file=test.ptx" --embedded-fatbin="test.fatbin.c" --cuda
#另外一个分支,创建test.cpp4.ii
#$ gcc -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -include "cuda_runtime.h" -m64 "test.cu" > "test.cpp4.ii"
#使用cudafe++用test.cudafe1.stub.创建test.o和test.cudafe1.cpp
#$ cudafe++ --gnu_version=50400 --allow_managed --m64 --parse_templates --gen_c_file_name "test.cudafe1.cpp" --stub_file_name "test.cudafe1.stub.c" --module_id_file_name "test.module_id" "test.cpp4.ii"
#$ gcc -D__CUDA_ARCH__=300 -c -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS "-I/usr/local/cuda/bin/..//include" -m64 -o "test.o" "test.cudafe1.cpp"
#将test.o进行链接,成为目标add_cuda_dlink.sm_30.cubin同时生成链接辅助二文件add_cuda_dlink.reg.c
#$ nvlink --arch=sm_30 --register-link-binaries="add_cuda_dlink.reg.c" -m64 "-L/usr/local/cuda/bin/..//lib64/stubs" "-L/usr/local/cuda/bin/..//lib64" -cpu-arch=X86_64 "test.o" -o "add_cuda_dlink.sm_30.cubin"
# 将add_cuda_dlink.sm_30.cubin用fatbinaty转换为add_cuda_dlink.fatbin.c
#$ fatbinary --create="add_cuda_dlink.fatbin" -64 -link "--image=profile=sm_30,file=add_cuda_dlink.sm_30.cubin" --embedded-fatbin="add_cuda_dlink.fatbin.c"
# 使用gcc将add_cuda_dlink.reg.c、add_cuda_dlink.fatbin.c 转换为add_cuda_dlink.o
#$ gcc -c -x c++ -DFATBINFILE="\"add_cuda_dlink.fatbin.c\"" -DREGISTERLINKBINARYFILE="\"add_cuda_dlink.reg.c\"" -I. "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -m64 -o "add_cuda_dlink.o" "/usr/local/cuda/bin/crt/link.stub"
#最后使用gcc进行链接
#$ g++ -m64 -o "add_cuda" -Wl,--start-group "add_cuda_dlink.o" "test.o" "-L/usr/local/cuda/bin/..//lib64/stubs" "-L/usr/local/cuda/bin/..//lib64" -lcudadevrt -lcudart_static -lrt -lpthread -ldl -Wl,--end-group
接下来让我使用shell脚本来按照上面执行看一下效果和文件变化。
1. gcc生成test.cpp1.ii
gcc -D__CUDA_ARCH__=300 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -include "cuda_runtime.h" -m64 "test.cu" > "test.cpp1.ii"
生成文件test.cpp1.ii内容如下:
## test.cpp1.ii 主要是头文件的链接信息
# 1 "test.cu"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "/usr/local/cuda/bin/..//include/cuda_runtime.h" 1
# 56 "/usr/local/cuda/bin/..//include/cuda_runtime.h"
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "-Wunused-function"
# 78 "/usr/local/cuda/bin/..//include/cuda_runtime.h"
# 1 "/usr/local/cuda/bin/..//include/host_config.h" 1
# 50 "/usr/local/cuda/bin/..//include/host_config.h"
# 1 "/usr/local/cuda/bin/..//include/crt/host_config.h" 1
# 179 "/usr/local/cuda/bin/..//include/crt/host_config.h"
# 1 "/usr/include/features.h" 1 3 4
# 367 "/usr/include/features.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 1 3 4
# 410 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/wordsize.h" 1 3 4
# 411 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 2 3 4
# 368 "/usr/include/features.h" 2 3 4
# 391 "/usr/include/features.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 1 3 4
# 10 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 3 4
# 1 "/usr/include/x86_64-linux-gnu/gnu/stubs-64.h" 1 3 4
# 11 "/usr/include/x86_64-linux-gnu/gnu/stubs.h" 2 3 4
# 392 "/usr/include/features.h" 2 3 4
# 180 "/usr/local/cuda/bin/..//include/crt/host_config.h" 2
# 50 "/usr/local/cuda/bin/..//include/host_config.h" 2
# 79 "/usr/local/cuda/bin/..//include/cuda_runtime.h" 2
# 1 "/usr/local/cuda/bin/..//include/builtin_types.h" 1
# 56 "/usr/local/cuda/bin/..//include/builtin_types.h"
# 1 "/usr/local/cuda/bin/..//include/device_types.h" 1
# 53 "/usr/local/cuda/bin/..//include/device_types.h"
# 1 "/usr/local/cuda/bin/..//include/host_defines.h" 1
# 50 "/usr/local/cuda/bin/..//include/host_defines.h"
# 1 "/usr/local/cuda/bin/..//include/crt/host_defines.h" 1
# 50 "/usr/local/cuda/bin/..//include/host_defines.h" 2
# 54 "/usr/local/cuda/bin/..//include/device_types.h" 2
这里主要是将.cu中使用的头文件罗列出来,方便后面进行对应的查找。
2. cicc生成对应汇编代码
cicc --gnu_version=50400 --allow_managed -arch compute_30 -m64 ....
者一步主要由test.cu是生成对应的.ptx文件,但是实际生成了test.cudafe1.c、test.cudafe1.gpu、test.cudafe1.stub.c、test.module_id、test.ptx六个文件。下面是每个文件对应的内容:
test.cudafe1.c
## test.cudafe1.c
# 1 "test.cu"
# 61 "/usr/include/c++/5/iostream" 3
extern _ZSt7ostream _ZSt4cout __attribute__((visibility("default")));
# 74 "/usr/include/c++/5/iostream" 3
static struct _ZNSt8ios_base4InitE _ZSt8__ioinit __attribute__((visibility("default"))) = {};
extern void *__dso_handle __attribute__((visibility("hidden")));
全局静态结构体的东西和gcc生成的比较类似
test.cudafe1.gpu
typedef char __nv_bool;
# 1563 "/usr/local/cuda/bin/..//include/driver_types.h"
struct CUstream_st;
# 27 "/usr/include/xlocale.h" 3
struct __locale_struct;
# 233 "/usr/include/c++/5/bits/char_traits.h" 3
struct _ZSt11char_traitsIcE;
# 371 "/usr/include/c++/5/bits/locale_classes.h" 3
struct _ZNSt6locale5facetE;
# 371 "/usr/include/c++/5/bits/locale_classes.h" 3
struct __SO__NSt6locale5facetE;
# 513 "/usr/include/c++/5/bits/locale_classes.h" 3
struct _ZNSt6locale5_ImplE;
# 62 "/usr/include/c++/5/bits/locale_classes.h" 3
struct _ZSt6locale;
# 57 "/usr/include/c++/5/bits/ios_base.h" 3
enum _ZSt13_Ios_Fmtflags {
# 59 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt12_S_boolalpha = 1,
# 60 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_dec,
# 61 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt8_S_fixed = 4,
# 62 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_hex = 8,
# 63 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt11_S_internal = 16,
# 64 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt7_S_left = 32,
# 65 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_oct = 64,
# 66 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt8_S_right = 128,
# 67 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt13_S_scientific = 256,
# 68 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt11_S_showbase = 512,
# 69 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt12_S_showpoint = 1024,
# 70 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt10_S_showpos = 2048,
# 71 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt9_S_skipws = 4096,
# 72 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt10_S_unitbuf = 8192,
# 73 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt12_S_uppercase = 16384,
# 74 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt14_S_adjustfield = 176,
# 75 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt12_S_basefield = 74,
# 76 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt13_S_floatfield = 260,
# 77 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt19_S_ios_fmtflags_end = 65536,
# 78 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt19_S_ios_fmtflags_max = 2147483647,
# 79 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt19_S_ios_fmtflags_min = (-2147483647-1)};
# 111 "/usr/include/c++/5/bits/ios_base.h" 3
enum _ZSt13_Ios_Openmode {
# 113 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_app = 1,
# 114 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_ate,
# 115 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_bin = 4,
# 116 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt5_S_in = 8,
# 117 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_out = 16,
# 118 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt8_S_trunc = 32,
# 119 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt19_S_ios_openmode_end = 65536,
# 120 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt19_S_ios_openmode_max = 2147483647,
# 121 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt19_S_ios_openmode_min = (-2147483647-1)};
# 153 "/usr/include/c++/5/bits/ios_base.h" 3
enum _ZSt12_Ios_Iostate {
# 155 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt10_S_goodbit,
# 156 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt9_S_badbit,
# 157 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt9_S_eofbit,
# 158 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt10_S_failbit = 4,
# 159 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt18_S_ios_iostate_end = 65536,
# 160 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt18_S_ios_iostate_max = 2147483647,
# 161 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt18_S_ios_iostate_min = (-2147483647-1)};
# 193 "/usr/include/c++/5/bits/ios_base.h" 3
enum _ZSt12_Ios_Seekdir {
# 195 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_beg,
# 196 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_cur,
# 197 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt6_S_end,
# 198 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt18_S_ios_seekdir_end = 65536};
# 528 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base14_Callback_listE;
# 567 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base6_WordsE;
# 579 "/usr/include/c++/5/bits/ios_base.h" 3
enum _ZNSt8ios_baseUt_E {
# 579 "/usr/include/c++/5/bits/ios_base.h" 3
_ZNSt8ios_base18_S_local_word_sizeE = 8};
# 601 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base4InitE;
# 228 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZSt8ios_base;
# 125 "/usr/include/c++/5/iosfwd" 3
struct _ZSt19istreambuf_iteratorIcSt11char_traitsIcEE;
# 128 "/usr/include/c++/5/iosfwd" 3
struct _ZSt19ostreambuf_iteratorIcSt11char_traitsIcEE;
# 80 "/usr/include/c++/5/iosfwd" 3
struct _ZSt15basic_streambufIcSt11char_traitsIcEE;
# 41 "/usr/include/x86_64-linux-gnu/c++/5/bits/ctype_base.h" 3
struct _ZSt10ctype_base;
# 681 "/usr/include/c++/5/bits/locale_facets.h" 3
struct _ZSt5ctypeIcE;
# 1547 "/usr/include/c++/5/bits/locale_facets.h" 3
enum _ZNSt10__num_baseUt_E {
# 1548 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base9_S_ominusE,
# 1549 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base8_S_oplusE,
# 1550 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_oxE,
# 1551 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_oXE,
# 1552 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base10_S_odigitsE,
# 1553 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base14_S_odigits_endE = 20,
# 1554 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base11_S_oudigitsE = 20,
# 1555 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base15_S_oudigits_endE = 36,
# 1556 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_oeE = 18,
# 1557 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_oEE = 34,
# 1558 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base7_S_oendE = 36};
# 1573 "/usr/include/c++/5/bits/locale_facets.h" 3
enum _ZNSt10__num_baseUt0_E {
# 1574 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base9_S_iminusE,
# 1575 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base8_S_iplusE,
# 1576 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_ixE,
# 1577 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_iXE,
# 1578 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base8_S_izeroE,
# 1579 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_ieE = 18,
# 1580 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base5_S_iEE = 24,
# 1581 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10__num_base7_S_iendE = 26};
# 1948 "/usr/include/c++/5/bits/locale_facets.h" 3
struct _ZSt7num_getIcSt19istreambuf_iteratorIcSt11char_traitsIcEEE;
# 2289 "/usr/include/c++/5/bits/locale_facets.h" 3
struct _ZSt7num_putIcSt19ostreambuf_iteratorIcSt11char_traitsIcEEE;
# 77 "/usr/include/c++/5/iosfwd" 3
struct _ZSt9basic_iosIcSt11char_traitsIcEE;
# 86 "/usr/include/c++/5/iosfwd" 3
struct _ZSo;
# 216 "/usr/lib/gcc/x86_64-linux-gnu/5/include/stddef.h" 3
typedef unsigned long size_t;
#include "crt/device_runtime.h"
# 39 "/usr/include/xlocale.h" 3
typedef struct __locale_struct *__locale_t;
# 32 "/usr/include/x86_64-linux-gnu/c++/5/bits/atomic_word.h" 3
typedef int _Atomic_word;
# 197 "/usr/include/x86_64-linux-gnu/c++/5/bits/c++config.h" 3
typedef long _ZSt9ptrdiff_t;
# 98 "/usr/include/c++/5/bits/postypes.h" 3
typedef _ZSt9ptrdiff_t _ZSt10streamsize;
# 141 "/usr/include/c++/5/iosfwd" 3
typedef struct _ZSo _ZSt7ostream;
# 62 "/usr/include/x86_64-linux-gnu/c++/5/bits/c++locale.h" 3
typedef __locale_t _ZSt10__c_locale;
# 371 "/usr/include/c++/5/bits/locale_classes.h" 3
struct _ZNSt6locale5facetE { const long *__vptr;
# 377 "/usr/include/c++/5/bits/locale_classes.h" 3
_Atomic_word _M_refcount;char __nv_no_debug_dummy_end_padding_0[4];};
# 371 "/usr/include/c++/5/bits/locale_classes.h" 3
struct __SO__NSt6locale5facetE { const long *__vptr;
# 377 "/usr/include/c++/5/bits/locale_classes.h" 3
_Atomic_word _M_refcount;};
# 62 "/usr/include/c++/5/bits/locale_classes.h" 3
struct _ZSt6locale {
# 309 "/usr/include/c++/5/bits/locale_classes.h" 3
struct _ZNSt6locale5_ImplE *_M_impl;};
# 323 "/usr/include/c++/5/bits/ios_base.h" 3
typedef enum _ZSt13_Ios_Fmtflags _ZNSt8ios_base8fmtflagsE;
# 398 "/usr/include/c++/5/bits/ios_base.h" 3
typedef enum _ZSt12_Ios_Iostate _ZNSt8ios_base7iostateE;
# 461 "/usr/include/c++/5/bits/ios_base.h" 3
typedef enum _ZSt12_Ios_Seekdir _ZNSt8ios_base7seekdirE;
# 567 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base6_WordsE {
# 569 "/usr/include/c++/5/bits/ios_base.h" 3
void *_M_pword;
# 570 "/usr/include/c++/5/bits/ios_base.h" 3
long _M_iword;};
# 601 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base4InitE {};
# 228 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZSt8ios_base { const long *__vptr;
# 520 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt10streamsize _M_precision;
# 521 "/usr/include/c++/5/bits/ios_base.h" 3
_ZSt10streamsize _M_width;
# 522 "/usr/include/c++/5/bits/ios_base.h" 3
_ZNSt8ios_base8fmtflagsE _M_flags;
# 523 "/usr/include/c++/5/bits/ios_base.h" 3
_ZNSt8ios_base7iostateE _M_exception;
# 524 "/usr/include/c++/5/bits/ios_base.h" 3
_ZNSt8ios_base7iostateE _M_streambuf_state;
# 558 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base14_Callback_listE *_M_callbacks;
# 575 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base6_WordsE _M_word_zero;
# 580 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base6_WordsE _M_local_word[8];
# 583 "/usr/include/c++/5/bits/ios_base.h" 3
int _M_word_size;
# 584 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZNSt8ios_base6_WordsE *_M_word;
# 590 "/usr/include/c++/5/bits/ios_base.h" 3
struct _ZSt6locale _M_ios_locale;};
# 129 "/usr/include/c++/5/streambuf" 3
typedef char _ZNSt15basic_streambufIcSt11char_traitsIcEE9char_typeE;
# 130 "/usr/include/c++/5/streambuf" 3
typedef struct _ZSt11char_traitsIcE _ZNSt15basic_streambufIcSt11char_traitsIcEE11traits_typeE;
# 80 "/usr/include/c++/5/iosfwd" 3
struct _ZSt15basic_streambufIcSt11char_traitsIcEE { const long *__vptr;
# 184 "/usr/include/c++/5/streambuf" 3
_ZNSt15basic_streambufIcSt11char_traitsIcEE9char_typeE *_M_in_beg;
# 185 "/usr/include/c++/5/streambuf" 3
_ZNSt15basic_streambufIcSt11char_traitsIcEE9char_typeE *_M_in_cur;
# 186 "/usr/include/c++/5/streambuf" 3
_ZNSt15basic_streambufIcSt11char_traitsIcEE9char_typeE *_M_in_end;
# 187 "/usr/include/c++/5/streambuf" 3
_ZNSt15basic_streambufIcSt11char_traitsIcEE9char_typeE *_M_out_beg;
# 188 "/usr/include/c++/5/streambuf" 3
_ZNSt15basic_streambufIcSt11char_traitsIcEE9char_typeE *_M_out_cur;
# 189 "/usr/include/c++/5/streambuf" 3
_ZNSt15basic_streambufIcSt11char_traitsIcEE9char_typeE *_M_out_end;
# 192 "/usr/include/c++/5/streambuf" 3
struct _ZSt6locale _M_buf_locale;};
# 44 "/usr/include/x86_64-linux-gnu/c++/5/bits/ctype_base.h" 3
typedef const int *_ZNSt10ctype_base9__to_typeE;
# 48 "/usr/include/x86_64-linux-gnu/c++/5/bits/ctype_base.h" 3
typedef unsigned short _ZNSt10ctype_base4maskE;
# 41 "/usr/include/x86_64-linux-gnu/c++/5/bits/ctype_base.h" 3
struct _ZSt10ctype_base {};
# 686 "/usr/include/c++/5/bits/locale_facets.h" 3
typedef char _ZNSt5ctypeIcE9char_typeE;
# 681 "/usr/include/c++/5/bits/locale_facets.h" 3
struct _ZSt5ctypeIcE { const long *__b_NSt6locale5facetE___vptr;
# 377 "/usr/include/c++/5/bits/locale_classes.h" 3
_Atomic_word __b_NSt6locale5facetE__M_refcount;
# 690 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZSt10__c_locale _M_c_locale_ctype;
# 691 "/usr/include/c++/5/bits/locale_facets.h" 3
__nv_bool _M_del;
# 692 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10ctype_base9__to_typeE _M_toupper;
# 693 "/usr/include/c++/5/bits/locale_facets.h" 3
_ZNSt10ctype_base9__to_typeE _M_tolower;
# 694 "/usr/include/c++/5/bits/locale_facets.h" 3
const _ZNSt10ctype_base4maskE *_M_table;
# 695 "/usr/include/c++/5/bits/locale_facets.h" 3
char _M_widen_ok;
# 696 "/usr/include/c++/5/bits/locale_facets.h" 3
char _M_widen[256];
# 697 "/usr/include/c++/5/bits/locale_facets.h" 3
char _M_narrow[256];
# 698 "/usr/include/c++/5/bits/locale_facets.h" 3
char _M_narrow_ok;char __nv_no_debug_dummy_end_padding_0[6];};
# 76 "/usr/include/c++/5/bits/basic_ios.h" 3
typedef char _ZNSt9basic_iosIcSt11char_traitsIcEE9char_typeE;
# 87 "/usr/include/c++/5/bits/basic_ios.h" 3
typedef struct _ZSt5ctypeIcE _ZNSt9basic_iosIcSt11char_traitsIcEE12__ctype_typeE;
# 89 "/usr/include/c++/5/bits/basic_ios.h" 3
typedef struct _ZSt7num_putIcSt19ostreambuf_iteratorIcSt11char_traitsIcEEE _ZNSt9basic_iosIcSt11char_traitsIcEE14__num_put_typeE;
# 91 "/usr/include/c++/5/bits/basic_ios.h" 3
typedef struct _ZSt7num_getIcSt19istreambuf_iteratorIcSt11char_traitsIcEEE _ZNSt9basic_iosIcSt11char_traitsIcEE14__num_get_typeE;
# 77 "/usr/include/c++/5/iosfwd" 3
struct _ZSt9basic_iosIcSt11char_traitsIcEE { struct _ZSt8ios_base __b_St8ios_base;
# 96 "/usr/include/c++/5/bits/basic_ios.h" 3
struct _ZSo *_M_tie;
# 97 "/usr/include/c++/5/bits/basic_ios.h" 3
_ZNSt9basic_iosIcSt11char_traitsIcEE9char_typeE _M_fill;
# 98 "/usr/include/c++/5/bits/basic_ios.h" 3
__nv_bool _M_fill_init;
# 99 "/usr/include/c++/5/bits/basic_ios.h" 3
struct _ZSt15basic_streambufIcSt11char_traitsIcEE *_M_streambuf;
# 102 "/usr/include/c++/5/bits/basic_ios.h" 3
const _ZNSt9basic_iosIcSt11char_traitsIcEE12__ctype_typeE *_M_ctype;
# 104 "/usr/include/c++/5/bits/basic_ios.h" 3
const _ZNSt9basic_iosIcSt11char_traitsIcEE14__num_put_typeE *_M_num_put;
# 106 "/usr/include/c++/5/bits/basic_ios.h" 3
const _ZNSt9basic_iosIcSt11char_traitsIcEE14__num_get_typeE *_M_num_get;};
# 62 "/usr/include/c++/5/ostream" 3
typedef char _ZNSo9char_typeE;
# 71 "/usr/include/c++/5/ostream" 3
typedef struct _ZSo _ZNSo14__ostream_typeE;
# 86 "/usr/include/c++/5/iosfwd" 3
struct _ZSo { const long *__vptr; struct _ZSt9basic_iosIcSt11char_traitsIcEE __v_St9basic_iosIcSt11char_traitsIcEE;};
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
# 342 "/usr/local/cuda/bin/..//include/crt/math_functions.h"
__device_builtin__ ___device__(extern __no_sc__) __attribute__((__nothrow__)) __attribute__((__const__)) float fmaxf(float, float);
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
# 5 "test.cu"
__global__ __var_used__ extern void _Z3addiPfS_(int, float *, float *);
#include "common_functions.h"
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
#if !defined(__CUDABE__)
#endif
# 5 "test.cu"
__global__ __var_used__ void _Z3addiPfS_(
# 5 "test.cu"
int n,
# 5 "test.cu"
float *x,
# 5 "test.cu"
float *y){
# 6 "test.cu"
{
# 7 "test.cu"
int __cuda_local_var_31489_7_non_const_index;
# 8 "test.cu"
int __cuda_local_var_31490_7_non_const_stride;
# 7 "test.cu"
__cuda_local_var_31489_7_non_const_index = ((int)(threadIdx.x));
# 8 "test.cu"
__cuda_local_var_31490_7_non_const_stride = ((int)(blockDim.x));
# 9 "test.cu"
{
# 9 "test.cu"
int i;
# 9 "test.cu"
i = 0;
# 9 "test.cu"
for (; (i < n); i++) {
# 10 "test.cu"
(y[i]) = ((x[i]) + (y[i])); } }
# 11 "test.cu"
}}
设备端代码,主要是各种会被用到的头文件和.cu文件,应该相当于和成新的代码。
test.cudafe1.stub.c
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "-Wunused-function"
#pragma GCC diagnostic ignored "-Wcast-qual"
#define __NV_CUBIN_HANDLE_STORAGE__ static
#include "crt/host_runtime.h"
#include "test.fatbin.c"
extern void __device_stub__Z3addiPfS_(int, float *, float *);
static void __nv_cudaEntityRegisterCallback(void **);
static void __sti____cudaRegisterAll(void) __attribute__((__constructor__));
void __device_stub__Z3addiPfS_(int __par0, float *__par1, float *__par2){__cudaSetupArgSimple(__par0, 0UL);__cudaSetupArgSimple(__par1, 8UL);__cudaSetupArgSimple(__par2, 16UL);__cudaLaunch(((char *)((void ( *)(int, float *, float *))add)));}
# 5 "test.cu"
void add( int __cuda_0,float *__cuda_1,float *__cuda_2)
# 6 "test.cu"
{__device_stub__Z3addiPfS_( __cuda_0,__cuda_1,__cuda_2);
}
# 1 "test.cudafe1.stub.c"
static void __nv_cudaEntityRegisterCallback( void **__T0) { __nv_dummy_param_ref(__T0); __nv_save_fatbinhandle_for_managed_rt(__T0); __cudaRegisterEntry(__T0, ((void ( *)(int, float *, float *))add), _Z3addiPfS_, (-1)); }
static void __sti____cudaRegisterAll(void) { __cudaRegisterBinary(__nv_cudaEntityRegisterCallback); }
#pragma GCC diagnostic pop
gcc中声明的全局函数
test.module_id
_12_test_cpp1_ii_b0a118f9
test.ptx
//
// Generated by NVIDIA NVVM Compiler
//
// Compiler Build ID: CL-22781540
// Cuda compilation tools, release 9.0, V9.0.176
// Based on LLVM 3.4svn
//
.version 6.0
.target sm_30
.address_size 64
// .globl _Z3addiPfS_
.visible .entry _Z3addiPfS_(
.param .u32 _Z3addiPfS__param_0,
.param .u64 _Z3addiPfS__param_1,
.param .u64 _Z3addiPfS__param_2
)
{
.reg .pred %p<7>;
.reg .f32 %f<22>;
.reg .b32 %r<18>;
.reg .b64 %rd<17>;
ld.param.u32 %r8, [_Z3addiPfS__param_0];
ld.param.u64 %rd6, [_Z3addiPfS__param_1];
ld.param.u64 %rd7, [_Z3addiPfS__param_2];
cvta.to.global.u64 %rd1, %rd7;
cvta.to.global.u64 %rd2, %rd6;
setp.lt.s32 %p1, %r8, 1;
@%p1 bra BB0_10;
and.b32 %r12, %r8, 3;
mov.u32 %r14, 0;
setp.eq.s32 %p2, %r12, 0;
@%p2 bra BB0_7;
setp.eq.s32 %p3, %r12, 1;
@%p3 bra BB0_6;
setp.eq.s32 %p4, %r12, 2;
@%p4 bra BB0_5;
ld.global.f32 %f1, [%rd2];
ld.global.f32 %f2, [%rd1];
add.f32 %f3, %f1, %f2;
st.global.f32 [%rd1], %f3;
mov.u32 %r14, 1;
BB0_5:
mul.wide.u32 %rd8, %r14, 4;
add.s64 %rd9, %rd2, %rd8;
add.s64 %rd10, %rd1, %rd8;
ld.global.f32 %f4, [%rd10];
ld.global.f32 %f5, [%rd9];
add.f32 %f6, %f5, %f4;
st.global.f32 [%rd10], %f6;
add.s32 %r14, %r14, 1;
BB0_6:
mul.wide.s32 %rd11, %r14, 4;
add.s64 %rd12, %rd2, %rd11;
add.s64 %rd13, %rd1, %rd11;
ld.global.f32 %f7, [%rd13];
ld.global.f32 %f8, [%rd12];
add.f32 %f9, %f8, %f7;
st.global.f32 [%rd13], %f9;
add.s32 %r14, %r14, 1;
BB0_7:
setp.lt.u32 %p5, %r8, 4;
@%p5 bra BB0_10;
mul.wide.s32 %rd16, %r14, 4;
BB0_9:
add.s64 %rd14, %rd2, %rd16;
add.s64 %rd15, %rd1, %rd16;
ld.global.f32 %f10, [%rd15];
ld.global.f32 %f11, [%rd14];
add.f32 %f12, %f11, %f10;
ld.global.f32 %f13, [%rd15+4];
ld.global.f32 %f14, [%rd15+8];
ld.global.f32 %f15, [%rd15+12];
st.global.f32 [%rd15], %f12;
ld.global.f32 %f16, [%rd14+4];
add.f32 %f17, %f16, %f13;
st.global.f32 [%rd15+4], %f17;
ld.global.f32 %f18, [%rd14+8];
add.f32 %f19, %f18, %f14;
st.global.f32 [%rd15+8], %f19;
ld.global.f32 %f20, [%rd14+12];
add.f32 %f21, %f20, %f15;
st.global.f32 [%rd15+12], %f21;
add.s64 %rd16, %rd16, 16;
add.s32 %r14, %r14, 4;
setp.lt.s32 %p6, %r14, %r8;
@%p6 bra BB0_9;
BB0_10:
ret;
}
这个是设备端的主要汇编语言,应该是直接生成对应的显卡机器码。
3. 产生test.sm_30.cubin二进制文件
ptxas -arch=sm_30 -m64 "test.ptx" -o "test.sm_30.cubin" 产生test.sm_30.cubin二进制文件。
4.重新生成二进制文件
fatbinary --create="test.fatbin" -64 "--image=profile=sm_30,file=test.sm_30.cubin" "--image=profile=compute_30,file=test.ptx" --embedded-fatbin="test.fatbin.c" --cuda
这里主要生成了一个test.fatbin二进制文件和test.fatbin.c文件,主要应该是对前面的汇编码,进行了一次封装和函数指针的对齐,主要是统一host和device的函数调用地址。
test.fatbin.c
#ifndef __SKIP_INTERNAL_FATBINARY_HEADERS
#include "fatBinaryCtl.h"
#endif
#define __CUDAFATBINSECTION ".nvFatBinSegment"
#define __CUDAFATBINDATASECTION ".nv_fatbin"
asm(
".section .nv_fatbin, \"a\"\n"
".align 8\n"
"fatbinData:\n"
".quad 0x00100001ba55ed50,0x0000000000000d10,0x0000004001010002,0x0000000000000928\n"
".quad 0x0000000000000000,0x0000001e00010007,0x0000000000000000,0x0000000000000015\n"
".quad 0x0000000000000000,0x0000000000000000,0x33010102464c457f,0x0000000000000007\n"
".quad 0x0000005a00be0002,0x0000000000000000,0x0000000000000880,0x0000000000000680\n"
".quad 0x00380040001e051e,0x0001000800400003,0x7472747368732e00,0x747274732e006261\n"
".quad 0x746d79732e006261,0x746d79732e006261,0x78646e68735f6261,0x666e692e766e2e00\n"
".quad 0x2e747865742e006f,0x5069646461335a5f,0x2e766e2e005f5366,0x335a5f2e6f666e69\n"
".quad 0x5f53665069646461,0x6168732e766e2e00,0x61335a5f2e646572,0x005f536650696464\n"
".quad 0x736e6f632e766e2e,0x5a5f2e30746e6174,0x5366506964646133,0x747368732e00005f\n"
".quad 0x74732e0062617472,0x79732e0062617472,0x79732e006261746d,0x6e68735f6261746d\n"
".quad 0x692e766e2e007864,0x61335a5f006f666e,0x005f536650696464,0x5a5f2e747865742e\n"
".quad 0x5366506964646133,0x6e692e766e2e005f,0x6461335a5f2e6f66,0x2e005f5366506964\n"
".quad 0x65726168732e766e,0x646461335a5f2e64,0x6e2e005f53665069,0x6174736e6f632e76\n"
".quad 0x61335a5f2e30746e,0x005f536650696464,0x00006d617261705f,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x000700030000003e,0x0000000000000000\n"
".quad 0x0000000000000000,0x000600030000007c,0x0000000000000000,0x0000000000000000\n"
".quad 0x0007101200000032,0x0000000000000000,0x00000000000002c0,0x0000000300082304\n"
".quad 0x0008120400000000,0x0000000000000003,0x0000000300081104,0x00080a0400000000\n"
".quad 0x0018014000000002,0x000c170400181903,0x0010000200000000,0x000c17040021f000\n"
".quad 0x0008000100000000,0x000c17040021f000,0x0000000000000000,0x003f1b030011f000\n"
".quad 0x00000020000c1c04,0x0000029800000198,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x22c28042f2c28307,0x2800400110005de4\n"
".quad 0x2800400500009de4,0x188ec0000421dc23,0x80000000000001e7,0x380000000c209c02\n"
".quad 0x28000000fc001de4,0x190e0000fc21dc23,0x220202c042f2c2f7,0x40000004c00001e7\n"
".quad 0x190ec0000421dc23,0x40000003200001e7,0x190ec0000821dc23,0x1800000010025de2\n"
".quad 0x280040052000a1e4,0x280040053000e1e4,0x2202c04280427047,0x28004005400121e4\n"
".quad 0x28004005500161e4,0x840000000020a085,0x18000000040021e2,0x840000000041a085\n"
".quad 0x4001400520021c43,0x209280053001dc43,0x22d2004283f042c7,0x400140054002dc43\n"
".quad 0x2092800550025c43,0x0800000004001c02,0x500000001822a000,0x2800000020019de4\n"
".quad 0x940000000042a085,0x280000002c021de4,0x2282c042f283f237,0x8400000000619c85\n"
".quad 0x8400000000809c85,0x500000001820dc00,0x940000000080dc85,0x4001400520009c43\n"
".quad 0x1800000010015de2,0x208a80053000dce3,0x22f283f28042c047,0x4001400540011c43\n"
".quad 0x8400000000209c85,0x208a800550015ce3,0x0800000004001c02,0x8400000000419c85\n"
".quad 0x500000000861dc00,0x940000000041dc85,0x22c042f202e2c287,0x1800000010009de2\n"
".quad 0x1a0e40050021dc03,0x80000000000001e7,0x6000c00008031c03,0x1000000010035ce2\n"
".quad 0x4801400520c11c03,0x0800000010001c02,0x22328042c0428047,0x4800400530d15c43\n"
".quad 0x188e40050001dc23,0x4801400540c09c03,0x840000000041dc85,0x4800400550d0dc43\n"
".quad 0x0c00000040c31c02,0x8400000000219c85,0x2283f232e283f047,0x8400000010221c85\n"
".quad 0x4800000037f35c43,0x500000001c619c00,0x9400000000219c85,0x8400000010425c85\n"
".quad 0x840000002021dc85,0x5000000024825c00,0x2283f2e283f232e7,0x9400000010225c85\n"
".quad 0x8400000020429c85,0x8400000030221c85,0x500000002871dc00,0x940000002021dc85\n"
".quad 0x840000003042dc85,0x500000002c82dc00,0x2000000002f2e047,0x940000003022dc85\n"
".quad 0x4003fffc600001e7,0x8000000000001de7,0x4003ffffe0001de7,0x4000000000001de4\n"
".quad 0x4000000000001de4,0x4000000000001de4,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000300000001,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000040,0x000000000000008a,0x0000000000000000\n"
".quad 0x0000000000000001,0x0000000000000000,0x000000030000000b,0x0000000000000000\n"
".quad 0x0000000000000000,0x00000000000000ca,0x000000000000009d,0x0000000000000000\n"
".quad 0x0000000000000001,0x0000000000000000,0x0000000200000013,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000168,0x0000000000000060,0x0000000200000002\n"
".quad 0x0000000000000008,0x0000000000000018,0x7000000000000029,0x0000000000000000\n"
".quad 0x0000000000000000,0x00000000000001c8,0x0000000000000024,0x0000000000000003\n"
".quad 0x0000000000000004,0x0000000000000000,0x7000000000000044,0x0000000000000000\n"
".quad 0x0000000000000000,0x00000000000001ec,0x0000000000000054,0x0000000700000003\n"
".quad 0x0000000000000004,0x0000000000000000,0x0000000100000070,0x0000000000000002\n"
".quad 0x0000000000000000,0x0000000000000240,0x0000000000000158,0x0000000700000000\n"
".quad 0x0000000000000004,0x0000000000000000,0x0000000100000032,0x0000000000000006\n"
".quad 0x0000000000000000,0x00000000000003c0,0x00000000000002c0,0x0e00000300000003\n"
".quad 0x0000000000000040,0x0000000000000000,0x0000000500000006,0x0000000000000880\n"
".quad 0x0000000000000000,0x0000000000000000,0x00000000000000a8,0x00000000000000a8\n"
".quad 0x0000000000000008,0x0000000500000001,0x0000000000000240,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000418,0x0000000000000418,0x0000000000000008\n"
".quad 0x0000000600000001,0x0000000000000000,0x0000000000000000,0x0000000000000000\n"
".quad 0x0000000000000000,0x0000000000000000,0x0000000000000008,0x0000004801010001\n"
".quad 0x0000000000000360,0x000000400000035d,0x0000001e00060000,0x0000000000000000\n"
".quad 0x0000000000002015,0x0000000000000000,0x000000000000079d,0x0000000000000000\n"
".quad 0x762e1cf200010a13,0x36206e6f69737265,0x677261742e0a302e,0x30335f6d73207465\n"
".quad 0x7365726464612e0a,0x3620657a69735f73,0x69736917f8002f34,0x746e652e20656c62\n"
".quad 0x6461335a5f207972,0x0a285f5366506964,0x2e206d617261702e,0x175f110019323375\n"
".quad 0x2f00212c305f3600,0x21311f0000213436,0x0a290a3208f30d00,0x2e206765722e0a7b\n"
".quad 0x3c70252064657270,0x33669500123b3e37,0x1232323c66252032,0x3c72460012621000\n"
".quad 0x2034368000123831,0x420037313c647225,0xb2010071646c0a0a,0x5b202c3872256f00\n"
".quad 0x00293b5d270000b8,0x02002a361f004102,0x2a371f00002a311f,0x0a3b5d3203f40200\n"
".quad 0x2e6f742e61747663,0x00306c61626f6c67,0x001f0f00362c3121,0x3604f2001f321105\n"
".quad 0x6c2e707465730a3b,0x7025093233732e74,0x3b3109f300bf2c31,0x726220317025400a\n"
".quad 0x30315f3042422061,0x010b646e610a0a3b,0x3b33630028323123,0x315300f7766f6d0a\n"
".quad 0x6523005230202c34,0x00302c3223005271,0x0053321500533011,0x3314002b0a3b373b\n"
".quad 0x2b3315007e02002b,0x2b3414002b361d00,0x2b3415002b321100,0xed03018e3b352100\n"
".quad 0x202c314001cb0200,0x001b3b5d2d00f35b,0x33017100001b3212,0x2c33220015646461\n"
".quad 0x0a3b326625780035,0x00002d0200327473,0x3b314100fa0d001b,0x6d0a3aa300820a0a\n"
".quad 0x1e656469772e6c75,0x1200242c38643300,0x2601847312006734,0x001a3819018a2c39\n"
".quad 0x381e01c42c303136,0x301f00b7341300b7,0x19001c35120000d3,0x001a2c362200d339\n"
".quad 0x110200d33466253f,0x050085361300d430,0xda361700da0a00d4,0x3131643f00240200\n"
".quad 0x00dc3231270300db,0xdd3317001c31312a,0x371300c231312e00,0x130000de331f00de\n"
".quad 0x2200df3219001c38,0x3766253f001b2c39,0x1f00df33110200df,0x0d3a37250b00df39\n"
".quad 0xe535130265751103,0x0d351a0264341102,0x010a3617010a0d03,0x00f63a3929005001\n"
".quad 0x0112361a01123418,0x00f6361e01123518,0x13351f00f7303123,0x19001d3131230001\n"
".quad 0x1d01018301011434,0x0000370f00400000,0x56342b2f00543314,0x381f001f34150100\n"
".quad 0x01001f351501001f,0x35110001750f018c,0x00003d32312f0175,0x00b42b1b00b23614\n"
".quad 0x00a000001f2c3723,0x58342b220300560f,0x3815000058371f00,0x39230058381a0058\n"
".quad 0x580f00d900001f2c,0x391f005838120400,0x0b00583015000426,0x00202c3132330279\n"
".quad 0x210400590f011300,0x0307321b005a3231,0x79311f00072c3624,0x6405059f341c0403\n"
".quad 0x1502953872253102,0xd002763913029536,0x3b7465720a3a3031,0x0000000a0a0a7d0a\n"
".text\n");
#ifdef __cplusplus
extern "C" {
#endif
extern const unsigned long long fatbinData[420];
#ifdef __cplusplus
}
#endif
#ifdef __cplusplus
extern "C" {
#endif
static const __fatBinC_Wrapper_t __fatDeviceText __attribute__ ((aligned (8))) __attribute__ ((section (__CUDAFATBINSECTION)))=
{ 0x466243b1, 1, fatbinData, 0 };
#ifdef __cplusplus
}
#endif
5. gcc生成host代码
gcc -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -include "cuda_runtime.h" -m64 "test.cu" > "test.cpp4.ii"
生成test.cpp4.ii内容非常多基本就是将标准库展开,所有的.h文件代码嵌入文件中。主要内容是stl标准库中的代码+原来的main函数代码。这里主要是生成主机端执行的代码和普通的c++没有什么太大的区别
6. cudafe++ 生成test.cudafe1.cpp
cudafe++ --gnu_version=50400 --allow_managed --m64 --parse_templates --gen_c_file_name "test.cudafe1.cpp" --stub_file_name "test.cudafe1.stub.c" --module_id_file_name "test.module_id" "test.cpp4.ii"
主要生成了test.cudafe1.cpp文件.
文件主要包含引用include的内容,test.cudafe1.stub.c和.cu中源文件的内容,基本就是进行了再一次的拓展,主要目的应该是合并host和device接口的代码。
7. 生成目标中间文件
gcc -D__CUDA_ARCH__=300 -c -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS "-I/usr/local/cuda/bin/..//include" -m64 -o "test.o" "test.cudafe1.cpp"
主要是用上一步的test.cudafe1.cpp生成对应的.o中间文件。应该主要还是在host主机上运行
8. 链接内容
nvlink --arch=sm_30 --register-link-binaries="add_cuda_dlink.reg.c" -m64 "-L/usr/local/cuda/bin/..//lib64/stubs" "-L/usr/local/cuda/bin/..//lib64" -cpu-arch=X86_64 "test.o" -o "add_cuda_dlink.sm_30.cubin"
使用这个链接命令生成了对应的.cubin二进制文件和add_cuda_dlink.reg.c文件 add_cuda_dlink.reg.c只有这一个内容
#define NUM_PRELINKED_OBJECTS 0
9. 筛选和重新生成二进制文件
fatbinary --create="add_cuda_dlink.fatbin" -64 -link "--image=profile=sm_30,file=add_cuda_dlink.sm_30.cubin" --embedded-fatbin="add_cuda_dlink.fatbin.c"
主要生成了add_cuda_dlink.fatbin.c和add_cuda_dlink.fatbin二进制文件。
add_cuda_dlink.fatbin.c的内容和test.fatbin.c的内容基本一致。就是将test.fatbin中的静态代码重新进行添加,因为编译的参数可能会使用不同的sm和code在这里要进行筛选。本次代码因为没有加其它编译参数,因此相同
10. 编译生成中间文件
gcc -c -x c++ -DFATBINFILE="\"add_cuda_dlink.fatbin.c\"" -DREGISTERLINKBINARYFILE="\"add_cuda_dlink.reg.c\"" -I. "-I/usr/local/cuda/bin/..//include" -D"__CUDACC_VER_BUILD__=176" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=9" -m64 -o "add_cuda_dlink.o" "/usr/local/cuda/bin/crt/link.stub"
生成add_cuda_dlink.o最后中间文件,其实估计中间文件应该和test.fatbin内容差不多,或者说test.fatbin是它的一部分。
- 链接生成最终可执行文件
g++ -m64 -o "add_cuda" -Wl,--start-group "add_cuda_dlink.o" "test.o" "-L/usr/local/cuda/bin/..//lib64/stubs" "-L/usr/local/cuda/bin/..//lib64" -lcudadevrt -lcudart_static -lrt -lpthread -ldl -Wl,--end-group
链接add_cuda_dlink.o和test.o最终生成对应的add_cuda,对齐代码和可执行函数接口
总结
整个流程给我的感觉是,其实设备使用的代码就是.ptx。不过因为NVCC提供的虚拟架构方式,会生成好几份不同的代码和对应的二进制文件,并且生成对应的函数调用头文件,有点像普通的C++ 动态链接库和头文件分离。头文件中包含函数地址。
后面在在主机端生成代码,只是将cuda部分的函数声明了而已。
最后使用nvlink其实关键并不在于链接过程中的函数地址对齐,而是对生成的好几份设备端的机器代码和接口进行合适的筛选测试。生成新的静态二进制文件。很有可能就是将前面的二进制文件直接拼接过来。而add_cuda_dlink.fatbin.c其实是对应函数映射地址的接口,更类似于一个.h的头文件
然后c++编译器将add_cuda_dlink.fatbin.c装入,使用add_cuda_dlink.reg.c应该是其它的一些关键字,当存在多个版本的设备二进制可执行文件时,用来声明执行。帮助生成二进制.obj
最后再有主机链接器(gcc)进行动态和静态链接库的链接。本次代码因为是机器码直接装入,因此不会有cuda的动态链接。
从上面可以看出,cuda真的是比较喜欢静态链接。也知道cudnn为什么函数这么少,so的动态链接库这么大了,应该是将 多个硬件版本的机器码直接放进去了。
总体而言,nvcc更像是qmake进行相关makefile和预处理代码的生成,调用gcc生成host二进制文件,调用cicc、ptxas、fatbinary分别生成汇编代码、机器码、静态代码。最后使用nvlink链接生成.obj文件,使用gcc link生成最终的可执行文件。